Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Er empfahl bei Temperaturproblemen trefi in den genannten steps zu senken. So wie ich das verstehe gibt es unterschiedliche trefi max Empfehlungen die auf einem Rundungsfehler beruhen
6200C30-37-37 auf 1.32-1.34v , mit 1.35v ist es genug.
// EDIT: ~ ich denke 6200C30-36 müsste mit ungefähr 1.4 VDDQ, 1.42 VDD_MEM noch durchgehen. 6000 C30-36 wäre dann auf 1.3v. 512 RFC passt.
Du hast tWR vergessen.
EDIT:
VDDP auf 1.1v max ~ (solltest du ODT und RTT übernehmen wollen)
1.15v brauchst du nicht mit GDM und brauchst du nicht auf 6200MT/s.
Schadet nur Signal Quality.
Ja, instabil.
Autokorrektur ist sehr vorbildlich diese Generation.
Um den 4? Stunden TM5 bei 64Gb kommst du nicht herum.
Als absolutes minimum.
// Ich möchte ein Screenshot sehen. Stabil oder instabil.
Autocorrection würde sowohl die Bandbreite als auch die Latenz verfälschen~.
Hmmm
Ich denke ist schon mit einbegriffen, wie bei 65535 schon mit einbegriffen.
Ich denke auch dass es wegen den reserve'd tPPR bits ist - weswegen es stabiler rauskommt 🤔 unsicher, es fehlt die Logik.
Würde vorerst aber immer auf 65535 bleiben, bzw runterskalliert.
Sollte AMD endlich FineGranularityMode einschalten, dann würde ich die Formel leicht abändern.
Lade dir auf ASUS das ECO 170W profil - FakeECO
Fals die Boardpartner es auf Mid-Range Boards noch integriert haben.
Exclusive ASUS PBO feature.
CO möchtest du (blind) nicht unter -8 bzw -10 haben
VID Autokorrektur existierst auf der CPU.
Loadbalance Frequency Autokorrektur existiert auf der CPU
Cache PPR (PostPackageRepair) existiert auf der CPU & auf den RAM-Sticks
Clock Gating für FCLK und SystemClock existiert auf der CPU gegen Instabilität.
Jedes dieser Features wird dir bei dem Tracking von Spannung/Frequenz/Stabilität Probleme bereiten.
Jedes dieser Features kann schneller als 6ms ausgeführt werden.
Keines der Consumer-Tools kann unter 5ms sich updaten und Autokorrektur (visuel) feststellen.
Danke
Komplett übersehen. Er/Sie rennt wohl UCLK=MCLK/2
Vorerst in Ordnung sowieso instabil~
Ne , bin dämlich.
Alles ok , ZT zeigt UCLK = MCLK.
Liegt an der Autokorrektur bzw zu hohem FCLK.
Abseits das Northbridge sich in Integers synchronisiert (unwichtig)
Leider schafft es das nicht corecycler zu bemerken.
Autocorrection is too good.
Ich hatte 1usmus eine systematische Methode durchgegeben,
Aber du kannst die Stabilität davon nicht erkennen.
Den wenn es wirklich crasht, ist es vieel zu spät. Wäre ~+50mV zu spät.
Man kann es mit RopBench bemerken, ab wann die Kerne in 1ms pooling beginnen sich instabil zu verhalten.
Jedoch Teilen alle Kerne pro Seite (L of L3$ , R of L3$) die Spannungen untereinander
Und bekommen sie alle gleichzeitig von einer Rail, geteilt als LDO.
Da sie die Spannung zwischen den Kernen seit Matisse? auch teilen können ~ wird gegenkorrigiert und ein Kern kann den anderen hinunterziehen.
// Die X core crashed reports wären somit zwecklos bzw ohne einen Verwendungsgrund. Im schlechtesten Fall, sogar irreführend.
Es gibt dann noch ein Per CCD 2 CCD Delta , abseits des Inter-CCD Deltas.
Für Freq (straps) & VID.
Well done !
Eventuell die unter 8ns Kerne leicht grüner. Same-core 2 same-core roundtrip delay.
