Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
-
Hardwareluxx führt derzeit die Hardware-Umfrage 2025 (mit Gewinnspiel) durch und bittet um eure Stimme.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
[Sammelthread] Ryzen DDR5 RAM OC Thread
- Ersteller Reous
- Erstellt am
RedF
Enthusiast
- Mitglied seit
- 07.03.2020
- Beiträge
- 3.132
- Ort
- am Main
- Desktop System
- Rechner
- Laptop
- Laptop
- Details zu meinem Desktop
- Prozessor
- Ryzen 7800X3D
- Mainboard
- ASrock X670E Taichi
- Kühler
- Core 1 360+1080 Radiator
- Speicher
- 32GB 6200MHz
- Grafikprozessor
- 7900XTX
- Display
- Samsung C32HG70
- SSD
- 2x960GB Corsair MP510 1x512GB Samsung PM961 1x2TB FireCuda
- HDD
- Seagate 4TB
- Opt. Laufwerk
- -
- Soundkarte
- GC7
- Gehäuse
- be quiet! 601 Silentbase / aufgesägt
- Netzteil
- Seasonic Prime 1000
- Keyboard
- logitech G815
- Mouse
- Xtrfy MZ1
- Betriebssystem
- W11
- Webbrowser
- Firefox
- Sonstiges
- 3D-Drucker: Qidi Plus 4, Ender 3V2 (war er mal)
Ja, die S war eigentlich nur ein Funktionstest. Sollten sie zur eigentlichen machen.@RedF und Veii ich habe die Änderungen über die zuletz freigegebene Excel von RedF vorgenommen. Im Changelog habe ich meine Änderungen entsprechend hinterlegt.
War das so falsch? Sorry wenn es jetzt durch mich zu einem Durcheinander kam. Welche Datei ist denn die richtige bzw. welcher Link
Beitrag automatisch zusammengeführt:
CLDO VDDP 1,0V tPHYRDL 35/37 . CLDO VDDP 1,143V tPHYRDL 35/35
Jetzt habe ich eine Stellschraube : ).
Kann jetzt endlich XX-36-36-36 versuchen, hab damit nie die tPHYRDL gleich bekommen.
Zuletzt bearbeitet:
LuxSkywalker
Urgestein
- Mitglied seit
- 11.09.2014
- Beiträge
- 980
- Ort
- Bielefeld
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7900X / SP113 / PBO CO max ausgelotet / SMT disabled
- Mainboard
- Asus ROG Strix X670E-F + TR AM5 Secure Frame Black / BIOS 1602 / all Voltages max UV
- Kühler
- Noctua NH-D15 + NM-AMB12 (-7 mm offset) chromax.black / Kryonaut Extreme
- Speicher
- G.Skill Ripjaws S5 32GB/DDR5-6800 A-Die @ 6000CL28-36-36-48-84+Subs opt. @1.355V --> AIDA 54.x ns
- Grafikprozessor
- Palit nVidia RTX 4070Ti Super GamingPro OC
- Display
- AOC AG273QS3R4 @ 144Hz, iiyama ProLite XB2483HSU @ 60Hz (hochkant, logging OpenHAB)
- SSD
- NVMe: 3x WD SN850x 1TB / 2TB / 4TB & 1x WD SN770 2TB
- HDD
- SSD: Samsung 850 Pro 512GB, 850 Evo 1TB
- Opt. Laufwerk
- LG CH10LS28, LG GGC-H20L
- Soundkarte
- Nubert 2x nuPro A-200 Aktivboxen, Wandhalter WH-N1
- Gehäuse
- Corsair Carbide Series 300R / Noiseblocker NB-eLoop Fan Black Edition 2x B12-PS & 2x B14-PS
- Netzteil
- Seasonic Prime TX-650 650W ATX 2.4 + SS-2X8P-12VHPWR-600
- Keyboard
- Cherry MX 3000 USB
- Mouse
- Logitech G502 Hero
- Betriebssystem
- Windows 10 Pro 22H2
- Webbrowser
- LibreWolf
- Sonstiges
- Kein Bling Bling im PC ^^
- Internet
- ▼100 MBit ▲30 MBit
RedF
Enthusiast
- Mitglied seit
- 07.03.2020
- Beiträge
- 3.132
- Ort
- am Main
- Desktop System
- Rechner
- Laptop
- Laptop
- Details zu meinem Desktop
- Prozessor
- Ryzen 7800X3D
- Mainboard
- ASrock X670E Taichi
- Kühler
- Core 1 360+1080 Radiator
- Speicher
- 32GB 6200MHz
- Grafikprozessor
- 7900XTX
- Display
- Samsung C32HG70
- SSD
- 2x960GB Corsair MP510 1x512GB Samsung PM961 1x2TB FireCuda
- HDD
- Seagate 4TB
- Opt. Laufwerk
- -
- Soundkarte
- GC7
- Gehäuse
- be quiet! 601 Silentbase / aufgesägt
- Netzteil
- Seasonic Prime 1000
- Keyboard
- logitech G815
- Mouse
- Xtrfy MZ1
- Betriebssystem
- W11
- Webbrowser
- Firefox
- Sonstiges
- 3D-Drucker: Qidi Plus 4, Ender 3V2 (war er mal)
Cool, danke für die Bestätigung : )@RedF
Danke!! - mit CLDO_VDDP 1.090V konnte ich endlich meinen tPHYRDL mismatch beheben
mir war vorher nicht bewusst wie ich das in den Griff kriege
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.432
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
VPP_MEM unter 1.8v solange es kein auslese Fehler ist, wäre problematisch.
