Wie beschrieben liegen die VMs all auf dem "VMstorage" Pool. SAS15k war nur für Experimente (vor dem Kauf der 'richtigen' Platten) da.
Ich bin auch kein wirklicher Freund von synthetischen Benchmarks und habe das hier nur aus folgenden Gründen gemacht:
1. Das System kommt mir (viel) zu langsam vor (Installationszeit von Win7 war irgendwie erheblich länger als ich es von einem normalen Desktopsystem mit einfacher HDD gewohnt bin).
2. Ich wollte was haben, was ich mit den Ergebnissen anderer All-in-one Nutzer (oder meinen eigenen) vergleichen kann.
Bei den Benchmarks habe ich die Tests immer mindestens drei Mal durchlaufen lassen und immer Werte bekommen, die nicht mehr als 20% Abweichung aufzeigen.
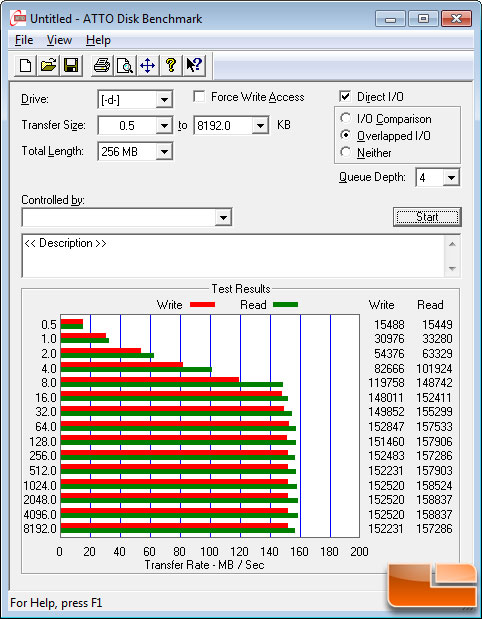
Ich habe auf dem All-In-One System dann mal vergleichsweise Windows XP installiert, und während die Datenraten fürs Lesen grosser Blöcke (512k) oder sequentielles Lesen recht gut aussehen, sind die Werte für 4k als auch die Schreibwerte im allgemeinen Mist:

Dies ist mein erster Versuch, ein Datensystem "aufs Netzwerk auszulagern", vielleicht ist das einfach so?
Ich habe noch zwei andere Server für VMs, beide allerdings mit lokalem Datenspeicher, also nicht übers (virtuelle) Netzwerk angebunden und da sehen die Benchmarkwerte deutlich besser aus (und zumindest bei System 1 ist die Festplattenperformance innerhalb der VMs klar erkennbar):
System #1 
ESXi 4.0 auf X8SIL-F mit XEON 3460, 2x 4GB regECC
LSI 84016E (mit Backupbatterie): 4x WD Raptor 150GB im RAID10
System #2
VMware Server 2.0.x auf CentOS 5.3

Tyan Tempest XT5000i mit 2x XEON 5420, 8x 2GB FB-RAM (ECC)
Promise SuperTrak EX12350 (mit Backupbatterie): 5x WD Raptor 300GB im RAID10 + Hotspare
Dies ist übrigens das System, welches durch den neuen All-in-One Server ersetzt werden soll.
In beiden Fällen sind die Schreibraten wesentlich besser als bei meinem All-in-One System. Wenn diese geringen Schreibraten nicht ein prinzipbedingtes Problem beim SAN sind, muss da doch bei meiner Konfig irgendwas im Argen liegen.
Was für CrystalMark-Werte bekommt ihr so mit einem All-In-One Server (damit ich mal einen Vergleich habe)?
-TLB

")




") Mein Fazit: Der Atto Bechmark oder auch der Crystal Bechmark ergeben wirklich eher bescheidene Werte. Wobei das bei diversen Messungen auch unterschiedlich war/ist. Mal sind die Werte ok (Schreibraten von max, 150 MB/S) und dann wieder nicht (Schreibrate von max 50 MB/S) ohne das ich genau weiss was sich geändert hat.
Mein Fazit: Der Atto Bechmark oder auch der Crystal Bechmark ergeben wirklich eher bescheidene Werte. Wobei das bei diversen Messungen auch unterschiedlich war/ist. Mal sind die Werte ok (Schreibraten von max, 150 MB/S) und dann wieder nicht (Schreibrate von max 50 MB/S) ohne das ich genau weiss was sich geändert hat. 














") ).
).