Kannst du mir ganz kurz ein Zentimings screenshot von deinem 7800X3D durchgeben ?
Well done !
Eventuell die unter 8ns Kerne leicht grüner. Same-core 2 same-core roundtrip delay.
Kannst du mir ganz kurz ein Zentimings screenshot von deinem 7800X3D durchgeben ?
Ah ok
Dann schaue ich unterwegs drüber. (wäre erst gegen Mitternacht wieder zu Hause)
Ich hätte eine Idee was genau AMD versucht hinzubekommen . . . Sollte Ryzen Master wirklich MemoryPresets haben und nicht zb ASUS.
Aber es ist dennoch unlogisch dass RAS startet bevor RCD endet. Selbst wenn RAS aus welchem absurden Grund auch immer nicht auf dem DIMM stattfindet.
Wenn du etwas Freizeit hättest könntest du dann beide Optionen gegenvergleichen. (SiSoftware Sandra InterThread, benchmate usw)
Nun mit einem sauberen OS.
Ich hab leider kein DDR5 System mehr~
@Veii
Ich haben mich an deinen Rat gehalten und step für step die Timings weiter angepasst.
Leider bin ich aus Zeitgründen noch nicht so weit wie ich sein wollte, aber ich finde die Resultate sprechen schon für sich.
Zusätzlich 2h memtest86 ohne Fehler.
tCL = 28 hatte ich kurzzeitig aktiv, bekam dann nach einiger Zeit allerdings boot errors.
tRFC bekomme ich aktuell auch nicht wirklich unterhalb von 448, obwohl es A-Dies sein sollten
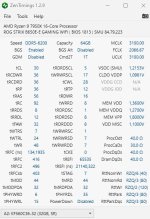
BIOS Setting:
VSOC = 1,3
MEM VDD = 1,45
MEM VDDQ = 1,35
MEM VPP = 1,8
GDM = Off
MCR = Off
Power Down Mode = Off
An die Widerstände ProcDqDA sowie DramDqDs habe ich mich noch nicht getraut, da ich deren Einfluss nicht kenne.
Jemand eine Idee, was ich anpassen sollte, um tCL = 28 zum laufen zu bekommen?
Zip Laden, CMD Öffnen, MicroBenchX.C2CLatency.exe rüber ziehen ins offene CMD Fenster.
Die Daten dann online auf der verlinkten Webseite einfügen (angefangen am X und am Ende das X auch mitnehmen) dann bekommt man am Ende die farbliche Auflistung in der Tabelle ausgegeben (auf generate grid klicken), wie hier im Bild zu sehen:
Hab meinen 78X3D mit RAM OC mal getestet, sieht dann im Ergebnis so aus:
Homogenität oder Heterogenität ist nur die Auflistung wie die Daten angezeigt werden sollen.
Bei Heterogenität werden die nicht Gleichen hervorgehoben, bei Homogenität die Gleichen.
Also damit man besser unterscheiden kann wo es "hakt" (nehme ich nun einfach mal an, mich kümmert es nicht )
Anzeige mit "Homogenität"
Anzeige mit "Heterogenität"
Also als Ganzes gesehen ist es recht "gut"
Die Betrachtung der Kerne einzeln ist dann eher "schlecht" wenn die Abweichung zu hoch ist im Vergleich zu den anderen Kernen.
Beitrag automatisch zusammengeführt:
Ergänzend zum Post oben:
Die intercore Latenzen sind auch abhängig von den sleep States, wenn erst ein Kern geweckt werden muss, braucht dieser länger zum reagieren als ein aktiver Kern (logisch irgendwie).
Soll heißen, wenn ein Powerplan z.B. ein Kern inaktiv setzt ist die Zeit entsprechend höher (cppc / cppc preferred cores * "ETC").
Mit * "ETC" meine ich in diesem Fall, dass die Kerne mit höheren Latenzen wohl vom System / Powermanagement schlafen gelegt werden und dann erst aufgeweckt, wenn Last anliegt.
