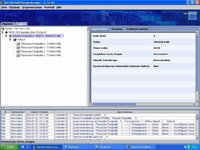
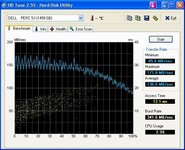
ich sag mal: ein für den LSI support. muss doch möglich sein

@€dit: aus dem handbuch:
Caution: If MegaRAID Storage Manager software detects that a disk
drive in a virtual disk has failed, it makes the drive offline.
If this happens, you must remove the disk drive and replace
it. You cannot make the drive usable for another
configuration by using the Mark physical disk as missing
and Rescan commands.
@€dit2: haha

ich hab die lösung!! bei mir stand die gedroppte platte als unconfigured and good (foreign) in der liste. so: die ursprüngliche hotspare (ID7) hab ich als offline und dann als missing markiert ->raid degraded popup. danach storage manager neu gestartet und die foreign platte per replace option dem raid wieder hinzugefügt! sah dann wieder normal aus aber ich wusste dass es nicht normal ist ->danach den consistency check ausgeführt. der quasi "rebuild" läuft (natürlich zig fehler gefunden). man sollte vor dem wiedereinbinden also nen vorangehenden consistency-check durchfühen um nachher nicht müll auf dem array zu haben. ID7 ist nun wieder hotspare.
einziges problem: bei jetzigen rebuild hab ich keine redudanz. aber wurscht. backup für den notfall liegt im schrank


denke wenn man keine hotspare hat lässt sich die hdd nach abstöpsen (-> an der intel ichXr anschließen und die platte dann eben in windoof erkennenlassen) ->booten ->ausschalten ->anschließen ->booten direkt wieder in den verbund einfügen. danach nur nen cosinstency-check und alles ist wieder im lot. hier war es bei mir fast schon nen nachteil ne hotspare zu haben

na egal. dafür hab ich nen direkten automatischen ersatz beim ausfall.
denke ich hab auch den grund für das droppen gefunden. der controller wird wohl wegen zuviel untätigkeit nen partrol read durchgeführt haben und dabei is nen fehler aufgetreten ->drive offline und missing gesetzt ->degraded. laut dem seagate tool ist die platte aber fehlerfrei (smart als auch beim langem test). oder der dell findet sachen die das tool nicht findet!?
werd mich mal gleich damit beschäftigen partol read und nen sinnvollen scheduled consistency-check zu planen und auch zu programmieren.
@kabelmaster: denke wenn du keine hotspare brauchst kannst die platte einfach manuell im fall der fälle (degraded) wieder dem array hinzufügen. ich würd mir jedoch dann gedanken über nen wöchentlichen consistency-check machen. was ich von patrol read halten soll: k.a. eigentlich sinnvoll aber eben nicht mehr wenn es mir mal eben platten ohne grund aus dem array wirft.
@€dit2: die platen wurden wohl zu warm. 60°C+ waren nedd gut da kühlungsausfall. zwei hatten später auch fehler im seagate tool. welchen genau hats mir aber nciht gesagt. ersatzplatten laufen wie auch die "alten2 verbleibenden nun im neuen case bisher fehlerfrei (26.11.2008)





")



 Alles wieder so wies war. Hab zur Sicherheit nochmal nen Test drüberlaufen lassen und es gab keine Nichtübereinstimmungen mehr nach dem zuerst erfolgten Durchlauf!
Alles wieder so wies war. Hab zur Sicherheit nochmal nen Test drüberlaufen lassen und es gab keine Nichtübereinstimmungen mehr nach dem zuerst erfolgten Durchlauf! Glück gehabt würde ich sagen
Glück gehabt würde ich sagen ")