Intelfreak
Banned
Wers glaubt.
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
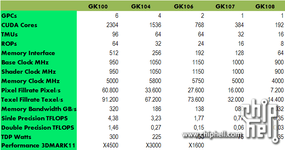
scully, das war aber nicht die Ursprungsspeku. Ende 2011 geisterte mal was von ~768 ALUs für GK104 rum. Und 1536 für den GK100")
")
 Es macht aber den Eindruck als hält NV an der üblichen Aufteilung fest.
Es macht aber den Eindruck als hält NV an der üblichen Aufteilung fest.Übrigens, die Radeons in Sachen Größe zu vergleichen ist nach wie vor unsinn. Es sind nach wie vor Vector ALUs.
Namensschemaänderungen höchstens in Form von dieser ominösen GTR, wobei ich eher glaube dass das R für Refresh stehen wird.

Warum lässt man überhaupt die Hotclocks wegfallen, wofür soll das gut sein.
Das stimmt allerdings.
Wobei ich persönlich davon ausgehe, das man nichtmal ansatzweise 50% Fläche pro ALU sparen kann, wenn man die Hotclocks weglässt. Mit 28nm schafft man wohl ca. 512 1D ALUs inkl. Hotclocks auf die halbe fläche zu bringen. Man baut aber drei mal so viele ALUs, wie es derzeit ausschaut. Ich denke nicht, das man diese Mehrfläche durch den geringeren Takt 1:1 ausgleichen kann. Das heist denke ich, das das NV Teil so oder so wieder "riesig" sein wird. Trotz der Zahlenmäßigen unterlegenheit gegen AMD (sofern es stimmt)
Warum lässt man überhaupt die Hotclocks wegfallen, wofür soll das gut sein oder skaliert der Chip nicht gut wenn die Einheiten verdoppelt werden?
Früher ist man von 1024-1D Shader mit Hotclock in 28nm ausgegangen, das hätte vollkommen gereicht.
Aber die Architektur hat doch keine hohen Taktraten...
Bei GT200 (240 Shader) > GF100 (480 Shader) hats auch geklapt
Edit:
Durch 28nm sollte man doch die Leistungsaufnahme bei der Shader verdopplung gut im griff haben, 32nm wird übersprungen, der umstieg von 40 > 28nm wird groß ausfallen.
Aber die Architektur hat doch keine hohen Taktraten...
Bei GT200 (240 Shader) > GF100 (480 Shader) hats auch geklapt
Je höher der Takt je höher der Verbrauch(exponentiell gesehen)

The -400 is said to be an “8 group” device, the -335 described as “7 group’
Instead of being forced to fuse off large blocks of shaders as a minimum, it looks like they can now do much smaller chunks.
This should greatly improve yields, allow for endless SKU variations, and generally make things better. Of course, it comes at a die size penalty, but after the last learning experience, it would be foolish to do otherwise
This should greatly improve yields, allow for endless SKU variations, and generally make things better.
ich raff nur nicht was dann eine 8er und eine 7er Gruppe sein soll
Na ... 780 und 880

Hier geht es darum, dass man die Teildeaktivierung bestimmter Einheiten in der neuen Generation wohl feiner durchführen kann, spricht nur ein Haus abreissen, nicht den ganzen Block.
ob das so einen immensen Vorteil ergibt bei teildefekten ChipsOf course, it comes at a die size penalty
Am ehesten würd ich vermuten das man eben die -400 aus Vollausbau bezeichnet, bei dem alle Shader funktionieren, und die -335 mit teildeaktivierten/teilfunktionsunfähigen.
...
Und im Laufe der Zeit verbessert sich die Ausbeute des Vollausbaus...