Das Problem der Genauigkeit, liegt nicht in dem Programmierer bzw die Art zu tracken (hoffentlich)
Es liegt an der Idee des Programmierers.
Die sample Zeit ist kurz
Es rundet
Generell funktionieren user inputs nicht
Einfach alt und ein fork Projekt.
Ich würde hier ein converter bevorzugen bzw überlegen wie weit SiSandra von dem user-projekt liegt.
Den das originale Userprojekt benützt womöglich nicht die korrekten AMD ROP Command's (bitte um Korrektur sollte ich falsch liegen)
Jedoch rechnet es die deviations mit ein.
Dem CapFrame Tool , fehlt die Genauigkeit und habe programier bugs, worin es run-2-run andere Werte anzeigt. Bzw diese samples nicht zusammenzählen kann.
Ich weiß es nicht ansonsten würde ich es selber richten ~ jedoch leider nicht funktional bzw auf Auto nicht gut-genug.
Die intercore Latenzen sind auch abhängig von den sleep States, wenn erst ein Kern geweckt werden muss, braucht dieser länger zum reagieren als ein aktiver Kern (logisch irgendwie).
Soll heißen, wenn ein Powerplan z.B. ein Kern inaktiv setzt ist die Zeit entsprechend höher (cppc / cppc preferred cores * "ETC").
Mit * "ETC" meine ich in diesem Fall, dass die Kerne mit höheren Latenzen wohl vom System / Powermanagement schlafen gelegt werden und dann erst aufgeweckt, wenn Last anliegt.
Es tut mir leid,
Aber genau das ist nicht korrekt.
Aus 3 Gründen:
~ Powerplan und fixed clock / sleep states hinweiß von dem Dev liegt dem IPC tester bei. Welches ein langes/komplexes Thema wäre, aber wir dafür RopBench haben
~ Ein inter-core bzw interthread latency test läuft im besten Fall auf die Architektur's vorgelegte Instructions. Sollte es das nicht, hast du vor-konvertier steps von dem Branch Predictor, welches nicht nur die Latenz verfläschen, sondern auch die Geschwindigkeit bzw die Instruction als solches in kleine Teile zerstückeln ~ um sie effektiever zu Bearbeiten. OpCache & BranchPrediction Thema;
~ Kein core 2 core latency test sollte als "single Iteration" laufen. Die CPU in einem abseits normalen zustand zu versetzen (inkludiert safe-mode) wäre unüberlegt und stört das eigentliche Ziel weswegen du diesen Test rennst. Und bei 50000 core-blocks (samples) ist es semi Irrelevant ob nun 5 oder 10 davon aka 0.001% zu langsam sind da die Kerne aufwachen müssen.
Desweiteren braucht Zen seit dem CPPC existiert * (intern), kein OS zugriff und keine speziellen Powerpläne oder Treiber um zu funktionieren.
Niemand wartet auf das langsame OS um "load" zu verteilen.
* Es ist eher anders rum. CPPC ist eine funktion welches dem OS erlaubt die FIT ratings auszulesen und dem Scheduler erlaubt schneller fokussiert daten zu verteilen ~ anstelle dass man auf dem BranchPredictor (your turn) warten muss. Und dann unnötigerweise den Platz und die Zeit für solch rudamentale Arbeit wie load-scheduling verschwendet.
Das selbe gilt für Intel und AMD.
BufferQueue ist nur so groß, und was die BufferQueue füttert, hat ebenso einen Delay
Jedenfalls, wenn man korrekte Instructionsets absendet ~ bekommt man korrekte wiederholbare Ergebnisse
Ob wir auf @Kelutrel warten müssen (@RedF magst du für mich auf OCN Taubenpost spielen ~ er sollte mit dem MemTest bzw Interthread code schon lange fertig sein)
Werden wir noch sehen müssen.
Ansonnsten müsste man aus dem SiSoftware Sandra output etwas visuelles & vergleichbares basteln.
