Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
ESX / ESXi - Hilfethread
- Ersteller XTaZY
- Erstellt am
Das macht das ganze echt sehr seltsam...
Und das mit den Cores versteh ich echt nicht.
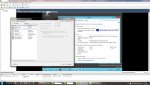
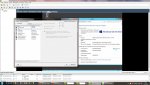
Wenn man 8 Sockets angibt werden im Windows 8 Kerne erkannt...wenn man 1 Socket und 8 Kerne angibt hingegen nur 1 CPU. (siehe Screenshots)
Der erste Screenshot zeigt den schnellen der beiden ESXi Server. Der zweite ist total lahm.
Zum RAID: Ich habe bei Server1 mit 4x300GB SAS @ RAID10 jeweils die Stripe Size (RAID1 & RAID0) auf 128K stehen.
Bei Server2 mit 4x600GB SAS @ RAID10 ebenfalls auf 128K. Kann die schlechtere Performance bei Server2 vielleicht damit zusammenhängen?
Und das mit den Cores versteh ich echt nicht.
Wenn man 8 Sockets angibt werden im Windows 8 Kerne erkannt...wenn man 1 Socket und 8 Kerne angibt hingegen nur 1 CPU. (siehe Screenshots)
Der erste Screenshot zeigt den schnellen der beiden ESXi Server. Der zweite ist total lahm.
Zum RAID: Ich habe bei Server1 mit 4x300GB SAS @ RAID10 jeweils die Stripe Size (RAID1 & RAID0) auf 128K stehen.
Bei Server2 mit 4x600GB SAS @ RAID10 ebenfalls auf 128K. Kann die schlechtere Performance bei Server2 vielleicht damit zusammenhängen?
Anhänge
Zuletzt bearbeitet:
vSphere5 und Xyratex RS-1220
Moin moin,
habe ein nerviges Problem mit unserer Infrastruktur, bzw. mit einem Teil davon.
Wir haben hier ein Cluster mit 2x ESXi und vSphere5, dazu unter anderem ein Xyratex RS-1220 als Storage.
Das Problem ist folgendes, dass Xyratex generiert in fixen Abständen von 5 Minuten folgende Ereignisse:
Wegen Konnektivitätsproblemen kann nicht mehr auf Volume 50c24eba-7fa30e3c-c518-1cc1de6fdbd4
(xyratex-1) zugegriffen werden. Es wird versucht, eine Wiederherstellung durchzuführen. Das Ergebnis liegt
demnächt vor.
Info
05.02.2013 10:29:57
xyratex-1
Der Zugriff auf Volume 50c24eba-7fa30e3c-c518-1cc1de6fdbd4 (xyratex-1) wurde wiederhergestellt.
Info
05.02.2013 10:30:26
So geht das den lieben langen Tag lang, die VMs die auf dem Gerät liegen funktionieren zwar, aber geheuer ist mir das nicht. Zumal hatten wir Probleme bei vmotion. Teilweise dauerte der Kopiervorgang zu lang, einmal brach er sogar ab.
Habe bisher nichts brauchbares gefunden, was ich diesem Problem entgegen setzen könnte. Kennt einer ggf. Paramter, die man unter den "Erweiterten Einstellungen" noch einstellen/ändern könnte oder gar weitere Ideen?
HBAs sind QLogic ISP2432
Die beiden RAID Controller im Xyratex sind RS-LRC-F4-5402E-1024 (74270-02)
Auf den Hosts läuft vSphere5 Enterprise: ESXi-5.0.0-20111104001-standard
Moin moin,
habe ein nerviges Problem mit unserer Infrastruktur, bzw. mit einem Teil davon.
Wir haben hier ein Cluster mit 2x ESXi und vSphere5, dazu unter anderem ein Xyratex RS-1220 als Storage.
Das Problem ist folgendes, dass Xyratex generiert in fixen Abständen von 5 Minuten folgende Ereignisse:
Wegen Konnektivitätsproblemen kann nicht mehr auf Volume 50c24eba-7fa30e3c-c518-1cc1de6fdbd4
(xyratex-1) zugegriffen werden. Es wird versucht, eine Wiederherstellung durchzuführen. Das Ergebnis liegt
demnächt vor.
Info
05.02.2013 10:29:57
xyratex-1
Der Zugriff auf Volume 50c24eba-7fa30e3c-c518-1cc1de6fdbd4 (xyratex-1) wurde wiederhergestellt.
Info
05.02.2013 10:30:26
So geht das den lieben langen Tag lang, die VMs die auf dem Gerät liegen funktionieren zwar, aber geheuer ist mir das nicht. Zumal hatten wir Probleme bei vmotion. Teilweise dauerte der Kopiervorgang zu lang, einmal brach er sogar ab.