Das selbe mit tRP unter tRCD.
Das selbe mit tRP unter tRCD.
LuxSkywalker
Urgestein
- Mitglied seit
- 11.09.2014
- Beiträge
- 980
- Ort
- Bielefeld
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7900X / SP113 / PBO CO max ausgelotet / SMT disabled
- Mainboard
- Asus ROG Strix X670E-F + TR AM5 Secure Frame Black / BIOS 1602 / all Voltages max UV
- Kühler
- Noctua NH-D15 + NM-AMB12 (-7 mm offset) chromax.black / Kryonaut Extreme
- Speicher
- G.Skill Ripjaws S5 32GB/DDR5-6800 A-Die @ 6000CL28-36-36-48-84+Subs opt. @1.355V --> AIDA 54.x ns
- Grafikprozessor
- Palit nVidia RTX 4070Ti Super GamingPro OC
- Display
- AOC AG273QS3R4 @ 144Hz, iiyama ProLite XB2483HSU @ 60Hz (hochkant, logging OpenHAB)
- SSD
- NVMe: 3x WD SN850x 1TB / 2TB / 4TB & 1x WD SN770 2TB
- HDD
- SSD: Samsung 850 Pro 512GB, 850 Evo 1TB
- Opt. Laufwerk
- LG CH10LS28, LG GGC-H20L
- Soundkarte
- Nubert 2x nuPro A-200 Aktivboxen, Wandhalter WH-N1
- Gehäuse
- Corsair Carbide Series 300R / Noiseblocker NB-eLoop Fan Black Edition 2x B12-PS & 2x B14-PS
- Netzteil
- Seasonic Prime TX-650 650W ATX 2.4 + SS-2X8P-12VHPWR-600
- Keyboard
- Cherry MX 3000 USB
- Mouse
- Logitech G502 Hero
- Betriebssystem
- Windows 10 Pro 22H2
- Webbrowser
- LibreWolf
- Sonstiges
- Kein Bling Bling im PC ^^
- Internet
- ▼100 MBit ▲30 MBit
@RedF
ich habe zu danken
wäre ich im Leben nicht drauf gekommen 👍
@Veii
MEM VPP ob 1.8V oder jetzt runter auf 1.72V kann ich keinerlei Unterschiede feststellen - bin aber insgesamt ein Freund von möglichst niedrigen Spannungen
aktuell wird CLDO_VDDP im BIOS schon "gelb" angezeigt (alles über 1.100V purple) - so richtig gefällt mir das nicht, aber anders bekomme ich den tPHYRDL Mismatch nicht behoben ^^
/edit
CLDO_VDDP Farben vertauscht ^^
ich habe zu danken
wäre ich im Leben nicht drauf gekommen 👍
@Veii
MEM VPP ob 1.8V oder jetzt runter auf 1.72V kann ich keinerlei Unterschiede feststellen - bin aber insgesamt ein Freund von möglichst niedrigen Spannungen
aktuell wird CLDO_VDDP im BIOS schon "gelb" angezeigt (alles über 1.100V purple) - so richtig gefällt mir das nicht, aber anders bekomme ich den tPHYRDL Mismatch nicht behoben ^^
/edit
CLDO_VDDP Farben vertauscht ^^
Zuletzt bearbeitet:
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.432
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
1.1v VDD_MEM, 1.1v VDDQ_MEMMEM VPP ob 1.8V oder jetzt runter auf 1.72V kann ich keinerlei Unterschiede feststellen
1.8v VPP_MEM
sind die Specifications für DDR5.