Hey, sag das nicht mir, sondern stell die Frage @ZeroStrat was er damals programmiert hat
Ich persönlich gebe abslout garnichts auf die Ergebnisse, ich benche Games (eben das, wofür der 78X3D gemacht wurde) und vergleiche dann die Ergebnisse mit und ohne RAM OC
Denke nicht dass AMD kein SiSoftware Sandra verwendet.
Jedoch sind leider Spiele kein Benchmark.
Das selbe Thema mit den synthetischen welche im genauen gegenteil kaum größer als 500-600mb sind.
Zuu optimiert, füllen kaum die BufferQueue.
Spiele hingegen sind nicht optimiert in den meisten fällen und in manchen wären die Datengrößen auf bestimmten Platformen optimiert.
Aka das selbe Ergebnis was wir letzten Post sehen. Instruction sets favoritisieren X Platform.
Für's hobby OCing womöglich gut genug.
Für neutrale Forschung mir leider zuu Fehlerhaft mit zu vielen Variablen.
RamOC & IPC tracking ist ein komplexes Thema. Um so mehr wenn es jeden Command korrigieren kann.
Beitrag automatisch zusammengeführt:
Haue ReBAR und HSA noch oben drauf welches Loadscheduling und Powergating betreiben
Oben drauf noch die Dynamik welche in den heutigen GPUs existiert. Ebenso dynamische hin und her Verteilung zwischen L$ & VRAM;
Alles vieel zu viele Variablen für mich.
Ich benchmarke somit nicht mit Spielen. Aus spaß womöglich, aber nicht um Daten zu sammeln.
Meine Art ist nicht besonders anders zu AMD's HQ. Wir? verwenden gerne mehrere analytische tools für analytische Arbeit.
Ob man dann versteht was man überhaupt testet, ist ein anderes Thema leider.
Man lernt nie aus
Große Skalierung in X Titeln
= sehr schlecht gecodetes Projekt oder Riesen groß.
L$ leakt zu mem und bevorzugt je nach SKU die MemLatenz anstelle die InterCCD Latenz.
Ein langes Thema.
Jedoch "keine skallierung" bedeutet fast nie "ein sinnloses Timing"
Jedes Timing welches niedriger gehe , bringt irgendwo bei irgend einem Szenario schon irgendwas
Ob es von Grundauf korrigiert wurde, merkst du allerdings nur wenn du positive Skallierung mit höheren Timings hast.
Nun ja, komplexes Thema ~ den kein Timing geht ebenso alleine.
Somit nütze ich Games nicht für analystische Zwecke.
Für Stabilitätszwecke, gerne ~ als Langzeit Projekt.
Einfach aufgrund der dynamischen last des Titels.
Um daten zu sammeln, wäre mir solch etwas deutlich zu inkonsistent.
Als nicht Dev, traue ich dem Tool nicht woraus/womit ich meine Daten dann sammeln sollte
Mir brauchst du das nicht zu erzählen, ich mache das seit zwanzig Jahren mit
Aber wenn wir ins Detail gehen wollen und jedes Quantum herausarbeiten wollen ist das hier eventuell das falsche Forum dafür.
Wie dem auch sei, für absolutes Optimum fehlt es den meisten an Verständnis, deswegen halte ich es bei Erklärungen so einfach wie möglich.
Keiner versteht das "Fach-Chinesisch" und oftmals verschlimmert es noch.
What ever, ich halte den persönlichen Workflow am besten (für den einzelnen User) deswegen gehe ich nicht zu sehr ins Detail.
Was AMD (und deren devs) dann sagen ist eh was anderes als das was wir als AMD Nutzer einstellen können.
Um auf den Grund zu kommen warum ich das sage, es wird viel versucht, oft scheitert es aber alleindaran was für Treiber man installiert, AMD ist genauso wie Intel nicht unfehlbar.
Deswegen gibt es uns Tweaker ja, ob das nun zum Erfolg führt oder nicht, ist mit unter auch Sillicon lottery.
Fixed critical thinking mistake - REFi.
Now flawless. WIP FGR for both platforms
Added Changelogs. ~ visible ?
Will be filled out for missing timestamps.
