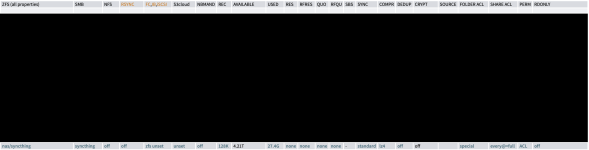
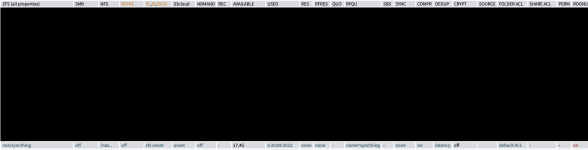
random-write: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=posixaio, iodepth=1
fio-3.36
Starting 1 process
random-write: Laying out IO file (1 file / 4096MiB)
Jobs: 1 (f=1): [w(1)][100.0%][w=56.0MiB/s][w=14.3k IOPS][eta 00m:00s]
random-write: (groupid=0, jobs=1): err= 0: pid=7917: Fri Jun 7 21:00:15 2024
write: IOPS=14.8k, BW=57.9MiB/s (60.7MB/s)(3484MiB/60181msec); 0 zone resets
slat (nsec): min=389, max=5553.5k, avg=2619.91, stdev=16475.75
clat (nsec): min=361, max=23951k, avg=63079.08, stdev=127597.44
lat (usec): min=10, max=23954, avg=65.70, stdev=129.98
clat percentiles (usec):
| 1.00th=[ 13], 5.00th=[ 19], 10.00th=[ 20], 20.00th=[ 39],
| 30.00th=[ 43], 40.00th=[ 47], 50.00th=[ 49], 60.00th=[ 52],
| 70.00th=[ 57], 80.00th=[ 62], 90.00th=[ 90], 95.00th=[ 139],
| 99.00th=[ 347], 99.50th=[ 529], 99.90th=[ 1336], 99.95th=[ 2212],
| 99.99th=[ 4555]
bw ( KiB/s): min=41568, max=86112, per=100.00%, avg=59502.61, stdev=9062.30, samples=119
iops : min=10392, max=21528, avg=14875.61, stdev=2265.57, samples=119
lat (nsec) : 500=0.01%, 750=0.01%, 1000=0.01%
lat (usec) : 2=0.01%, 4=0.01%, 10=0.01%, 20=10.52%, 50=43.54%
lat (usec) : 100=37.45%, 250=6.75%, 500=1.14%, 750=0.32%, 1000=0.08%
lat (msec) : 2=0.11%, 4=0.04%, 10=0.01%, 20=0.01%, 50=0.01%
cpu : usr=7.29%, sys=7.65%, ctx=908956, majf=0, minf=24
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,891952,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=57.9MiB/s (60.7MB/s), 57.9MiB/s-57.9MiB/s (60.7MB/s-60.7MB/s), io=3484MiB (3653MB), run=60181-60181msec