Hmm, die Grundannahme war doch, dass wir Software benutzen, die hinreichend viele Threads unterstützt. In dem Fall steht jedem Thread in etwa gleich viel Cache zur Verfügung, egal wie diese verteilt wurden. Gleiches gilt für die Zugriffsgeschwindigkeit.
OK, dann haben wir etwas aneinander vorbei geredet.
")
Nochmal zusammengefasst:
SMT oder CMT werden unter Windows 7 nie Leistung kosten, wenn zwei Bedingungen erfüllt sind:
Erstens, das Programm hat ersteinmal grundsätzlich kein Problem mit der hohen Anzahl logischer CPUs, die z.B. ein SMT-Quad besitzt - das ist z.B. in Armed Assault 2 der Fall, hat aber mit der Multithreadtechnik für sich rein gar nichts zu tun. Ein Clarkdale mit 2 Kernen + SMT legt hier durch SMT sogar an Leistung zu, während die 8 Threads eines Nehalem schlicht zuviel sind und etwas Leistung verloren geht - gleiches würde auch bei CMT passieren oder aber einer CPU mit physischen 8 Kernen.
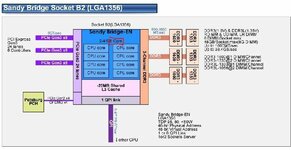
Zweitens, dass Programm darf Threads nicht von vornherein fest an bestimmte logische Prozessoren binden. Das wird genau dann zum Problem, wenn ein Programm weniger Threads als physische Kerne auf der CPU vorhanden sind mitbringt, diese Threads zunächst aber unter Verwendung von SMT/CMT nur an wenige (physische) Kerne verteilt - über SMT brauchen wir nicht reden, klar, aber auch bei CMT würde hier ein gewisser Leistungsverlust auftreten: Beispielsweise würde jetzt der L2 Cache von
zwei Threads genutzt werden, die Zugriffslatenz würde sich für jeden Thread verdoppeln, die durchschnittlich zur Verfügung stehende Bandbreite sowie die Größe ggfls. halbieren. Das kostet zwangsläufig je nach spezifischer Anwendung mal mehr, mal weniger Leistung. Allerdings: Bis auf World of Warcraft in einer älteren Version kenne ich kein Programm, dass solchen Unfug macht.
Abseits dieser kaum (noch) relevanten Einschränkungen kosten SMT/CMT nirgends mehr Leistung. Bestes Beispiel: Der
Clarkdale. Versuch auch mal nur eine einzige Anwendung zu finden, die hier durch SMT Leistung verlieren würde - mit ist keine bekannt.
Selbst mit "intelligenten" Schedulern und spezieller SMT Optimierung lassen sich die teils negativen Performancegewinne von SMT nicht vollständig beheben.
Auch an dich die Aufforderung: Zeig doch auch mal nur einen einzigen Fall, in dem SMT auf einer Dualcore-CPU, also Clarkdale oder Arrandale, Leistung kostet. Das Nehalem/Lynnfield teilweise durch Programme, welche nicht sauber mit 8 Threads umgehen können, behindert werden, ist bekannt - aber hat nichts mit SMT zu tun, ich erwähnte es.
Ich gehe davon aus, dass du einen solchen Fall nicht finden wirst. Aber überzeuge uns vom Gegenteil.


") :
: