
Werbung
Zur CES stellte NVIDIA die ersten vier Modelle der GeForce-RTX-50-Serie auf Basis der Blackwell-GPU vor. Einige wenige Details gab es im Rahmen der Keynote, kurz darauf gingen die Produktseiten online, sodass wir die technischen Spezifikationen im Grunde bereits kennen. Auf einem Editors Day sprach NVIDIA aber etwas genauer über die verwendeten Technologien und nannte weitere Details, wie diese im Zusammenhang mit der Blackwell-Architektur stehen.
Zunächst einmal sieht NVIDIA mit der GeForce-RTX-50-Serie bzw. der Blackwell-GPU einen fundamentalen Wechsel in der Rendering-Technologie. Die ersten Schritte machte man in der Vergangenheit mit den bisherigen RTX-Generationen. Mit Blackwell soll dieser Weg in gewisser Weise vollendet werden.
Alles begann mit den GeForce programmable Shadern, ging in die High Level Shading Language (HLSL) über und erst dann entwickelten sich mit den Geometry Shadern für DirectX 10 gewisse Standards, die für alle Hersteller galten. Die Weiterentwicklungen in Form der Compute Shader in DirectX 11 und das Low Level Programming in DirectX 12 waren stetige Weiterentwicklungen.
Mit der ersten GeForce-RTX-Generation kam dann das Raytracing hinzu, welches keine neue Technik war, die nun aber mit einigen Tricks in einem für die Hardware überschaubaren Aufwand in Echtzeit berechnet werden konnte. Dass nur einzelne Effekte wie Reflexionen und die Beleuchtung oder der Schattenwurf darauf zurückgreifen und dies auch nur für einen oder zwei Bounces, das steht dabei zunächst einmal auf einem anderen Blatt. Auch die KI-gestützte Upscaling-Technik DLSS trug dazu bei, dass die aufwendigen Raytracing-Effekte überhaupt umgesetzt werden konnten. Auch die Frame-Generation-Technik ist einerseits ein Vehikel das aufwendige Raytracing zu unterstützen und auf der anderen Seite womöglich unausweichlich der Weg, den Spiele gehen werden.






Mit der Blackwell-Architektur arbeiten die Shadereinheiten und Tensor-Kerne nun enger zusammen. Auch im Aufbau der Streaming-Multiprozessoren gibt es Änderungen. Dazu kommen wir gleich. Die Änderungen fasst NVIDIA als Blackwell Neural Rendering Architektur zusammen.
| GeForce RTX 5090 | GeForce RTX 5080 | GeForce RTX 5070 Ti | GeForce RTX 5070 | |
| GPU | GB202-300-A1 | GB203-400-A1 | GB203-300 | GB205-300 |
| Architektur | Blackwell | Blackwell | Blackwell | Blackwell |
| SMs | 170 | 84 | 70 | 48 |
| FP32-ALUs | 21.760 | 10.752 | 8.960 | 6.144 |
| Basis-Takt | 2.010 MHz | 2.300 MHz | 2.300 MHz | 2.160 MHz |
| Boost-Takt | 2.410 MHz | 2.620 MHz | 2.450 MHz | 2.510 MHz |
| L1-Cache | 21.760 kB | 10.752 kB | 8.960 kB | 6.144 kB |
| L2 Cache | 96 MB | 64 MB | 48 MB | 48 MB |
| Speicherinterface | 512 Bit | 256 Bit | 256 Bit | 192 Bit |
| Speicher | GDDR7 (28 Gbps) | GDDR7 (30 Gbps) | GDDR7 (28 Gbps) | GDDR7 (28 Gbps) |
| Speicherkapazität | 32 GB | 16 GB | 16 GB | 12 GB |
| Speicherbandbreite | 1.792 GB/s | 960 GB/s | 896 GB/s | 672 GB/s |
| TGP | 575 W | 360 W | 300 W | 250 W |
| Preis | 2.329 Euro | 1.169 Euro | 879 Euro | 649 Euro |
NVIDIA lässt die GPUs der Blackwell-Karten bei TSMC in 4N fertigen. Dabei handelt es sich um einen angepassten 4-nm-Prozess, den TSMC nach außen hin als N4 bezeichnet. Damit werden die Blackwell-GPUs in der gleichen Strukturbreite wie die GeForce-RTX-40-Serie gefertigt. Der Schritte zu TSMC N3 war wohl aus technischer und/oder wirtschaftlicher Sicht nicht möglich.
| GB202 | AD102 | GB203 | AD103 | GB205 | AD104 | |
| Die-Größe | 750 mm² | 608,3 mm² | 378 mm² | 378,6 mm² | 263 mm² | 294,5 mm² |
| Anzahl der Transistoren | 92,2 Milliarden | 76 Milliarden | 45,6 Milliarden | 45,9 Milliarden | 31,1 Milliarden | 35,8 Milliarden |
| Transistordichte | 122,9 MTr/mm² | 124,9 MTr/mm² | 120,6 MTr/mm² | 121,2 MTr/mm² | 118,3 MTr/mm² | 121,6 MTr/mm² |
Im Vergleich zu den Ada-Lovelace-GPUs wächst vor allem die GB202-GPU deutlich in der Komplexität an. Auf 750 mm² und 92,2 Milliarden Transistoren kommt das neue Flaggschiff. Die GB203- ist im Vergleich zur AD103-GPU fast identisch in diesen Metriken. Die GB205-GPU ist im Vergleich zur AD104-GPU etwas kleiner und weniger komplex. Aufgrund der Nutzung des N4-Prozesses von TSMC für alle diese GPUs, fällt die Transistordichte recht gleich aus.
1. Update:
Inzwischen haben wir zusätzlich zur Größe des Chips und der Anzahl der Transistoren auch die Größe der L1- und L2-Caches – zumindest für die GeForce RTX 5090 und GeForce RTX 5080.
| GB202 | AD102 | GB203 | AD103 | GB205 | AD104 | |
| Speicherinterface | 512 Bit | 384 Bit | 256 Bit | 256 Bit | 192 Bit | 192 Bit |
| L1-Cache pro SM | 128 kB | 128 kB | 128 kB | 128 kB | 128 kB | 128 kB |
| Gesamtkapazität L2-Cache | 128 MB | 96 MB | 64 MB | 64 MB | 48 MB | 48 MB |
* Der L1-Cache ist abhängig von den aktiven SMs. Pro SM sind 128 kB an L1-Cache vorhanden
NVIDIA verwendet zusammen mit dem auf 512 Bit verbreiterten Speicherinterface auch einen größeren L2-Cache. Aus dem breiteren Speicherinterface ergibt sich also keinerlei Verzicht auf eine gewisse Kapazität für den L2-Cache. Für die GB202-GPU hat NVIDIA den L2-Cache also anwachsen lassen. Zwischen dem GB203- und AD103-GPU ergeben sich mit 64 MB an L2-Cache keinerlei Unterschiede. Die Gesamtkapazität des L1-Caches ist abhängig von der Anzahl der SMs. Pro SM sind 128 kB vorhanden – sowohl bei der Blackwell- wie auch Ada-Lovelace-Architektur.
Details zur Blackwell-Architektur
Das neue Paradigma nennt NVIDIA die Blackwell Neural Shader. Die FP32- und INT32-Recheneinheiten innerhalb der Blackwell SMs können zusammen mit den Tensor-Kernen sowohl die klassischen Shaderaufgaben (Animation, Beleuchtung, Geometrie, Materials, Physik und Traversals) als auch die KI-Workloads übernehmen. Bei Ada Lovelace und davor verliefe beide Pfade noch parallel zueinander. Als Standard sehen NVIDIA und Microsoft die Cooperative Vectors vor.



















