
MLCommons
-
MLPerf Training 4.1: Erstauftritt von NVIDIAs B200 und Googles Trillium im KI-Training
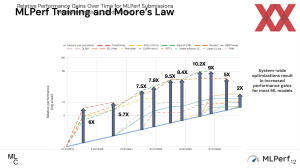 Die MLCommons hat heute die Trainings-Ergebnisse in der aktuellsten Version vorgestellt und diese beinhalten erstmals auch NVIDIAs B200-Beschleungier sowie den Google TPUv6p Trillium. Mit den Inference-4.1-Ergebnissen feierten sowohl der B200 wie auch der TPUv6e ihre Prämiere. An das Inferencing werden aber andere Herausforderungen gestellt, als dies beim Training der Fall ist. Die Blackwell-GPU wurde von NVIDIA zunächst auch primäre mit dem... [mehr]
Die MLCommons hat heute die Trainings-Ergebnisse in der aktuellsten Version vorgestellt und diese beinhalten erstmals auch NVIDIAs B200-Beschleungier sowie den Google TPUv6p Trillium. Mit den Inference-4.1-Ergebnissen feierten sowohl der B200 wie auch der TPUv6e ihre Prämiere. An das Inferencing werden aber andere Herausforderungen gestellt, als dies beim Training der Fall ist. Die Blackwell-GPU wurde von NVIDIA zunächst auch primäre mit dem... [mehr] -
MLPerf Inference 4.0: Das Debüt der H200 von NVIDIA gelingt
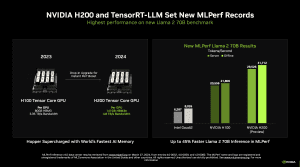 Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr]
Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr] -
MLPerf Inference 2.1: H100 mit erstem Auftritt und mehr Diversität
 Es gibt eine neue Runde unabhängiger, bzw. gegenseitig geprüfter Benchmark-Ergebnisse aus dem Server-Bereich. Genauer gesagt geht es um die Inferencing-Ergebnisse in der Version 2.1. Diese sollen eine unabhängige Beurteilung der Server-Systeme in den verschiedenen Anwendungsbereichen ermöglichen. Große Unternehmen werden natürlich weiterhin eine eigene Evaluierung vornehmen, aber in der Außendarstellung konnten die Hersteller meist nur mit... [mehr]
Es gibt eine neue Runde unabhängiger, bzw. gegenseitig geprüfter Benchmark-Ergebnisse aus dem Server-Bereich. Genauer gesagt geht es um die Inferencing-Ergebnisse in der Version 2.1. Diese sollen eine unabhängige Beurteilung der Server-Systeme in den verschiedenen Anwendungsbereichen ermöglichen. Große Unternehmen werden natürlich weiterhin eine eigene Evaluierung vornehmen, aber in der Außendarstellung konnten die Hersteller meist nur mit... [mehr] -
MLPerf Training 2.0: NVIDIA die beständige Konstante, Graphcore, Google und Habana mit neuer Hardware
 Die MLCommons hat die neuesten Ergebnisse für das Training von AI-Netzwerken veröffentlicht. Im Rahmen des MLPerf Training v2.0 geht es einmal mehr darum, eine Vergleichsbasis für solche Systeme zu bilden. Unternehmen wie Dell, HPE, Google, Inspur, Intel, Lenovo, NVIDIA, Gigabyte, Supermicro, Graphcore und viele weitere können an den Benchmarks teilnehmen, müssen sich natürlich an die aufgestellten Regeln halten und dürften auch die... [mehr]
Die MLCommons hat die neuesten Ergebnisse für das Training von AI-Netzwerken veröffentlicht. Im Rahmen des MLPerf Training v2.0 geht es einmal mehr darum, eine Vergleichsbasis für solche Systeme zu bilden. Unternehmen wie Dell, HPE, Google, Inspur, Intel, Lenovo, NVIDIA, Gigabyte, Supermicro, Graphcore und viele weitere können an den Benchmarks teilnehmen, müssen sich natürlich an die aufgestellten Regeln halten und dürften auch die... [mehr]
