Danke Dir Günther. Mehr ausgeben muss nicht sein - ich weiß ehrliuch gesagt selbst noch nicht, was ich will und brauche 🙃
Mir ist im großen und ganzen klar, was die unterschiedlichen Typen "Caching" machen - mir ist aber noch nicht klar, was bei mir das sinnvollste wäre. Vielleicht kannst Du mich auch in die richtige Richtung lenken?
Wichtig wäre mir vor allem um die Beschleunigung des Pools HDD01 im daily use, aber ich würde das aktuelle Setup meines Haupt-Servers trotzdem vorab einigermaßen schildern, vielleicht denke ich auch in die falsche Richtung. Server ist ein HPE ML350p gen8 mit zwei Xeons, 192GB RAM und Platz im Überfluss (denke acht oder zehn PCIe von x1 bis x16 Steckplätze, von denen bisher nur einer für eine Mellanox Karte belegt ist, die per DAC am Switch hängt).
An Käfigen sind aktuell ein 4x 2,5" an einem P420i, sowie ein 8x 2,5" und ein 6x 3,5" an je einem HBA H220. Platz wäre noch für ein 8x2,5 oder 6x3,5 - beide Cases vorhanden, aber HBA fehlt noch. Denke aber nicht, dass ich das aktuell brauche.
Server hängt mit einem Bein an einer USV, mit dem anderen Bein am normalen Stromnetz.
Hypervisor ist primär ein ESXi 7, läuft auf dem P420i Controller mit zwei einfachen 128GB SSDs im RAID1. Zusätzlich liegen auf diesem internen Datastore paar ganz elementare VMs ohne viel IO (Storage, primärer DC auf WS2019Core, USV, Backup). Platz ist damit auch ziemlich am Limit (85%).
Die Storage VM hat aktuell 64GB RAM
Auf der Storage VM laufen drei primäre Pools (HDD01, SAS01 und SSD01):
Auf den beiden SSD01 (2x Crucial MX500 500GB im Mirror) und SAS01 (5x HPE 1TB SAS im RaidZ2) laufen hauptsächlich VMs und deren Arbeitsdaten (steigt noch, z.B. soll auf den SAS01 noch der SCCM mit Datenbank und WSUS Daten - 5TB bräuchte ich da aber nicht). Den SAS01 Pool habe ich vor allem in der Größe, weil die 1TB SAS Platten eh da sind. Aktuell primär für unwichtigere VMs genutzt.
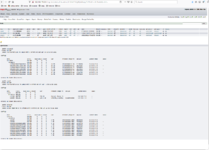
Der HDD01 Pool ist etwas mein Sorgenkind. Eigentlich der wichtigste Pool, weil dort alle Nutzdaten liegen. Vom Dokumentenmangementsystem über Homemedia bis zum Filmarchiv. Aufgeteilt in drei ZFS Dateisysteme, um die unterschiedlichen Backup-Zyklen und Aufbewahrungswünsche besser steuern zu können. Bisher sind dort 2x 8TB Red verbaut, eine dritte steckt im obigen Screenshot gerade drin und wird wechselweise mit einer anderen extern verwahrt. Eine Red des 8TB Mirrors meldet nun moderate SMART Fehler und nachdem beide auf die fünf Jahre zugehen, habe ich mir zwei WDC/HGST Ultrastar DC HC530 14TB besorgt. Diese habe ich die letzten Tage gründlich durchgetestet und sehen in Ordnung aus.
Allerdings ist bei beiden die Schreibperformance erwartungsgemäß wieder recht mau:
Meine Frage ist nun konkret: wie helfe ich den beiden am besten auf die Sprünge? Wird in Summe wahrscheinlich etwas besser sein, als bei den 8TB Red, aber nichtmal GBit kann man damit auslasten. Ich habe keinen speziellen Usecase - eben daily use. Besonders auf den Senkel geht mir der HDD01 Pool, wenn ich vom Rechner etwas auf die Freigabe verschiebe. Sei es eine einzelne ISO mit paar GB oder eine SD-Karte der Spiegelreflex ausleere (viele Dateien, á 8-20MB). Lesend ist es ähnlich, aber nachdem die zu lesenden Daten wirklich ständig wechseln, würde ich das mal ausklammern, da nicht wirklich behebbar und ja eh spürbar schneller.
Meine Gedanken sind nun (wobei ich das gerne völlig ergebnisoffen halten würde):
- Nehme ich nun eine Optane als Slog her, dass ich flott wegkopieren kann? Bei 64GB RAM, von dem aktuell ca. 50GB für ZFS genutzt werden, kann ich auch nur maximal 50GB hierfür auslasten?
- Ich kopiere im daily-use (ohne Migrationen etc.) sicher nie mehr als 20-30GB auf einmal auf den Server.
- Obwohl ich mit der Performance meiner VMs zufrieden bin, widerstrebt es mir ein Stück weit, "schweineteure" Optane für reine Nutzdaten herzunehmen und die VMs laufen auf den MX500 SSDs
- 100GB sind nicht viel, aber was mache ich mit dem Rest, wenn ich es als Slog für HDD01 nutze?
- macht ein Special Vdev mehr Sinn? Habe ich da granular Einfluss, was auf welchem vdev liegt? Kann ich sogar mehr vdevs nutzen und die Verteilung on-demand ändern? Wilder Mix aus HDD, SAS und SSD?
- oder KISS? Je mehr vdevs im Pool, desto komplexer und im Fehlerfall aufwendiger wiederherzustellen
- je weniger ich ausgeben muss, desto besser - ich habe aktuell keine wirkliche Handlungsnot und nach den beiden 14TB Platten würde ich mein Spiellimit mal ungefähr bei 450€ ansetzen (2x P4800X U.2 100GB á 180€ + 2x PCIe Adapter á 50€).
Viele Grüße
Martin
Nachtrag wg. 3-way Mirror: den würde ich ausschließen, mein 2-way ist ausschließlich Redundanz und wenn ich paar Tage brauche, bis ich wieder am Schließfach war oder meine Daten von Glacier geholt habe, dann ist das nicht schön und mit Arbeit verbunden, aber die Welt geht davon nicht unter.








") Schönen Sonntag noch!
Schönen Sonntag noch!