An dieser Stelle wird auch gleich der Unterschied im Aufbau der SMs deutlich. Während es in der Ada-Lovelace-Architektur 64 FP32-Recheneinheiten plus ebenfalls 64 flexibel nutzbare FP32- oder INT32-Recheneinheiten waren, sind es nun 128 FP32/INT32-Recheneinheiten pro SM. Hinzu kommen weiter verbesserte Tensor-und RT-Kerne. Auch zu diesen haben wir später noch weitere Details.

Um in der Ausführung der neuronalen Shader auf den Shadereinheiten und Tensor-Kernen möglichst effizient zu arbeiten, gibt es das Shader Execution Reordering. Per SER werden die Tensor-Core- und Shadereinheiten-Workloads zusammengefasst. Ausgeführt wird dies auf dem AI Management Prozessor. Dessen Fähigkeiten hat NVIDIA erweitert, sodass SER in der Blackwell-Architektur doppelt so schnell ausgeführt werden kann wie in der Ada-Lovelace-Architektur.
2. Update: Weitere Details
Inzwischen hat NVIDIA auch das Whitepaper zur Blackwell-Architektur der Presse zur Verfügung gestellt. Darin enthalten ist auch ein Diagramm der GB202-GPU im Vollausbau.
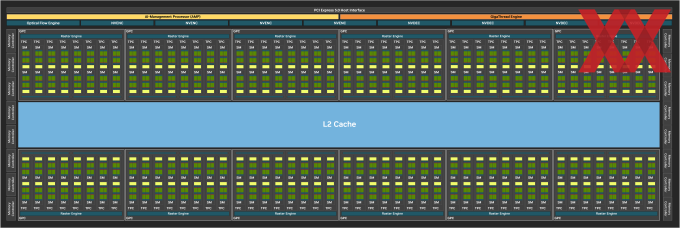
Die GB202-GPU im Vollausbau enthält 12 Graphics Processing Clusters (GPCs), 96 Texture Processing Clusters (TPCs), 192 Streaming Multiprozessoren (SMs) und ein 512 Bit breites Speicherinterface bestehend aus 16 jeweils 32 Bit breiten Speichercontrollern.
Außerdem enthält die GB202-GPU 384 FP64-Recheneinheiten (zwei pro SM), welche aber im obigen Diagramm nicht abgebildet werden. Die FP64-Rechenleistung beträgt 1/64 der TFLOPs für FP32-Rechenoperationen. Die geringe Anzahl an FP64-Recheneinheiten soll sicherstellen, dass alle Programme mit FP64-Code korrekt funktionieren. Ebenso ist eine sehr minimale Anzahl von FP64-Tensor-Kernen enthalten (NVIDIA spezifiziert nicht wie viele genau), um die "Korrektheit des Programms zu gewährleisten".
Der GPC stellt den dominanten High-Level-Hardware-Block der Blackwell-Architektur dar. Jeder GPC umfasst eine dedizierte Raster Engine, zwei Raster Operations (ROPs) Partitionen, wobei jede Partition acht einzelne ROP-Einheiten enthält, und acht TPCs. Jede TPC enthält eine PolyMorph-Engine und zwei SMs. Im Vollausbau kommt die GB202-GPU zudem auf 128 MB an L2-Cache, von dem auf der GeForce RTX 5090 96 MB nutzbar sind.
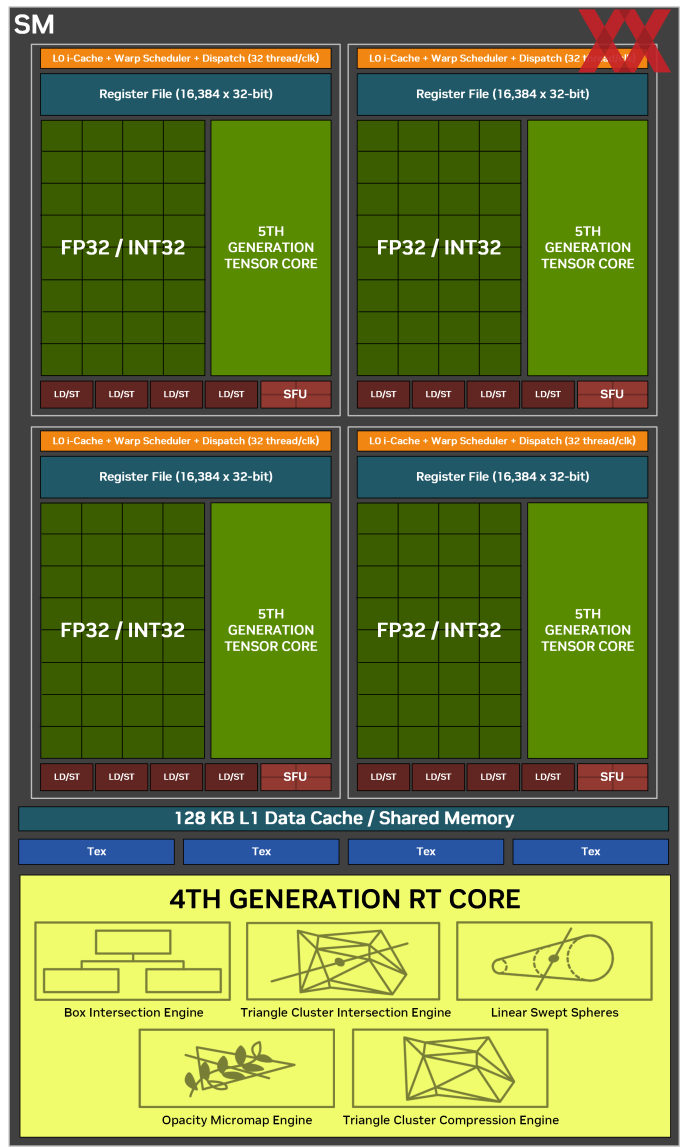
Der GB202-Chip besitzt, wie bereits erwähnt, 192 Streaming Multiprozessoren (SMs), von denen auf der GeForce RTX 5090 170 aktiv sind. Pro SM sind 128 FP32/INT32-Recheneinheiten vorhanden. Hinzu kommen jeweis ein RT-Kern der vierten Generation und vier Tensor-Kerne der fünften Generation. Weiterhin integriert sind vier Textureinheiten, 512 KB an Registern und 128 KB an L1-Cache, die über die 128 Shadereinheiten geteilt zur Verfügung stehen.
Für die GB203- und GB205-Konfiguration für die GeForce RTX 5080, GeForce RTX 5070 Ti und GeForce RTX 5070 kennen wir die vollen Ausbaustufen noch nicht.
Schneller Speicher für mehr Rechenleistung
Die GeForce-RTX-50-Serie wird die erste sein, die auf den neuen GDDR7-Speicher setzt. Mit GDDR7 wechselt der Standard im Vergleich zu GDDR6X von PAM-4 (Pulsamplitudenmodulation) auf PAM-3.

PAM-3 ermöglicht höhere Frequenzen bei zugleich besserer Signalintegrität und eine niedrigere Spannung. Mit bisher verfügbaren 32 GBit/s erreicht der GDDR7 eine doppelt so hohe Datenrate wie es bei GDDR6 anfangs der Fall war. Allerdings konnte GDDR6X deutlich höhere Datenraten erreichen und kommt fast an die 28 GBit/s des GDDR7 auf der GeForce RTX 5090 heran. Wegen der geringeren Spannung die notwendig ist, ist GDDR7 aber doppelt so effizient.
| GeForce RTX 5090 | GeForce RTX 5080 | GeForce RTX 5070 Ti | GeForce RTX 5070 | |
| Speicherinterface | 512 Bit | 256 Bit | 256 Bit | 192 Bit |
| Speicher | GDDR7 (28 Gbps) | GDDR7 (32 Gbps) | GDDR7 (28 Gbps) | GDDR7 (28 Gbps) |
| Speicherkapazität | 32 GB | 16 GB | 16 GB | 12 GB |
| Speicherbandbreite | 1.792 GB/s | 1.024 GB/s | 896 GB/s | 672 GB/s |
| GeForce RTX 4090 | GeForce RTX 4080 Super | GeForce RTX 4070 Ti Super | GeForce RTX 4070 Super | |
| Speicherinterface | 384 Bit | 256 Bit | 192 Bit | 192 Bit |
| Speicher | GDDR6X (21 Gbps) | GDDRX (23 Gbps) | GDDR7 (21 Gbps) | GDDR7 (21 Gbps) |
| Speicherkapazität | 24 GB | 16 GB | 12 GB | 12 GB |
| Speicherbandbreite | 1.008 GB/s | 736 GB/s | 504 GB/s | 504 GB/s |
Mehr Effizienz durch schnelle Taktwechsel
NVIDIA macht die Blackwell-GPUs aber nicht nur in der Ausführung der Workloads effizienter, sondern wendet auch neue Hardware-Technologien an.
Für die verschiedenen Bereiche und Blöcke der GPU kann NVIDIA ein Gating für die Takt-Domämen und die Spannungsversorgung vornehmen. Zudem hat NVIDIA zwei Spannungsschienen für den Compute- und Uncore-Bereich der GPU umgesetzt.
Die Effizienz erreicht NVIDIA aber auch durch die höhere Rechenleistung, denn aufgrund dieser kann die GPU schneller einen niedrigeren Power-Status erreichen. Durch die neuen Rail- und Clock-Gating-Funktionen werden aber auch effizientere Power-Stati überhaupt erst möglich. Auch die Latenz bis zum Erreichen des niedrigsten Power-Status ist geringer.
NVIDIA hat aber auch den Taktgeber der Blackwell-GPUs beschleunigt. Die Blackwell-SMs können ihren Takt um den Faktor 1.000 schneller wechseln, was sie einerseits schneller macht und damit die Leistung steigert, was aber auch der Effizienz zuträglich ist.
Neue Tensor- und RT-Kerne
Die neuen Tensor-Kerne der fünften Generation können nun auch das Datenformat FP4 effizient berechnen. Da KI-Modelle immer größer und komplexer werden, ist es entscheidend, die Trainings- und Inferencing-Leistung zu verbessern. Im Falle der GeForce-RTX-Karten und Ausführung der Modelle für DLSS oder Frame Generation geht es vorrangig um das Inferencing. Die Tensor-Kerne der Blackwell-Architektur unterstützen neue Quantifizierungsformate – wie High Speed FP4.
Per SER stellen die Tensor-Kerne dann einen Teil der Rechenleistung für die neuronalen Shader.

Aber auch die Raytracing-Kerne lernen ein paar neue Tricks. Mit der dritten Generation in der Ada-Lovelace-Architektur beschleunigte NVIDIA die Raytracing-Berechnungen über die Box Intersection Engine, Triangle Intersection Engine und Opacity Micromap Engine. Die vierte Generation der RT-Kerne in der Blackwell-Architektur behält die Box Intersection Engine und Opacity Micromap Engine in der jetzigen Form, baut die Fähigkeiten in anderen Aspekten aber aus.
Neu hinzugekommen ist die Triangle Cluster Intersection Engine. Sie soll eine bessere Parallelisierung in den Raytracing-Berechnungen ermöglichen. Um dies zu erläutern, gehen wir aber einen Schritt zurück:
Eine BVH (Bounding Volume Hierarchy) ist eine Datenstruktur für das Raytracing, um die Berechnung der Schnittpunkte zwischen Strahlen und Geometrieobjekten effizienter zu gestalten. Die BVH reduziert die Anzahl der Tests, die notwendig sind, um festzustellen, ob ein Strahl/Ray ein Objekt trifft, indem sie die Geometrie in einer hierarchischen Struktur organisiert.


In Spielen müssen hunderte, wenn nicht tausende 3D-Objekte dargestellt werden. Allesamt verfügen diese Objekte über ein mehr oder weniger detailliertes 3D-Modell. Um die Anzahl der zu berechnenden Objekte und Details besser ausbalancieren zu können, gibt es verschiedene Techniken. Die wohl bekannteste ist die Abstufung des Detailgrads über den Abstand des Betrachters. Über unterschiedliche Tessellation-Techniken können geometrische Details in komprimierter Form gespeichert und letztendlich wiedergegeben werden.
Die diversen Tessellation-Techniken haben allerdings auch einige Nachteile. So erzeugt ein zu- oder abnehmender Abstand zu solchen Objekten eine Art von Popups, in denen deutlich zu erkennen ist, wie Objekte aufpoppen oder plötzlich in einem höheren Detailgrad berechnet werden. Es gibt wiederum Techniken, diesen Effekt zu minimieren, meist aber bleibt er erkennbar. Kommt dann noch die Berechnung des Raytracing hinzu, fehlen nicht nur Objektdetails, sondern auch die darauf angewendeten Objekte.
Durch die Bildung von Clustern können Objekte in mehr Polygone zerlegt und dennoch ein BVH angewendet werden. Eben dies beschleunigt die Triangle Cluster Intersection Engine.


Eine weitere Neuerung der RT-Kerne in der Blackwell-Architektur sind die Linear Swept Spheres. Diese können unter anderem in der Simulation von Haaren und Fell hilfreich sein. Ein Raytracing von Haaren und Fell über den klassischen Weg der Polygone wäre schlichtweg zu aufwendig – vor allem wenn man sich mehrere hundert oder gar tausend simulierte Objekte vor Augen führt.
Anstatt das Haar oder Fell in Polygone aufzubrechen, werden mehrere Sphären miteinander verbunden. Pro linearen Element eines Haars sind nur zwei Sphären in der Berechnung notwendig.

Die RT-Kerne der Blackwell-Architektur können doppelt so viele Kreuzungen der Rays berechnen, wie dies bei Ada Lovelace der Fall ist. Auf dem Editors Day präsentierte NVIDIA einige imposante Demos zur RTX Mega Geometry und Nanite Cluster Based Geometry.
Blackwell Display- und Video-Engine
Neben den überarbeiteten Streaming-Multiprozessoren mit Neural Shaders der Blackwell-Architektur hat NVIDIA auch die Display- und Video-Engine überarbeitet.

Die Display-Engine der Ada-Lovelace-Architektur unterstützte DisplayPort 1.4a HBR3 mit bis zu 32,4 GBit/s und der Unterstützung von Display Stream Compression 1.2 (DSC). Mit den Blackwell-Karten kann NVIDIA nun DisplayPort 2.1 UHBR20 für 20 GBit/s pro Lane, bei maximal vier Lanes also 80 GBit/s, anbieten. Maximal möglich sind demnach 4K bei 480 Hz oder 8K bei 120Hz mit DSC. Auf den Founders-Edition-Karten vorhanden sind dreimal DisplayPort und einmal HDMI 2.1a.
Auch die Video-Engine wird aktualisiert. Der NVENC-Decoder liegt in der sechsten Generation vor, beim NVENC-Encoder ist es die neunte Generation. Unter anderem ermöglicht wird ein AV1 mit einem neuen UHQ-Profil (Ultra High Quality). Zudem kann möglich ist ein Decoding von Multi View-HEVC – zum Beispiel für VR-Anwendungen.
Die neue Blackwell-Video-Engine verfügt zudem über gleich zwei H.264-Decoder und ermöglicht das De- und Encoding von 4:2:2-Videoinhalten. 4:2:2-Videoencoding ist ein Farbunterabtastungsverfahren, bei dem die Helligkeitsinformationen (Luma, Y) vollständig erhalten bleiben, während die Farbinformationen (Chroma, U und V) halbiert werden. Im Vergleich zu 4:4:4, das alle Informationen vollständig speichert, und 4:2:0, das die Farbwerte noch stärker reduziert, bietet 4:2:2 ein gutes Gleichgewicht zwischen Qualität und Dateigröße, was es ideal für professionelle Videoproduktionen macht.
RTX Neural Radiance Cache
Neuronale Netzwerke sollen auch für die direkte Raytracing-Berechnung zum Einsatz kommen. So ermöglicht der RTX Neural Radiance Cache mehr Bounces in der Raytracing-Berechnung, ohne dass der Aufwand für die RT-Einheiten explodiert.
Ermöglicht wird damit unter anderem eine Technik namens RTX Skin. Damit ist es möglich, auch die Lichtstrahlen in halbdurchsichtigen Objekten wie zum Beispiel von Haut zu berechnen, was andernfalls extrem aufwendig ist.