LuxSkywalker
Urgestein
- Mitglied seit
- 11.09.2014
- Beiträge
- 980
- Ort
- Bielefeld
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7900X / SP113 / PBO CO max ausgelotet / SMT disabled
- Mainboard
- Asus ROG Strix X670E-F + TR AM5 Secure Frame Black / BIOS 1602 / all Voltages max UV
- Kühler
- Noctua NH-D15 + NM-AMB12 (-7 mm offset) chromax.black / Kryonaut Extreme
- Speicher
- G.Skill Ripjaws S5 32GB/DDR5-6800 A-Die @ 6000CL28-36-36-48-84+Subs opt. @1.355V --> AIDA 54.x ns
- Grafikprozessor
- Palit nVidia RTX 4070Ti Super GamingPro OC
- Display
- AOC AG273QS3R4 @ 144Hz, iiyama ProLite XB2483HSU @ 60Hz (hochkant, logging OpenHAB)
- SSD
- NVMe: 3x WD SN850x 1TB / 2TB / 4TB & 1x WD SN770 2TB
- HDD
- SSD: Samsung 850 Pro 512GB, 850 Evo 1TB
- Opt. Laufwerk
- LG CH10LS28, LG GGC-H20L
- Soundkarte
- Nubert 2x nuPro A-200 Aktivboxen, Wandhalter WH-N1
- Gehäuse
- Corsair Carbide Series 300R / Noiseblocker NB-eLoop Fan Black Edition 2x B12-PS & 2x B14-PS
- Netzteil
- Seasonic Prime TX-650 650W ATX 2.4 + SS-2X8P-12VHPWR-600
- Keyboard
- Cherry MX 3000 USB
- Mouse
- Logitech G502 Hero
- Betriebssystem
- Windows 10 Pro 22H2
- Webbrowser
- LibreWolf
- Sonstiges
- Kein Bling Bling im PC ^^
- Internet
- ▼100 MBit ▲30 MBit
RedF
Enthusiast
- Mitglied seit
- 07.03.2020
- Beiträge
- 3.132
- Ort
- am Main
- Desktop System
- Rechner
- Laptop
- Laptop
- Details zu meinem Desktop
- Prozessor
- Ryzen 7800X3D
- Mainboard
- ASrock X670E Taichi
- Kühler
- Core 1 360+1080 Radiator
- Speicher
- 32GB 6200MHz
- Grafikprozessor
- 7900XTX
- Display
- Samsung C32HG70
- SSD
- 2x960GB Corsair MP510 1x512GB Samsung PM961 1x2TB FireCuda
- HDD
- Seagate 4TB
- Opt. Laufwerk
- -
- Soundkarte
- GC7
- Gehäuse
- be quiet! 601 Silentbase / aufgesägt
- Netzteil
- Seasonic Prime 1000
- Keyboard
- logitech G815
- Mouse
- Xtrfy MZ1
- Betriebssystem
- W11
- Webbrowser
- Firefox
- Sonstiges
- 3D-Drucker: Qidi Plus 4, Ender 3V2 (war er mal)
1,8V VPP ist sozusagen ein Hauptversorgungsstrang, gut funktioniert bestimmt auch mit weniger.
Aber wenn was instabil wird, würde ich das wieder hochsetzten.
Aber wenn was instabil wird, würde ich das wieder hochsetzten.


- Mitglied seit
- 09.01.2004
- Beiträge
- 4.844
- Desktop System
- Schrankrechner
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 9800X3D
- Mainboard
- ASUS Crosshair X670E Gene
- Kühler
- TechN AM4 / Watercool HK5 / 2x560 AC XT45 / 2x D5N + AC Nickel Dualtop / Ultitube
- Speicher
- 2x16GB A-Die
- Grafikprozessor
- RTX 4090 Founders Edition
- Display
- LG 27GN950 + LG 27UL850
- SSD
- 4TB WD SN850X
- Gehäuse
- Thermaltake P3 Red im Schrank
- Netzteil
- Corsair AX1600i
- Betriebssystem
- Windows 10 22H2
- Sonstiges
- Sonos Beam + 2x Sonos Era100
- Internet
- ▼200 Mbit
Erste Versuche mit den 8000 48er Kit sind eher durchwachsen, bekomme es nicht so richtig stabil. 25x TM5 laufen durch, Karhu dann bei 8K Fehler. Klingt weniger nach dem Kit als nach der CPU.
