

Werbung
War „Richland“ noch ein Facelift zu „Trinity“, wurde „Kaveri“ von Grund auf neu entworfen. Die „Steamroller“-Architektur der beiden Prozessor-Module ist laut Angaben AMDs bisher größte Architektur-Änderung seit der Einführung von „Bulldozer“. Der inzwischen längst verstaubte VLIW4-Aufbau bei der Grafikeinheit wurde bei „Kaveri“ gegen die GCN-Architektur ausgetauscht und die lang umworbenen Features rund um HSA implementiert. Die fortschrittliche 28-nm-Fertigung rundet das Gesamtpaket ab.
Heterogene System-Architektur (HSA)

Die wohl größte Neuerung von „Kaveri“ ist die Umstellung auf eine heterogene System-Architektur (HSA), wodurch Grafik- und Prozessor-Kerne noch enger zusammenarbeiten sollen. Ein Grund, weswegen AMD beide Funktionseinheiten zusammenfasst und von Compute-Cores spricht. Vor allem immer wieder hervorgehoben werden zwei Funktionen: „Shared System Memory“ und „Heterogeneous Queuing“. Erstere Technologie schafft einen Speicher, der sowohl von den CPU- wie auch von den GPU-Kernen genutzt werden kann, womit beide Funktionseinheiten immer auf dem neuesten Stand bleiben und ihre Informationen direkt miteinander austauschen können. Ein langwieriges Kopieren der Daten entfällt.
Dieser gemeinsame Speicherbereich „hUMA“ ist Grundvoraussetzung für hQ. Bislang galt die CPU als Master-Einheit und war für den kompletten Programmablauf zuständig. Nun soll auch die GPU die CPU direkt mit Jobs füttern können, was beide Funktionseinheiten gleichstellt, sie aber auch unterschiedliche Aufgaben übernehmen lässt. Während sich CPUs besser für serielle Aufgaben eignen, liegen die Stärken einer GPU auf parallelen Rechenaufgaben. Durch die Verteilung dieser verspricht sich AMD eine höhere Effizienz. In Zahlen ausgedrückt: Die neuen „Steamroller“-Kerne sollen eine bis zu 20 Prozent höhere Leistung abliefern als die Vorgänger-Generation.
„Steamroller“-Architektur
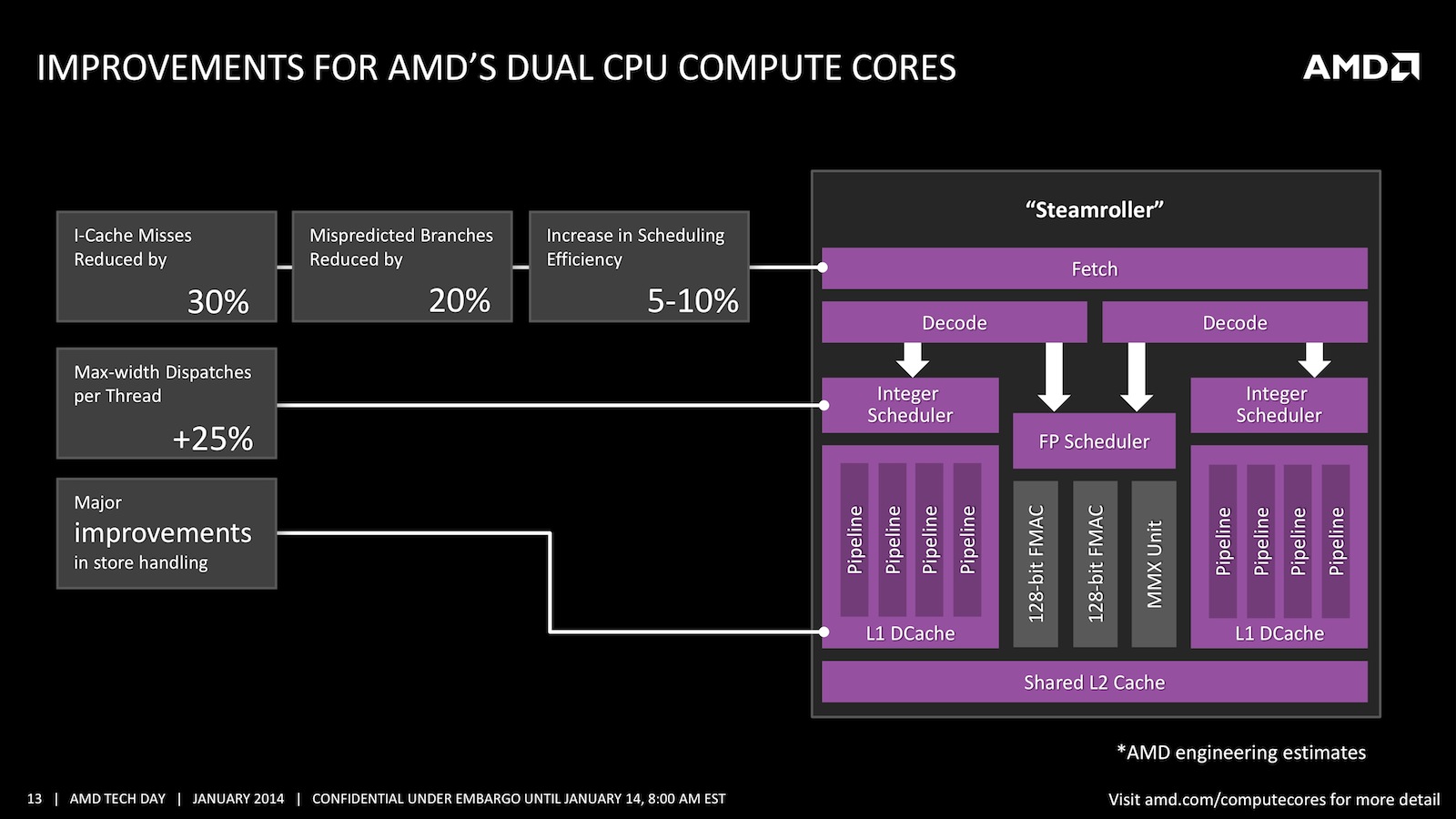
Mit den neuen „Steamroller“-Kernen sollen die Probleme, die „Bulldozer“ noch hatte, behoben werden. Am Konzept von „Bulldozer“ hält AMD im Groben aber weiter fest. Am Pipeline-Anfang gibt es wie gehabt einen gemeinsamen Fetch-Schritt. Ein Modul besitzt zwei Integer-Kerne, die sich eine FPU und einen Instruktions-Cache, der auf 96 kB vergrößert wurde, teilen. Dafür gibt es neue Prefetcher und einen eigenen Befehlsdecoder für die Integereinheiten, womit die Fetch-Stufe im Frontend 30 Prozent weniger Cache-Fehlschläge bei Datenbank-Anwendungen erreichen soll. Weiterhin wurde die Dispatch-Bandbreite pro Thread um 25 Prozent erweitert. Vor allem bei Single-Core-Anwendungen dürfte „Kaveri“ damit bei gleichem Takt deutlich zulegen können. Die Pro-Megahertz-Leistung soll bei „Kaveri“ höher ausfallen als noch bei der Vorgänger-Generation, ein Grund, weshalb AMD die Taktraten leicht abgesenkt hat.
Umstieg auf GCN-Architektur