Habe bisher nichts brauchbares gefunden, was ich diesem Problem entgegen setzen könnte. Kennt einer ggf. Paramter, die man unter den "Erweiterten Einstellungen" noch einstellen/ändern könnte oder gar weitere Ideen?
HBAs sind QLogic ISP2432
Die beiden RAID Controller im Xyratex sind RS-LRC-F4-5402E-1024 (74270-02)
Auf den Hosts läuft vSphere5 Enterprise: ESXi-5.0.0-20111104001-standard
Zuletzt bearbeitet:
@LaMagra-X
glaube ich nicht, das es an der Size liegt.
Aber zu deinem Coreproblem. Mach mal den Taskmanager auf bei beiden... Dort kanst du im Leistungs-Tab bei CPU mit Rechtsklick in das Diagramm klicken. Im Kontextmenü wählst du dann Diagramm Ändern in Logische Prozessoren.
Das mal bei beiden Versionen probieren. Normal dürfte bei beiden dann ein Achterblock angezeigt werden.
Die Anzeige, die du zeigst (mit den 8 Prozessoren) taucht nämlich erst dann auf, wenn du mehr wie eine CPU nutzt. 8 Sockel in der VM entspricht für Windows genau 8 CPUs. Hast du hingegen nur eine CPU mit 8 Cores, fehlt diese Anzeige dort. Es steht auch nicht! da, das es ein 8 Kernprozessor ist.
PS: auch dürftest du das im Gerätemanager sehen, wenn du den Prozessortab aufklickst. Dort sollten in beiden Versionen auch 8 Einträge vorhanden sein.
glaube ich nicht, das es an der Size liegt.
Aber zu deinem Coreproblem. Mach mal den Taskmanager auf bei beiden... Dort kanst du im Leistungs-Tab bei CPU mit Rechtsklick in das Diagramm klicken. Im Kontextmenü wählst du dann Diagramm Ändern in Logische Prozessoren.
Das mal bei beiden Versionen probieren. Normal dürfte bei beiden dann ein Achterblock angezeigt werden.
Die Anzeige, die du zeigst (mit den 8 Prozessoren) taucht nämlich erst dann auf, wenn du mehr wie eine CPU nutzt. 8 Sockel in der VM entspricht für Windows genau 8 CPUs. Hast du hingegen nur eine CPU mit 8 Cores, fehlt diese Anzeige dort. Es steht auch nicht! da, das es ein 8 Kernprozessor ist.
PS: auch dürftest du das im Gerätemanager sehen, wenn du den Prozessortab aufklickst. Dort sollten in beiden Versionen auch 8 Einträge vorhanden sein.
LichtiF
Enthusiast
- Mitglied seit
- 09.02.2012
- Beiträge
- 1.367
- Ort
- Kleinniedesheim
- Desktop System
- Gondor
- Details zu meinem Desktop
- Prozessor
- Ryzen 9 7950X3D
- Mainboard
- Asus B650E-E Gaming WiFi
- Kühler
- DeepCool AK620
- Speicher
- 2 x16 GB
- Grafikprozessor
- PNY GeForce RTX 4090 XLR8 Gaming Verto Epic-X RGB
- Display
- AOC 34" UWQHD , Dell 23" FullHD
- SSD
- 2 x 2 TB Kingston KC3000
- Gehäuse
- Corsair 5000D Airflow
- Netzteil
- Corsair RM850x Shift
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Firefox
Das macht das ganze echt sehr seltsam...
Und das mit den Cores versteh ich echt nicht.
Wenn man 8 Sockets angibt werden im Windows 8 Kerne erkannt...wenn man 1 Socket und 8 Kerne angibt hingegen nur 1 CPU. (siehe Screenshots)
Der erste Screenshot zeigt den schnellen der beiden ESXi Server. Der zweite ist total lahm.
Zum RAID: Ich habe bei Server1 mit 4x300GB SAS @ RAID10 jeweils die Stripe Size (RAID1 & RAID0) auf 128K stehen.
Bei Server2 mit 4x600GB SAS @ RAID10 ebenfalls auf 128K. Kann die schlechtere Performance bei Server2 vielleicht damit zusammenhängen?
Ich kann es leider hier nicht testen wir haben noch ESXi 4.1 aber ich denke mal das bei Windows 8 / Windows 2012 dort nur die CPUs angezeigt werden und keine Kerne.
Hast du mal am Windows 2012 geschaut ob die Kerne sauber im Taskmanager angezeigt werden ?
Zuletzt bearbeitet:
So jetzt ist mir der "lahme" ESXi auch noch abgekracht ...Fehlermeldung im Screenshot.
Jetzt habe ich das RAID neu gemacht, den USB Port gewechselt und den ESXi neu installiert. Also alles auf 0. Jetzt installiere ich grad wieder Server 2012 mit 1 Sockel & 8 Kernen.
