2023-03-22T09:39:48.960Z cpu4:2098196)ScsiDevice: 5343: Computing hash based VML id on the string 'NVMe INTEL SSDPE21D280GA PHM2736400AU280AGN 00000001' for the device t10
2023-03-22T09:39:48.960Z cpu4:2098196)NVMe____INTEL_SSDPE21D280GA_____________________PHM2736400AU280AGN__00000001
2023-03-22T09:39:48.960Z cpu4:2098196)ScsiDevice: 5373: Legacy VML ID : vml.05ce413ba297293ac9486f477d0b24e2a5c8932363704a32bef5ab2f02e68e71fc
2023-03-22T09:39:48.960Z cpu6:2098196)VMWARE SCSI Id: Id for vmhba7:C0:T0:L0
0x50 0x48 0x4d 0x32 0x37 0x33 0x36 0x34 0x30 0x30 0x41 0x55 0x32 0x38 0x30 0x41 0x47 0x4e 0x20 0x20 0x49 0x4e 0x54 0x45 0x4c 0x20
2023-03-22T09:39:48.960Z cpu4:2098196)ScsiDeviceIO: 9174: QErr is correctly set to 0x0 for device t10.NVMe____INTEL_SSDPE21D280GA_____________________PHM2736400AU280AGN__00000001.
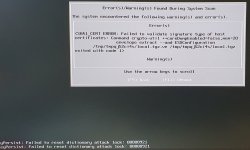
2023-03-22T09:39:48.960Z cpu6:2098196)WARNING: NvmeScsi: 148: SCSI opcode 0x1a (0x459a425fd300) on path vmhba7:C0:T0:L0 to namespace t10.NVMe____INTEL_SSDPE21D280GA_____________________PHM2736400AU280AGN__00000001 failed with NVMe error
2023-03-22T09:39:48.960Z cpu6:2098196)WARNING: status: 0x2 translating to SCSI error H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x24 0x0
2023-03-22T09:39:48.960Z cpu4:2098196)ScsiDeviceIO: 9671: Could not detect setting of sitpua for device t10.NVMe____INTEL_SSDPE21D280GA_____________________PHM2736400AU280AGN__00000001. Error Not supported.
2023-03-22T09:39:48.961Z cpu4:2098196)ScsiEvents: 301: EventSubsystem: Device Events, Event Mask: 40, Parameter: 0x43057c0a2680, Registered!
2023-03-22T09:39:48.961Z cpu4:2098196)ScsiEvents: 301: EventSubsystem: Device Events, Event Mask: 200, Parameter: 0x43057c0a2680, Registered!
2023-03-22T09:39:48.961Z cpu4:2098196)ScsiEvents: 301: EventSubsystem: Device Events, Event Mask: 800, Parameter: 0x43057c0a2680, Registered!
2023-03-22T09:39:48.961Z cpu4:2098196)ScsiEvents: 301: EventSubsystem: Device Events, Event Mask: 400, Parameter: 0x43057c0a2680, Registered!
2023-03-22T09:39:48.961Z cpu4:2098196)ScsiEvents: 301: EventSubsystem: Device Events, Event Mask: 8, Parameter: 0x43057c0a2680, Registered!
2023-03-22T09:39:48.961Z cpu4:2098196)ScsiEvents: 301: EventSubsystem: Device Events, Event Mask: 2000, Parameter: 0x43057c0a2680, Registered!
2023-03-22T09:39:48.961Z cpu4:2098196)ScsiDevice: 5745: Successfully registered device "t10.NVMe____INTEL_SSDPE21D280GA_____________________PHM2736400AU280AGN__00000001" from plugin "NMP" of type 0