Auch zum RTX Neural Radiance Cache gab es einige imposante Demos:
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
Neue Modelle für DLSS und Ray Reconstruction
Mit DLSS 4 und der GeForce-RTX-50-Serie führt NVIDIA den nächsten großen Wechsel im zugrundeliegenden KI-Modell sein. Bisher kam ein sogenanntes Convolutional Neural Network (CNN) zum Einsatz. Inzwischen ist ein solches Netzwerk aber nicht mehr in der Lage, die Anforderungen für Super Resolution, Ray Reconstruction und Multi Frame Generation zu erfüllen, und so ist NVIDIA auf ein Transformer-Modell gewechselt.

Dieses neue Modell verwendet einen auf die Bilddarstellung spezialisierten Vision Transformer, der es ermöglicht, die relative Bedeutung jedes Pixels über den gesamten Frame und über mehrere Frames hinweg zu bewerten. Das Vision Transformer Model verwendet die doppelte Anzahl an Parametern im Vergleich zum CNN. Damit erreicht NVIDIA eine höhere Detailgenauigkeit für Frame Generation:


Neben der Frame Generation profitieren vom neuen Transformer-Modell auch die Funktion Ray Reconstruction sowie DLSS.
Ausgeführt werden können die neuen KI-Modelle aber nicht nur von den neuen GeForce-RTX-50-Karten, sondern auch von den vorherigen Generationen. Die Transformer-Modelle für DLSS 3 und DLSS 4 mit (Multi) Frame Generation sind schneller und benötigen weniger Grafikspeicher. Allerdings steigt auch die notwendige Rechenleistung, sodass es hier durchaus einen Punkt geben kann, an dem CNN besser als das neue Transformer-Modell ist.
DLSS 4 Multi Frame Generation
Ohne Frage bieten die Blackwell-GPUs eine höhere Rechenleistung als ihre Vorgänger. Einen Großteil des Leistungsplus erzielt NVIDIA jedoch über das neue DLSS 4 mit Multi Frame Generation. Nicht mehr nur jeder zweite Frame wird per Frame Generation komplett erzeugt, sondern mittels MFG 4X Mode wird ein Frame gerendert und auf diesen folgen drei erzeugte Frames.
Möglich wird dies unter anderem durch Verbesserungen im Optical Flow Accelerator. Das neue KI-Modell ist zudem um 40 % schneller und belegt bis zu 30 % oder 400 MB weniger Platz im Grafikspeicher. Das zuvor über ein Optical Flow Field wird zudem in Teilen durch ein KI-Modell ersetzt, sodass auch hier keine Hardware mehr zum Einsatz kommt. Insgesamt werden fünf KI-Modelle in Super Resolution, Ray Reconstruction und Multi Frame Generation ausgeführt.



Zusammen mit der ersten Umsetzung von Frame Generation wurde NVIDIA aber auch klar, dass es eine Technik zur Reduzierung der Systemlatenz geben muss, denn Eingaben, die sich im Frame ausdrücken, können nur im gerenderten Frame übernommen und dargestellt werden. Im generierten Frame kommen keine weiteren Eingabe-Informationen hinzu. Wie hat NVIDIA dieses Problem gelöst?

Für das neue Frame Generation wechselt NVIDIA auf einen neuen Frame-Pacing-Mechanisms, der nicht mehr durch den Prozessor vorgegeben wird, sondern durch die GPU bzw. die Display Engine. Das Flip Metering erzeugt konstante Frametimes bei zugleich niedriger Latenz.

| FPS | Latenz | |
| GeForce RTX 5090 ohne DLSS | 27 | 71 ms |
| GeForce RTX 5090 mit DLSS 2 Super Resolution | 71 | 34 ms |
| GeForce RTX 5090 mit DLSS 3.5 Frame Generation und Ray Reconstruction | 140 | 35 ms |
| GeForce RTX 5090 mit DLSS 4 Multi Frame Generation und neuem Transformer-Modell | 248 | 34 ms |
Belegt wird dies von NVIDIA durch eine Szene in Alan Wake 2. Ohne DLSS werden 27 FPS bei einer Latenz von 71 ms erreicht. Mit DLSS 2 Super Resolution sind es dann 71 FPS bei 34 ms. DLSS 3.5 mit Frame Generation und Ray Reconstruction kommt auf 140 und damit doppelt so viele FPS bei fast identischer Latenz. DLSS 4 mit Multi Frame Generation und dem neuen Transformer-Modell kommt auf 248 FPS bei weiterhin 34 ms an Latenz.
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
DLSS 4 soll zum Start der ersten beiden GeForce-RTX-50-Karten für 75 Spiele zur Verfügung stehen. Viele weitere werden dann sicherlich kurz darauf folgen.

Reflex 2 mit Frame Warp
Reflex ist für kompetitive Spieler ein inzwischen wichtiges Element. Die Reflex-Technologie reduziert die Latenz zwischen Eingabe (durch einen Mausklick) und Bildschirmreaktion, was besonders in kompetitiven Spielen entscheidend ist. Reflex optimiert die Kommunikation zwischen der CPU und GPU, um Engpässe zu minimieren und eine schnellere Reaktionszeit zu gewährleisten. Reflex arbeitet in unterstützten Spielen, indem es die Render Queue verkürzt und so Frames schneller zum Monitor bringt.
Reflex hilft auch im Zusammenhang mit der Frame-Generation-Technologie. Der Prozess der Frame Generation fügt eine gewisse Latenz hinzu, da zusätzliche Rechenzeit für die KI-Interpolation benötigt wird. NVIDIA Reflex kompensiert diese zusätzliche Latenz, indem es die Systemlatenz insgesamt reduziert.