CPU ist stock alles. RAM wird max 55°C warm.
![2023-12-10 17_59_22-HWiNFO64 v7.66-5271 Sensor Status [1 value hidden].png](https://www.hardwareluxx.de/community/data/attachments/811/811464-2ca9cc7fdaa60fca7fcceea3c963cfb6.jpg "2023-12-10 17_59_22-HWiNFO64 v7.66-5271 Sensor Status [1 value hidden].png")
CPU ist stock alles. RAM wird max 55°C warm.
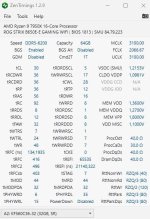
- VSOC: 1,3V
- VDD + Q: 1,55V (Wahrscheinlich zu hoch, aber erstmal das Kit mit ausschließen)
- VDDIO: Auto ~ 1,43V
- CLDO VPP 1,05V
Wolf87
Experte
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.432
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
CPU 1P8v SpannungsversorgungGibts noch etwas was den missmatch beeinflusst.
Alle proc ~ ODT's
Alle RTTs
tRDWR
tWRRD
Alle SD's & DD's
EDIT: eventuell auch VDDIO (womöglich eher, anstelle VDDP)
Setze mal beide WRWR_SD/DD's auf 8 ?
Und procODT ein tick tiefer
Könnte MCR aus + Fastboot aus brauchen.
Den Timingsänderungen erzwingen keinen Coldboot.
Zuletzt bearbeitet:
LuxSkywalker
Urgestein
- Mitglied seit
- 11.09.2014
- Beiträge
- 980
- Ort
- Bielefeld
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7900X / SP113 / PBO CO max ausgelotet / SMT disabled
- Mainboard
- Asus ROG Strix X670E-F + TR AM5 Secure Frame Black / BIOS 1602 / all Voltages max UV
- Kühler
- Noctua NH-D15 + NM-AMB12 (-7 mm offset) chromax.black / Kryonaut Extreme
- Speicher
- G.Skill Ripjaws S5 32GB/DDR5-6800 A-Die @ 6000CL28-36-36-48-84+Subs opt. @1.355V --> AIDA 54.x ns
- Grafikprozessor
- Palit nVidia RTX 4070Ti Super GamingPro OC
- Display
- AOC AG273QS3R4 @ 144Hz, iiyama ProLite XB2483HSU @ 60Hz (hochkant, logging OpenHAB)
- SSD
- NVMe: 3x WD SN850x 1TB / 2TB / 4TB & 1x WD SN770 2TB
- HDD
- SSD: Samsung 850 Pro 512GB, 850 Evo 1TB
- Opt. Laufwerk
- LG CH10LS28, LG GGC-H20L
- Soundkarte
- Nubert 2x nuPro A-200 Aktivboxen, Wandhalter WH-N1
- Gehäuse
- Corsair Carbide Series 300R / Noiseblocker NB-eLoop Fan Black Edition 2x B12-PS & 2x B14-PS
- Netzteil
- Seasonic Prime TX-650 650W ATX 2.4 + SS-2X8P-12VHPWR-600
- Keyboard
- Cherry MX 3000 USB
- Mouse
- Logitech G502 Hero
- Betriebssystem
- Windows 10 Pro 22H2
- Webbrowser
- LibreWolf
- Sonstiges
- Kein Bling Bling im PC ^^
- Internet
- ▼100 MBit ▲30 MBit

Wolf87
Experte
Bei mir hat es leider nicht zum Erfolg geführt danke trotzdem. Dann muss ich einfach die Werte durchprobieren
RedF
Enthusiast
- Mitglied seit
- 07.03.2020
- Beiträge
- 3.132
- Ort
- am Main
- Desktop System
- Rechner
- Laptop
- Laptop
- Details zu meinem Desktop
- Prozessor
- Ryzen 7800X3D
- Mainboard
- ASrock X670E Taichi
- Kühler
- Core 1 360+1080 Radiator
- Speicher
- 32GB 6200MHz
- Grafikprozessor
- 7900XTX
- Display
- Samsung C32HG70
- SSD
- 2x960GB Corsair MP510 1x512GB Samsung PM961 1x2TB FireCuda
- HDD
- Seagate 4TB
- Opt. Laufwerk
- -
- Soundkarte
- GC7
- Gehäuse
- be quiet! 601 Silentbase / aufgesägt
- Netzteil
- Seasonic Prime 1000
- Keyboard
- logitech G815
- Mouse
- Xtrfy MZ1
- Betriebssystem
- W11
- Webbrowser
- Firefox
- Sonstiges
- 3D-Drucker: Qidi Plus 4, Ender 3V2 (war er mal)
Ich musste bei 6200 auf XX-37-37-37 und die gleich zu bekommen.