Die neue GPU-Architektur soll die Grafikleistung sogar um 50 Prozent beschleunigen. Möglich soll dies dank eines Grafikchips der Radeon-R7-Reihe und dem damit verbundenen Wechsel vom eingestaubten VLIW4-Aufbau hin zur GCN-Architektur, wie sie bereits in der „Volcanic Islands“-Generation und seit der Radeon-HD-7000-Familie zum Einsatz kommt, werden. Bei einer VLIW-Befehlsstruktur wird ein sequentieller Programmablauf mithilfe eines Compilers in kleinere Instruktionen aufgeteilt und entsprechend parallelisiert. Der Compiler muss diese nicht nur in eine bestimmte Gruppengröße zerlegen, sondern später auch wieder zusammenfassen, was in der Praxis nicht immer ideal war – es kam zu Leerinstruktionen. Bei GCN muss ein solcher „register port conflict“ nicht mehr gehandelt werden. GCN verfolgt einen völlig anderen Ansatz. Die kleinste Einheit bildet hier die Compute-Unit, die wiederum aus vier Vektor-Prozessoren besteht, die sich aus vier SIMDs mit je 16 ALUs zusammenfügen. Im Falle des A10-7850K stehen der Grafiklösung acht Compute-Units und somit 512 Shader-Prozessoren (8 CUs x 4 SIMDs x 16 ALUs) zur Verfügung. Da an jeden Shadercluster vier Textureinheiten angeschlossen sind, stehen in der Summe 32 TMUs zur Verfügung. Das Speicherinterface weist eine Breite von 128 Bit auf.
Damit entspricht die Grafiklösung des A10-7850K einer AMD Radeon HD 7750, deren Taktraten allerdings reduziert wurden. AMD gibt den Grafik-Takt bei allen neuen „Kaveri“-APUs mit 720 MHz an. Die Radeon HD 7750 brachte es hier noch 800 MHz.

Darüber hinaus soll „Kaveri“ die notwendigen DSPs für AMDs True Audio besitzen, die neue Low-Level-API „Mantle“ unterstützen und PCI-Express-3.0-Support mit sich bringen. Der Speichercontroller kommt weiterhin mit 2.133 MHz schnellem DDR3-Speicher zurecht. Die neuen Modelle sollen sich auf dem Desktop in TDP-Klassen zwischen 45 und 95 Watt wiederfinden. Für Notebooks soll es auch Ableger mit nur 15 Watt TDP geben. Zu guter Letzt haben der Video-Encoder (VCE) und der Unified-Video-Decoder (UVD) einen Versionssprung nach vorne gemacht.
Neue Mainboards werden fällig
Die Umstellung der Architektur macht leider eine neue Pin-Struktur notwendig, weshalb AMD bei „Kaveri“ wieder einmal mehr einen neuen Sockel einführen muss. Während „Richland“ bislang nach dem Sockel FM2 verlangte, ist es bei „Kaveri“ nun der Sockel FM2+. Dieser soll laut AMD jedoch abwärtskompatibel zu den Vorgänger-Modellen der A-Serie 6000 und 5000 sein, bringt mit dem A88X und A78 aber auch neue Chipsätze mit sich. Diese entsprechen mit Ausnahme kleinerer Änderungen aber ihren Vorgängern A85X und A75. Laut AMD soll auch der ältere A55-FCH unterstützt werden.