Mit Reflex 2 geht NVIDIA nun den nächsten Schritt. Reflex 2 enthält die Frame-Warp-Komponente. Frame Warp schätzt ab, in welche Richtung sich die Kamera bewegen wird. Ein Inpainting füllt die Lücken an den Rändern des Frames die entstehen, da dieser zukünftige Frame ja noch gar nicht berechnet wurde. Die entsprechenden Informationen über den Frame werden ergänzt. Dazu werden Daten des vorherigen Frames, sowie Farbwerte und Daten zur Tiefe innerhalb der 3D-Szene verwendet.
Reflex 2 wird vorerst nur auf den GeForce-50-Karten laufen, soll später aber auch für die älteren Karten umgesetzt werden. Eine direkte Integration in die Spiele ist notwendig, damit Reflex 2 funktioniert und auch keine Anti-Cheat-Software getriggert wird. The Finals und Valorant werden die ersten Spiele sein, die Reflex 2 unterstützen werden.
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
Founders Edition mit Double Flow-Through
Auf den ersten Blick sind die Karten der GeForce-RTX-50-Serie ihren Vorgängern sehr ähnlich. Allerdings hat NVIDIA das Design in einigen Aspekten weiterentwickelt. Bereits auf dem Editors Day haben wir die Founders Edition der GeForce RTX 5090, GeForce RTX 5080 und GeForce RTX 5070 zu Gesicht bekommen. Die beiden erstgenannten Modelle sind dabei sehr ähnlich aufgebaut, was auch für das extrem kompakte PCB gilt. Auch dieses konnten wir bereits genauer betrachten. Die GeForce RTX 5070 Founders Edition wird im Aufbau vermutlich etwas anders gestaltet sein. Dies werden wir uns dann aber zum Start im Februar noch einmal genauer anschauen.

In der Mitte ist zu erkennen, wo sich das fast quadratische und kompakte PCB befindet. Rechts und links davon kann man mit dem richtigen Blickwinkel durch die Kühlfinnen hindurchschauen. Grundsätzlich sind der Aufbau und die Wahl der Material recht ähnlich zu dem, was NVIDIA für die GeForce-RTX-40-Serie umgesetzt hat.
Was auf den Bildern auch zu erkennen ist, ist die Tatsache, dass die Kanten der Finnen, die hier in unserer Richtung zeigen, zweidimensional konkav gestaltet sind. Dort, wo sich die Lüfternabe befindet, ist eine kleine Mulde vorhanden, während der Randbereich, dort wo sich die Lüfterblätter am schnellsten drehen, eine leichte Erhöhung vorhanden ist. NVIDIA variiert damit die Tiefe des Finnenstacks in Abhängigkeit zum Luftdruck, der durch den Lüfter aufgebaut werden kann.

Das Double-Flow-Through-Design der Founders-Edition-Karten stellt dabei eine konsequente Weiterentwicklung dar. Wir alle erinnern und noch an die Blower-Design der vergangenen Tage, wie es zum Beispiel in der GeForce-GTX-10-Serie zum Einsatz gekommen ist. Der Luftstrom war hier durch das Kühler-Design extrem gut vorausplanbar, dieser war aber gewissen Restriktionen unterlegen. Die GeForce-RTX-20-Serie hatte dann beispielsweise ein Dual-Axial-Design, wie wir es auch heute noch häufig sehen. Die Luft wird angesaugt, geht durch den Kühler und prallt dann auf das PCB. Mit der GeForce-RTX-30-Serie setzte sich dann erstmals ein Flow-Through-Design durch, bei dem zumindest einer der verwendeten Lüfter einen linearen Luftstrom durch den Kühlkörper erzeugt.
Mit dem kompakten PCB in der Mitte haben in der GeForce-RTX-50-Serie nun beide Axiallüfter die Möglichkeiten einen linearen Luftstrom zu erzeugen, der ohne größere Hindernisse durch den Kühlkörper geführt wird.
| GeForce RTX 5090 Founders Edition | GeForce RTX 5080 Founders Edition | GeForce RTX 5070 Founders Edition | |
| Länge | 304 mm | 304 mm | 242 mm |
| Breite | 137 mm | 137 mm | 112 mm |
| Slot-Belegung | 2 Slots | 2 Slots | 2 Slots |
Eine effizientere Kühlung bei gleichzeitig geringeren Abmessungen verspricht NVIDIA durch das neue Design. Die GeForce RTX 5090 und GeForce RTX 5080 in der Founders Edition belegen nun nur noch zwei statt drei Slots. Für die GeForce RTX 5070 Founders Edition bleiben die Abmessungen im Vergleich zum Vorgänger identisch.