Vielleicht ist mir der ESXi auch abgekracht, weil ich bei der VM mehrmals die Sockel und Kerne verändert habe (!?)
Jep, du hast Recht.
Jetzt trau ich mich allerdings gar nicht es bei der anderen VM zu ändern..nicht dass die auch abkracht
EDIT:
Also leider ist der zweite ESXi auch nach der kompletten Neukonfiguration immer noch total lahm...langsam verzweifel ich
Jetzt habe ich das RAID neu gemacht, den USB Port gewechselt und den ESXi neu installiert. Also alles auf 0. Jetzt installiere ich grad wieder Server 2012 mit 1 Sockel & 8 Kernen.
Vielleicht ist mir der ESXi auch abgekracht, weil ich bei der VM mehrmals die Sockel und Kerne verändert habe (!?)
Aber zu deinem Coreproblem. Mach mal den Taskmanager auf bei beiden... Dort kanst du im Leistungs-Tab bei CPU mit Rechtsklick in das Diagramm klicken. Im Kontextmenü wählst du dann Diagramm Ändern in Logische Prozessoren.
Das mal bei beiden Versionen probieren. Normal dürfte bei beiden dann ein Achterblock angezeigt werden.
Jep, du hast Recht.
Jetzt trau ich mich allerdings gar nicht es bei der anderen VM zu ändern..nicht dass die auch abkracht
EDIT:
Also leider ist der zweite ESXi auch nach der kompletten Neukonfiguration immer noch total lahm...langsam verzweifel ich
Anhänge

Zuletzt bearbeitet:
ascoolasice79
Neuling
Ich habe den Beitrag bereits im ZFS-Thread erstellt und zu spät gemerkt, dass er eigentlich hier rein gehört. Sorry!
Ich habe einen AIO-Homeserver mit dem kostenfreien VSphere Hypervisor. Da ich bisher nur in der Windows-Welt daheim bin, habe auf einer einzelnen SSD einen Datastore erstellt und meinen Dell Perc H710p (ist ein LSI-9265-8i) mit Passthrough an einen Windows Server durchgereicht und ein iSCSi-Target konfiguriert, auf welches ich mit dem ESX zugreife. Das Problem dabei ist, dass ich nach jedem Neustart des ESX diesen Datastore manuell mounten muss, weil meine VMs "unknown" sind, was tierisch nervt. Da die kostenlose Variante keinen Zugriff auf die API zulässt, kann ich das auch nicht per PowerCLI automatisieren.
Hätte ich dieses Problemmit NFS nicht? Hat NFS sonst irgendwelche Vorteile/Nachteile in so einem AIO-Server ggü. iSCSI?
Hat jemand von Euch Erfahrung damit, wie groß die Leistungsunterschiede bei der Hardware sind, wenn der Controller nicht durchgereicht wird, sondern der ESX direkt darauf zugreift? Ich habe das so umgesetzt, weil ich es auf diversen Webseiten so gelesen habe, aber ob es stimmt bzw. best practice ist, kann ich selbst nicht sagen.
Ich habe einen AIO-Homeserver mit dem kostenfreien VSphere Hypervisor. Da ich bisher nur in der Windows-Welt daheim bin, habe auf einer einzelnen SSD einen Datastore erstellt und meinen Dell Perc H710p (ist ein LSI-9265-8i) mit Passthrough an einen Windows Server durchgereicht und ein iSCSi-Target konfiguriert, auf welches ich mit dem ESX zugreife. Das Problem dabei ist, dass ich nach jedem Neustart des ESX diesen Datastore manuell mounten muss, weil meine VMs "unknown" sind, was tierisch nervt. Da die kostenlose Variante keinen Zugriff auf die API zulässt, kann ich das auch nicht per PowerCLI automatisieren.
Hätte ich dieses Problemmit NFS nicht? Hat NFS sonst irgendwelche Vorteile/Nachteile in so einem AIO-Server ggü. iSCSI?
Hat jemand von Euch Erfahrung damit, wie groß die Leistungsunterschiede bei der Hardware sind, wenn der Controller nicht durchgereicht wird, sondern der ESX direkt darauf zugreift? Ich habe das so umgesetzt, weil ich es auf diversen Webseiten so gelesen habe, aber ob es stimmt bzw. best practice ist, kann ich selbst nicht sagen.
Nachtrag:
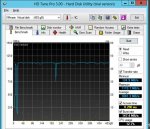
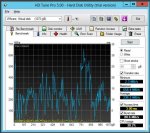
Also wie im Anhang zu sehen ist die Leistung trotz größerer Platten und mehr Arbeitsspeicher (bei sonst identischer Konfig) desaströs!
Server1 ist top..Server2 dagegen die totale Gurke. Und das merkt man auch wenn man ihn benutzt.
Ich kanns mir echt nicht erklären...hoffe ihr habt noch eine Idee wie ich da weiter komme.
Also wie im Anhang zu sehen ist die Leistung trotz größerer Platten und mehr Arbeitsspeicher (bei sonst identischer Konfig) desaströs!
Server1 ist top..Server2 dagegen die totale Gurke. Und das merkt man auch wenn man ihn benutzt.
Ich kanns mir echt nicht erklären...hoffe ihr habt noch eine Idee wie ich da weiter komme.
Anhänge
Teste mal die HDDs einzeln vom lahmen Server. Könnte auch sein, das dort im Raid eine der Platten die Performance drückt...
Sprich mal die Kiste ohne Raid mit vier Single Disks booten und dort dann jeweils nen Tests auf den Datastores machen. Normal müsste da mindestens eine Disk total maue Werte liefern.
Sprich mal die Kiste ohne Raid mit vier Single Disks booten und dort dann jeweils nen Tests auf den Datastores machen. Normal müsste da mindestens eine Disk total maue Werte liefern.
Ne leider nicht...
Was dir aber ggf. helfen würde, du kannst die Events usw. an nen Syslogserver schicken lassen.
Steht ja auch in deiner Meldung, das die Logs auf nem non persistent storage liegen... Somit ist nach nem Boot auch alles wieder weg, was auf den Fehler schließen lassen könnte
Was dir aber ggf. helfen würde, du kannst die Events usw. an nen Syslogserver schicken lassen.
Steht ja auch in deiner Meldung, das die Logs auf nem non persistent storage liegen... Somit ist nach nem Boot auch alles wieder weg, was auf den Fehler schließen lassen könnte
therealJMC
Enthusiast
- Mitglied seit
- 14.01.2010
- Beiträge
- 3.730
Kurze Frage da ich in Sachen Lizenzen nicht auf dem aktuellen Stand bin und jetzt dezent verwirrt bin.
Das vRAM und Physical RAM Limit ist doch seit 5.1 aufgehoben. Wir haben noch 5.0(.0-504890) installiert - wenn wir im Mai die Netapp austauschen wollen wir in einem mehr RAM in die Hosts stecken. Wir haben ne 5er Enterprise Edition
Sollte also Lizenztechnisch eigentlich keine Rolle spielen ob wir die jetzigen 128GB pro Host auf 256GB pro Host hochrüsten, oder? Oder muss ein Update vom ESXi her damit er das "aufgehobene" Memory Limit kennt? In den Lizensierten Features auf dem Host im vSphere Client steht nichts von RAM Limit drin, lediglich die Limitierung auf 8-Wege-SMP hab ich gefunden, sonst nix...
Das vRAM und Physical RAM Limit ist doch seit 5.1 aufgehoben. Wir haben noch 5.0(.0-504890) installiert - wenn wir im Mai die Netapp austauschen wollen wir in einem mehr RAM in die Hosts stecken. Wir haben ne 5er Enterprise Edition
Sollte also Lizenztechnisch eigentlich keine Rolle spielen ob wir die jetzigen 128GB pro Host auf 256GB pro Host hochrüsten, oder? Oder muss ein Update vom ESXi her damit er das "aufgehobene" Memory Limit kennt? In den Lizensierten Features auf dem Host im vSphere Client steht nichts von RAM Limit drin, lediglich die Limitierung auf 8-Wege-SMP hab ich gefunden, sonst nix...
Zuletzt bearbeitet:
Eye-Q
Enthusiast
- Mitglied seit
- 11.07.2004
- Beiträge
- 4.147
- Ort
- Hamburch
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 5 8400F
- Mainboard
- ASRock B650M PG Lightning
- Kühler
- Scythe Mugen 5
- Speicher
- 2x8 GB Kingston Fury DDR5-6000
- Grafikprozessor
- AMD Radeon RX 6700 XT Founders Edition
- Display
- EIZO EV3237
- SSD
- Kingston A2000 M.2 PCIe 500 GB (System) + Kingston NV3 M.2 PCIe 1 TB + WD Blue SN580 M.2 PCIe 2 TB
- Soundkarte
- Asus Xonar DX
- Gehäuse
- Lian Li DAN-Cases A3-mATX
- Netzteil
- be quiet! Pure Power 11 CM 500W
- Keyboard
- Das Keyboard IV Ultimate
- Mouse
- Logitech MX Master 3
- Betriebssystem
- Windows 10 Pro
- Webbrowser
- Vivaldi
Die RAM-Limitierung war nicht auf die Hardware bezogen, sondern auf den an die virtuellen Maschinen zugewiesenen RAM, somit spielt eine Hardware-RAM-Erweiterung keine Rolle. Nur wenn ihr im Zuge dessen den virtuellen Maschinen auch mehr RAM zuteilt, könnte es evtl. ein Limit geben.
Wie viele Enterprise-Lizenzen habt ihr? Pro Lizenz dürfen 64 GB an die virtuellen Maschinen zugeteilt werden, d.h. wenn ihr zwei Hosts á zwei CPUs habt, können insgesamt 256 GB an die laufenden virtuellen Maschinen zugeteilt werden. Bei drei Hosts á zwei CPUs (und 6 Enterprise-Lizenzen) können dementsprechend 384 GB zugeteilt werden, auch wenn in den drei Hosts insgesamt 768 GB drinstecken.
P.S.: das ist 8-Wege-SMP (Symmetric MultiProcessing), nicht 8-Wege-SNMP (Simple Network Management Protocol).
Wie viele Enterprise-Lizenzen habt ihr? Pro Lizenz dürfen 64 GB an die virtuellen Maschinen zugeteilt werden, d.h. wenn ihr zwei Hosts á zwei CPUs habt, können insgesamt 256 GB an die laufenden virtuellen Maschinen zugeteilt werden. Bei drei Hosts á zwei CPUs (und 6 Enterprise-Lizenzen) können dementsprechend 384 GB zugeteilt werden, auch wenn in den drei Hosts insgesamt 768 GB drinstecken.
P.S.: das ist 8-Wege-SMP (Symmetric MultiProcessing), nicht 8-Wege-SNMP (Simple Network Management Protocol).
therealJMC
Enthusiast
- Mitglied seit
- 14.01.2010
- Beiträge
- 3.730
Mit dem P.S. hast du recht, kommt davon wenn man nebenbei noch im Nagios rumwuselt... Ausserdem ist hier schon Karneval
Richtig - aber es ging auch eigentlich um den vRam. Was nützen mir 256GB oder mehr RAM im Host wenn ich nur 128GB zuweisen kann
Wir haben 2 Maschinen mit je 2 CPUs - also 4 Lizenzen. Da wir aber auf 5.1 updaten wollen in einem (wegen 32-Wege-SMP pro VM) entfällt doch das vRAM Limit, richtig? "vRAM Entitlement Unlimited" sagt das Whitepaper zu 5.1.
Richtig - aber es ging auch eigentlich um den vRam. Was nützen mir 256GB oder mehr RAM im Host wenn ich nur 128GB zuweisen kann
Wir haben 2 Maschinen mit je 2 CPUs - also 4 Lizenzen. Da wir aber auf 5.1 updaten wollen in einem (wegen 32-Wege-SMP pro VM) entfällt doch das vRAM Limit, richtig? "vRAM Entitlement Unlimited" sagt das Whitepaper zu 5.1.
so schaut es aus. Mit der 5.1er gibts diese Einschränkung nicht mehr... Was mich halt selbst etwas wurmt, das VMware den Mist nicht auch mit nem Update aus den 5.0ern rausgenommen hat. Denn der 5.0er Key berechtigt automatisch direkt auf 5.1. Somit ist das Festhalten am Limit irgendwie ziemlicher Quark.
Wichtig beim Update auf 5.1 ist, du musst den vCenter Server auf auf 5.1 bringen... Was ne "Menge" Arbeit ist, da sich beim vCenter einiges geändert hat. Da man nun dediziert auf diesen SSO Quatsch aufbaut. Und es somit nicht einfach mal fix damit getan ist, den Installer durchzuklicken.
PS: was willst du mit 32 Wege SMP pro VM? Das macht irgendwie keinen Sinn")
Theoretisch dürfte auch ohne 5.1 schon die volle Anzahl an Cores in einer einzigen VM funktionieren. Nämlich mit einer oder zwei vCPUs und x Cores. Je nach CPU Ausbau des Hosts. Das geht sogar schon mit der 4.1 offiziell und mit der 4.0 inoffiziell (durch händisches Bearbeiten der vmx für die Coreconfig)
Noch dazu kann ich nur empfehlen nicht mehr vCPUs (oder vCPU-Cores) einer einzigen VM zuzuteilen, wie physisch pro steckender CPU vorhanden sind. Weil du dir damit nämlich ein Performanceverlust erkaufst, die Skalierng ist je nach Lastzustand des Hosts nämlich äußerst mau.
Wichtig beim Update auf 5.1 ist, du musst den vCenter Server auf auf 5.1 bringen... Was ne "Menge" Arbeit ist, da sich beim vCenter einiges geändert hat. Da man nun dediziert auf diesen SSO Quatsch aufbaut. Und es somit nicht einfach mal fix damit getan ist, den Installer durchzuklicken.
PS: was willst du mit 32 Wege SMP pro VM? Das macht irgendwie keinen Sinn
Theoretisch dürfte auch ohne 5.1 schon die volle Anzahl an Cores in einer einzigen VM funktionieren. Nämlich mit einer oder zwei vCPUs und x Cores. Je nach CPU Ausbau des Hosts. Das geht sogar schon mit der 4.1 offiziell und mit der 4.0 inoffiziell (durch händisches Bearbeiten der vmx für die Coreconfig)
Noch dazu kann ich nur empfehlen nicht mehr vCPUs (oder vCPU-Cores) einer einzigen VM zuzuteilen, wie physisch pro steckender CPU vorhanden sind. Weil du dir damit nämlich ein Performanceverlust erkaufst, die Skalierng ist je nach Lastzustand des Hosts nämlich äußerst mau.
Zuletzt bearbeitet:
therealJMC
Enthusiast
- Mitglied seit
- 14.01.2010
- Beiträge
- 3.730
Also es stecken je Server je 2 E7-4830 - 16 Threads pro CPU = 32 Threads (16 Kerne) pro Server. Der SQL-Server braucht gerne mal etwas mehr, daher wollen wir von 8 Threads auf 12 oder 16 hoch gehen. Oder meinst du tatsächlich nicht mehr vCPU-Cores als Reale Cores auf einer CPU vorhanden sind (und nicht Threads)? Eigentlich gehts nicht um 32-Wege-SMP sondern um mehr als 8-Wege-SMP
Das Upgrade der Hosts und auch des vCenter wird (sehr wahrscheinlich) IBM übernehmen die (wahrscheinlich) auch die neue Storage Lösung aufziehen. (Wir haben uns noch nicht zwischen IBM und Netapp Metrocluster entschieden) Das würde also an mir vorbeigehen wenn wir bei der IBM Lösung bleiben.
Das Upgrade der Hosts und auch des vCenter wird (sehr wahrscheinlich) IBM übernehmen die (wahrscheinlich) auch die neue Storage Lösung aufziehen. (Wir haben uns noch nicht zwischen IBM und Netapp Metrocluster entschieden) Das würde also an mir vorbeigehen wenn wir bei der IBM Lösung bleiben.
Also ich bin echt am verzweifeln.
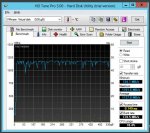
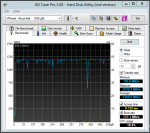
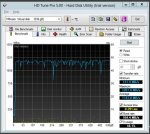
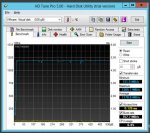
Ich habe nun alle 4 HDDs einzeln getestet...alle liegen auf demselben hohen Leistungsniveau. Alle VMs liefen damit sehr flüssig und schnell. Keinerlei Probleme.
Siehe dazu auch die Screenshots.
Nur wenn ich dann aus den 4 HDDs wieder ein RAID10 mache wirds total lahm...was kann das denn sein???
Ich habe nun alle 4 HDDs einzeln getestet...alle liegen auf demselben hohen Leistungsniveau. Alle VMs liefen damit sehr flüssig und schnell. Keinerlei Probleme.
Siehe dazu auch die Screenshots.
Nur wenn ich dann aus den 4 HDDs wieder ein RAID10 mache wirds total lahm...was kann das denn sein???
Anhänge
therealJMC
Enthusiast
- Mitglied seit
- 14.01.2010
- Beiträge
- 3.730
Hast du im Controller sowohl die Platten Caches als auch den Controller Cache angemacht?
Edit:
Und die Initialisierung abgewartet?
Edit:
Und die Initialisierung abgewartet?
Steggi
Enthusiast
- Mitglied seit
- 31.12.2010
- Beiträge
- 3.489
Ich habe nun alle 4 HDDs einzeln getestet...alle liegen auf demselben hohen Leistungsniveau. Alle VMs liefen damit sehr flüssig und schnell. Keinerlei Probleme.
Siehe dazu auch die Screenshots.
Die Ergebnisse des Screens sehen mir aber sehr danach aus, als währen die Daten nur aus dem Controller-Cache und nicht direkt von der Platte gelesen worden. 1,2GB/s halte ich für ne HDD für recht unrealistisch
Also es stecken je Server je 2 E7-4830 - 16 Threads pro CPU = 32 Threads (16 Kerne) pro Server. Der SQL-Server braucht gerne mal etwas mehr, daher wollen wir von 8 Threads auf 12 oder 16 hoch gehen. Oder meinst du tatsächlich nicht mehr vCPU-Cores als Reale Cores auf einer CPU vorhanden sind (und nicht Threads)? Eigentlich gehts nicht um 32-Wege-SMP sondern um mehr als 8-Wege-SMP
Dann dreh die SQL Büchse auf 2 vCPUs mit je 8 Cores. Das kostet zwar was Leistung aufgrund der NUMA Node Problematiken, kommt in Summe aber immernoch schneller.
Sollte auch mit der 5.0er Version gehen, denke ich. Hab ich aber persönlich nie getestet. Weil für mich so eine Konstellation wenig Sinn macht, wo eine einzige VM die CPUs voll an die Wand fahren kann. Denn da braucht man nicht virtualisieren. -> Meine Meinung. Dann lieber die SQL Kisten native auf den Host/die Hosts packen.
Bei SQL Servern bringt dir ja auch allgemein die Snapshots und Backups auf Snapshotbasis wenig bis nichts, falls es mal richtig kracht.
Ähnliche Sicherheiten und schnelles Recovery bekommt man ja auch hin, wenn man die Büchsen nativ abzieht und das Image irgendwo ablegt. Im Extremfall einfach das Image drüber bügeln und das aktuellste Backup wieder drauf -> läuft.
Die Ergebnisse des Screens sehen mir aber sehr danach aus, als währen die Daten nur aus dem Controller-Cache und nicht direkt von der Platte gelesen worden. 1,2GB/s halte ich für ne HDD für recht unrealistisch
Jupp, in der Tat sind das unrealistische Werte.
Was spuckt denn CrystalDiskMark an Werten für die Platten aus?
Ggf., wenn es nicht zu viel Aufwand ist, könnte man die 600er mal mit den 300ern tauschen, sprich gucken ob die 300er auch ähnliche Performanceprobleme auf dem Server bereiten. Sowie den Gegencheck, ob die 600er vllt in dem anderen Server richtig laufen. -> würde zumindest Aufschluss geben, ob der Server/Controller vllt rumspackt.
Zuletzt bearbeitet:
Hast du im Controller sowohl die Platten Caches als auch den Controller Cache angemacht?
Edit:
Und die Initialisierung abgewartet?
Wenn das RAID nicht initialisiert wäre könnte ich unter ESXi5 ja keinen Datastore erstellen.
@therealJMC
Ja, schon.
Aber ich habe es auch unter RAID10 so gebenched (ist ja nur fürs Protokoll) und da sah es sehr schlecht aus (siehe Posts vorher).
@fdsonne
Den Controller aus dem anderen Server1 (mit den 300er HDDs) habe ich auch schon eingebaut und dieselben schlechten Werte erhalten...
Ja,...habe das RAID10 mit dem manuellen LSI Wizzard erstellt. Jeweils 2 Groups mit je 2 HDDs und dann lässt sich RAID10 auswählen. Da habe ich dann Stripe Size auf 128K gestellt, Cache Enable und Always Write Back (wie beim anderen Server eben auch).
Das Initialisieren geht dann ja in 5 Sekunden...
Zuletzt bearbeitet:
therealJMC
Enthusiast
- Mitglied seit
- 14.01.2010
- Beiträge
- 3.730
Wenn das RAID nicht initialisiert wäre könnte ich unter ESXi5 ja keinen Datastore erstellen.
Nicht ganz... BGI könnte da durchaus zuschlagen anfangs
Background initialization (BGI) is the process of copying data from primary to
secondary disks in a mirrored volume. The Integrated RAID firmware starts BGI
automatically as a background task when it creates a volume. The volume remains in
the Optimal state while BGI is in progress.
Daher meine Frage
Nicht ganz... BGI könnte da durchaus zuschlagen anfangs
Daher meine Frage
Hmm...das ist dann allerdings eine gute Frage.
")
Aber im Controller-Menü müsste man dann ja sehen, dass der Initialisierungsprozess noch läuft, oder!?
EDIT:
Jetzt mal ne ganz blöde Vermutung: Kann es sein, dass es an einer 1000GB/1TB Partition liegen kann?
Denn: Ich habe jetzt grad nochmal dasselbe Spiel gemacht und ein RAID10 mit allen 4 HDDs erstellt, der VM aber nur 900GB statt wie bisher 1000GB zugeteilt und siehe da, das System läuft schnell.

Anhänge
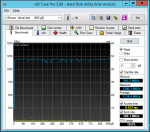
Zuletzt bearbeitet:
therealJMC
Enthusiast
- Mitglied seit
- 14.01.2010
- Beiträge
- 3.730
Dann dreh die SQL Büchse auf 2 vCPUs mit je 8 Cores. Das kostet zwar was Leistung aufgrund der NUMA Node Problematiken, kommt in Summe aber immernoch schneller.
Sollte auch mit der 5.0er Version gehen, denke ich. Hab ich aber persönlich nie getestet. Weil für mich so eine Konstellation wenig Sinn macht, wo eine einzige VM die CPUs voll an die Wand fahren kann. Denn da braucht man nicht virtualisieren. -> Meine Meinung. Dann lieber die SQL Kisten native auf den Host/die Hosts packen.
Bei SQL Servern bringt dir ja auch allgemein die Snapshots und Backups auf Snapshotbasis wenig bis nichts, falls es mal richtig kracht.