Consideration to publish it globally ? @RedF
Consideration to multi-make it for global DDR5 ? ** dann würde ich mir überlegen die Timings genauer zu kallulieren und Specifications einzufügen. // nCK + rounding calculations
Oft bekommen es Boardpartner ebenso falsch. Meistens absichtlich "da es ja läuft"
Sprich Intel und AMD.
Wenn es zu viel Arbeit für dich ist, lass mich bitte wissen.
Momentan etwas "faul", und ändere nur Kleinigkeiten welche mich stören.
Kaum Fokus auf dem Sheet. Wäre aber schade daraus nicht etwas großes zu machen.
Als sheet maker wirst du Wöchentlich Beschwerden und kommentar-emails bekommen. 🤭
Bzw erneuerte Edit-Anfragen durch random E-Mails.
Wenn es OK für dich ist, dann könnte man sich die Zeit nehmen und es "korrekter" hinbekommen.
Mir zwar alles als offline Helper-App deutlich lieber, aber so geht es auch~
Besonders da die meisten Calculator Projekte unseriös sind. Tauchen auf und werden vergessen 🤭🤭
Fixed critical thinking mistake - REFi.
Now flawless. WIP FGR for both platforms
Added Changelogs. ~ visible ?
Will be filled out for missing timestamps.
Consideration to publish it globally ? @RedF
Consideration to multi-make it for global DDR5 ? ** dann würde ich mir überlegen die Timings genauer zu kallulieren und Specifications einzufügen. // nCK + rounding calculations
Oft bekommen es Boardpartner ebenso falsch. Meistens absichtlich "da es ja läuft"
Sprich Intel und AMD.
Wenn es zu viel Arbeit für dich ist, lass mich bitte wissen.
Momentan etwas "faul", und ändere nur Kleinigkeiten welche mich stören.
Kaum Fokus auf dem Sheet. Wäre aber schade daraus nicht etwas großes zu machen.
Als sheet maker wirst du Wöchentlich Beschwerden und kommentar-emails bekommen. 🤭
Bzw erneuerte Edit-Anfragen durch random E-Mails.
Wenn es OK für dich ist, dann könnte man sich die Zeit nehmen und es "korrekter" hinbekommen.
Mir zwar alles als offline Helper-App deutlich lieber, aber so geht es auch~
Besonders da die meisten Calculator Projekte unseriös sind. Tauchen auf und werden vergessen 🤭🤭
Ob wir auf @Kelutrel warten müssen (@RedF magst du für mich auf OCN Taubenpost spielen ~ er sollte mit dem MemTest bzw Interthread code schon lange fertig sein)
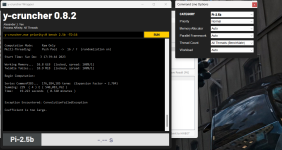
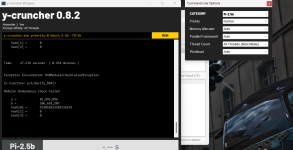
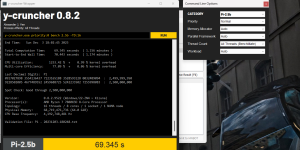
Ohne andere Timings nochmal anzupassen bin ich wieder auf tCL = 28, allerdings bin ich mit den Resultaten mehr als unzufrieden.
Hier zum Vergleich tCL = 30
Seit der Umstellung auf CL28 hat Zen Probleme meine Spannungen auszulesen.
Könnte es daher ein Spannungsproblem sein, welches auch greift, wenn ich tRFC auf 130 ns reduzieren will?
Hübsch
Denkst du du kannst die range für die 31er ins rötliche erhöhen ?
Minimal blutorange.
Damit der Unterschied zwischen 26 & 21 größer wird
Wobei 20ns recht gut sind für die CPU.
Auf Intel wären wir nahe 30ns.
Minimal anders, Ryzen wäre auf einem MultiRing design.
Intel auf einem simpleren.
Sobald du fertig bist, kann man es im Intel Thread mit den E-cores gegentesten.

")





")