Vom Double-Flow-Through-Design verspricht sich NVIDIA eine bessere Skalierung in der Lautstärke bei höherer Leistungsaufnahme. Für etwa 300 W und mehr an Abwärme wäre das Dual-Axial-Design nicht mehr in der Lage, eine ausreichende Kühlung zu gewährleisten, ohne dass die Karten zu laut geworden wären. Für ein einfaches Flow-Through-Design erkannte NVIDIA in der GeForce-RTX-40-Serie ab 450 W die Grenze – was wohl auch die 450 W der GeForce RTX 4090 und auch den Flow-Through-Prototypen der GeForce RTX 4090 Ti erklärt. Bis zu 600 W soll das Double-Flow-Through-Design mit noch annehmbarer Lautstärke abführen können.
Generative-KI in Spielen und für den RTX-AI-PC
DLSS, Frame Generation, Ray Reconstruction – gleich mehrere KI-Modelle werden ausgeführt, wenn eine der genannten Technologien zum Einsatz kommt. Aber mit ACE hat NVIDIA bereits gezeigt, dass in Zukunft in Spielen noch weitere Möglichkeiten für die Anwendung von generativer KI gegeben sind.
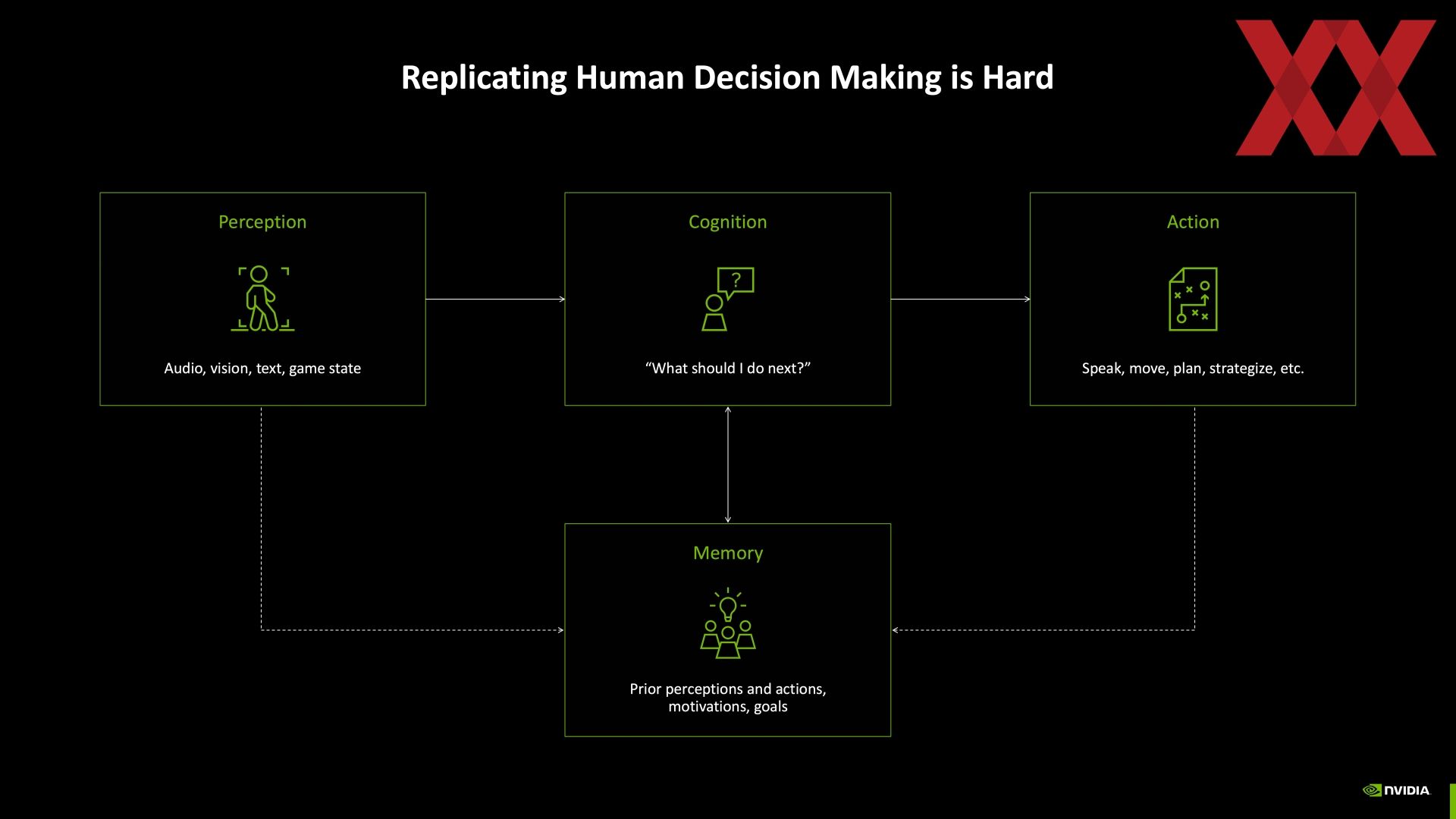

In näherer Zukunft werden wir sicherlich die ersten KI-unterstützten NPCs in Spielen sehen. Diese NPCs sollen sich ein deutlich realistischeres Verhalten aufweisen, als dies bei geskripteten Charakteren der Fall ist. Ein Audio-to-Text-Modell nimmt die Eingaben des Spielers auf. Diese Eingaben landen in einem LLM, welches wiederum weitere Faktoren, wie den Status des Spielers gegenüber dem NPC, mit einbezieht. Die Antwort oder Reaktion des LLMs wird in ein Text-to-Audio-Modell gefüttert, zur Darstellung auch in ein Audio-to-Face-Modell und es soll eine möglichst lebensnahe Interaktion zwischen Spieler und NPC entstehen.
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
Krafton, der Entwickler von PUBG stellt unter anderem den PUBG Ally vor. Dabei handelt es sich um einen KI-unterstützten Charakter, den Krafton als CPC (Co-Playable Character) bezeichnet. Der Spieler kann sich mit diesem CPC unterhalten, bekommt im Spiel Hilfe, kann diesen aber auch anweisen, bestimmte Aktionen durchzuführen. Dabei passt sich der CPC der Spielweise an bzw. nimmt auch langfristige Aufgaben auf. Im oben eingebundenen Video ist der PUBG Ally in Aktion zu sehen.
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
Ein weiteres Beispiel ist die Lebens-Simulation inZOI – ebenfalls von Krafton. Durch die auf der ACE-Technologie basierenden Integration von KI sollen sich die Charaktere in inZOI wie echte Menschen verhalten, was gerade in einer Lebens-Simulation aufgrund der Komplexität und den Abhängigkeiten der zahlreichen Entscheidungen anderes sicherlich kaum möglich wäre.
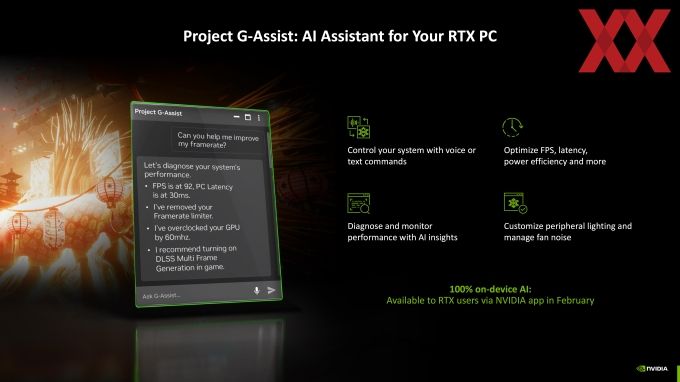
Bereits auf der Computex 2024 zeigte NVIDIA den G-Assist. Dieser soll Spielern vor allem in komplexen Titeln wie ein Sprachassistent unter die Arme greifen, um ihm wichtige Hilfestellungen zu geben. Der G-Assist läuft als separate Anwendung im Hintergrund und soll sich auf die vielen Wiki-Seiten, YouTube-Videos und Komplettlösungen, die man zahlreich im Internet finden kann, stützen, um zu seinen Informationen zu gelangen. Alleine auf Steam gibt es über zwei Millionen Guides. Dem Spieler will man so die Recherche abnehmen und ihn schließlich schneller zu seinem gewünschten Ziel bringen. G-Assist kann von den Spiele-Entwicklern aber auch direkt eingebunden und vorab mit den richtigen Tricks und Kniffs trainiert werden.
Der G-Assist soll den Spieler aber nicht nur inhaltlich weiterhelfen können, sondern auch technisch. Auf Wunsch kann er die aktuelle Framerate ausgeben, die Latenz tracken oder die Grafiksettings für eine bessere Performance optimieren. Sogar ein Overclocking oder ein Undervolting soll möglich sein – beispielsweise durch die Limitierung der Framerate.
Dem Nutzer des G-Assist soll es aber auch möglich sein, diesen zu erweitern. Dazu wird NVIDIA auf GitHub den notwendigen Code bereitstellen, sodass eigene Plugins integriert werden können. Diese werden auch von anderen Herstellern angeboten werden, sodass Zubehör wie eine RGB-Beleuchtung oder anderen Software über den G-Assist angesprochen werden können.


















Um in Zukunft in allen Bereichen noch breiter aufgestellt zu sein, bietet NVIDIA mit den NIM-Microservices und Blueprints die neuesten generativen Modelle für die verschiedensten Anwendungsbereiche an. Diese können dann möglichst einfach auf den eigenen RTX-AI-PC eingesetzt werden.
NIM-Microservices finden bereits im Datacenter großflächig Verwendung und bieten eine schnelle und effiziente Möglichkeit, die diversen KI-Workloads mit den für die NVIDIA-Hardware optimierten Modellen auszuführen. Nun bietet NVIDIA die NIM-Mikroservices auch für die GeForce-RTX-GPUs an, sodass Anwendungen wie ChatRTX, AnythingLLM, ComfyUI und LM Studio ohne weiteres Zutun mit der bestmöglichen Leistung und Effizienz arbeiten. Kombiniert werden können die NIM-Microservices mit Blueprints, um schnell KI-gesteuerte Workflows einzurichten, anzupassen und bereitzustellen. Damit lassen sich Aufgaben automatisieren und neue Funktionen freischalten.
Als Beispiel zeigte NVIDIA ein Blueprint, um aus einem technischen Dokument in Form eines PDF einen Podcast zu machen, in dem sich zwei Personen über den Inhalt des PDFs unterhalten. Der Inhalt des PDFs kann auch so aufbereitet werden, dass der Nutzer Fragen zum Inhalt stellen kann. Möglich ist dies in Teilen natürlich auch heute schon, wenn man das PDF beispielsweise ChatGPT gibt. Dabei aber verlassen die Daten den eigenen Verantwortungsbereich und sicherlich nicht jeder möchte seine Daten OpenAI, Google, Microsoft oder einem LLM eines anderen Anbieters überlassen.

Im Februar soll es die erste Welle an RTX NIMs geben. Diese beinhalten dann Microservices für LLMs, Text-to-Object, Sprache, Animation, Computer Vision, Bilderzeugung und vieles mehr.
Erste Leistungswerte und Ausblick
Bereits mit der Präsentation der GeForce-RTX-50-Serie präsentierte NVIDIA einige Benchmarks, meist mit Unterstützung von DLSS und Frame Generation. Im Rahmen des Editors Days nannte NVIDIA aber auch einige Zahlen zur Rasterizer-Leistung, die sich sicherlich auch aus den Diagrammen ablesen lassen




Die Grafiken geben eine grobe Richtung vor und zeigen auch, dass die Rasterizer- und DLSS-Leistung ohne Multi Frame Generation sich im Verhältnis zueinander nahezu identisch verhalten. Die großen Leistungssprünge ergeben sich aus dem MFG-4X-Mode, wo zu jedem gerenderten Frame drei erzeugte hinzukommen.
| Rasterizer-Leistungsplus gegenüber dem Vorgänger | |
| NVIDIA GeForce RTX 5090 | + 30 % |
| NVIDIA GeForce RTX 5080 | +15 % |
| NVIDIA GeForce RTX 5070 Ti | + 20% |
| NVIDIA GeForce RTX 5070 | + 20 % |
Wir sind aktuell bereits mit den Tests der GeForce RTX 5090 und GeForce RTX 5080 beschäftigt. Das Testsystem wurde komplett umgestellt und die vorherigen Generationen von AMD und NVIDIA müssen getestet werden. Zudem wird es zahlreiche Sondertests zu DLSS 4 und Multi Frame Generation geben.
Ab dem 30. Januar werden die Modelle der GeForce RTX 5090 und GeForce RTX 5080 dann im Handel sein. Wie gut es um die Verfügbarkeit bestellt ist, dürfte sicherlich eine spannende Frage sein. Neben dem Preis von 2.329 Euro bzw. 1.169 Euro spielen dabei natürlich auch die zur Verfügung stehenden Stückzahlen eine wichtige Rolle.