Ähnliche Sicherheiten und schnelles Recovery bekommt man ja auch hin, wenn man die Büchsen nativ abzieht und das Image irgendwo ablegt. Im Extremfall einfach das Image drüber bügeln und das aktuellste Backup wieder drauf -> läuft.
Die Hosts haben Failover - im Normalzustand läuft auf dem einen auch neben dem SQL-Server nur eine weitere Maschine. Der Rest läuft auf der anderen Maschine. Das war hier aber alles schon so als ich meinen neuen Job hier angetreten hab
Das bekommst du halt mit direkter Hardware nicht so ohne weiteres hin. Die Punktuelle Last (aufgrund der wir die Maschine anpassen wollen) ist aber eh Abends wenn gewisse Tasks laufen die den Server so auslasten, da wäre auch eine Beeinflussung der anderen Hosts nicht weiter schlimm zu der Zeit.
Wir wollten eher auf 12 Threads - also dann auf 2 vCPUs mit 6 Kernen. Damit kommt man dann auch nicht in die Lage, dass eine VM die Kiste komplett plätten kann. Die Datenbanken liegen als Mappings ja auf den LUNs - Snapmanager springt stündlich an und abends gibts dann ne Vollsicherung mittels Backup-Software.
therealJMC
Enthusiast
- Mitglied seit
- 14.01.2010
- Beiträge
- 3.730
So der Rest der HW ist heute eingetroffen.
Habe nun mein altes Gehäuse ausgeräumt und angefangen einzubauen.
Jedoch bin ich beim Studieren der Installationsanleitung darauf gestoßen, dass ich nen Xeon mit Graphik brauche oder ich bau eine Graka ein.
Ich weiß echt nicht, wie ich das übersehen habe aber beim Zusammenstellen der Hardware hatte ich was gelesen das für das X9SAE-V keine CPU mit GPU benötigt wird.
Entweder habe da was falsches gelesen (evtl. ein anderes MoBo) oder was auch immer.
Eine Graka habe ich noch (GTS8800) was für die Installation reichen sollte. Wenn der Server mal läuft brauche ich die ja auch nicht mehr.
Wie ist das aber später, wenn ich mal ein Update vom ESXi fahren will oder sonst was.
Wann müsste ich zwangsweise wieder an die Hardware ran und brauch ne Anzeige auf dem Monitor?
Habe nun mein altes Gehäuse ausgeräumt und angefangen einzubauen.
Jedoch bin ich beim Studieren der Installationsanleitung darauf gestoßen, dass ich nen Xeon mit Graphik brauche oder ich bau eine Graka ein.
Ich weiß echt nicht, wie ich das übersehen habe aber beim Zusammenstellen der Hardware hatte ich was gelesen das für das X9SAE-V keine CPU mit GPU benötigt wird.
Entweder habe da was falsches gelesen (evtl. ein anderes MoBo) oder was auch immer.
Eine Graka habe ich noch (GTS8800) was für die Installation reichen sollte. Wenn der Server mal läuft brauche ich die ja auch nicht mehr.
Wie ist das aber später, wenn ich mal ein Update vom ESXi fahren will oder sonst was.
Wann müsste ich zwangsweise wieder an die Hardware ran und brauch ne Anzeige auf dem Monitor?
@all
Also meine beiden ESXi5.1 laufen nun beide schnell. Danke an alle für eure Tipps und Hilfen!
Dann noch mal eine grundsätzliche Frage zur Zuteilung von CPU Kernen:
Wenn ich nun einen 8-Core Xeon E5-2450 im Server verbaut habe...was ist dann im ESXi für die virtuelle Maschine am besten in Bezug auf Performance:
1 Sockel & 8 Kerne
oder
8 Sockel & 1 Kern
Nachvollziehbar wäre erste Variante...aber ich meine dass das System spürbar flotter läuft, wenn man die zweite Variante wählt.
Im Task-Manager werden bei beiden Varianten 8 Cores angezeigt.
Gibts das von VMWare eine Richtlinie?!
VG
Also meine beiden ESXi5.1 laufen nun beide schnell. Danke an alle für eure Tipps und Hilfen!
Dann noch mal eine grundsätzliche Frage zur Zuteilung von CPU Kernen:
Wenn ich nun einen 8-Core Xeon E5-2450 im Server verbaut habe...was ist dann im ESXi für die virtuelle Maschine am besten in Bezug auf Performance:
1 Sockel & 8 Kerne
oder
8 Sockel & 1 Kern
Nachvollziehbar wäre erste Variante...aber ich meine dass das System spürbar flotter läuft, wenn man die zweite Variante wählt.
Im Task-Manager werden bei beiden Varianten 8 Cores angezeigt.
Gibts das von VMWare eine Richtlinie?!
VG