Wolf87
Experte
Danke hat auch nichts bebracht
LuxSkywalker
Urgestein
- Mitglied seit
- 11.09.2014
- Beiträge
- 980
- Ort
- Bielefeld
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7900X / SP113 / PBO CO max ausgelotet / SMT disabled
- Mainboard
- Asus ROG Strix X670E-F + TR AM5 Secure Frame Black / BIOS 1602 / all Voltages max UV
- Kühler
- Noctua NH-D15 + NM-AMB12 (-7 mm offset) chromax.black / Kryonaut Extreme
- Speicher
- G.Skill Ripjaws S5 32GB/DDR5-6800 A-Die @ 6000CL28-36-36-48-84+Subs opt. @1.355V --> AIDA 54.x ns
- Grafikprozessor
- Palit nVidia RTX 4070Ti Super GamingPro OC
- Display
- AOC AG273QS3R4 @ 144Hz, iiyama ProLite XB2483HSU @ 60Hz (hochkant, logging OpenHAB)
- SSD
- NVMe: 3x WD SN850x 1TB / 2TB / 4TB & 1x WD SN770 2TB
- HDD
- SSD: Samsung 850 Pro 512GB, 850 Evo 1TB
- Opt. Laufwerk
- LG CH10LS28, LG GGC-H20L
- Soundkarte
- Nubert 2x nuPro A-200 Aktivboxen, Wandhalter WH-N1
- Gehäuse
- Corsair Carbide Series 300R / Noiseblocker NB-eLoop Fan Black Edition 2x B12-PS & 2x B14-PS
- Netzteil
- Seasonic Prime TX-650 650W ATX 2.4 + SS-2X8P-12VHPWR-600
- Keyboard
- Cherry MX 3000 USB
- Mouse
- Logitech G502 Hero
- Betriebssystem
- Windows 10 Pro 22H2
- Webbrowser
- LibreWolf
- Sonstiges
- Kein Bling Bling im PC ^^
- Internet
- ▼100 MBit ▲30 MBit
das ist ja mal total Strange - kannst du mal bitte einen ZT Screenshot mit deinen aktuellen Timings posten @Wolf87
hab übersehen das du schon zuvor einen Screenshot gepostet hast ^^
@RedF
ich musste CLDO_VDDP nochmals um 2mV anheben auf nun 1.097V um den Mismatch auch bei Kaltstart zuverlässig zu beheben
hab übersehen das du schon zuvor einen Screenshot gepostet hast ^^
@RedF
ich musste CLDO_VDDP nochmals um 2mV anheben auf nun 1.097V um den Mismatch auch bei Kaltstart zuverlässig zu beheben
Zuletzt bearbeitet:
Wolf87
Experte
RedF
Enthusiast
- Mitglied seit
- 07.03.2020
- Beiträge
- 3.132
- Ort
- am Main
- Desktop System
- Rechner
- Laptop
- Laptop
- Details zu meinem Desktop
- Prozessor
- Ryzen 7800X3D
- Mainboard
- ASrock X670E Taichi
- Kühler
- Core 1 360+1080 Radiator
- Speicher
- 32GB 6200MHz
- Grafikprozessor
- 7900XTX
- Display
- Samsung C32HG70
- SSD
- 2x960GB Corsair MP510 1x512GB Samsung PM961 1x2TB FireCuda
- HDD
- Seagate 4TB
- Opt. Laufwerk
- -
- Soundkarte
- GC7
- Gehäuse
- be quiet! 601 Silentbase / aufgesägt
- Netzteil
- Seasonic Prime 1000
- Keyboard
- logitech G815
- Mouse
- Xtrfy MZ1
- Betriebssystem
- W11
- Webbrowser
- Firefox
- Sonstiges
- 3D-Drucker: Qidi Plus 4, Ender 3V2 (war er mal)
Kannst damit jetzt sehr stabil die Latenz messen. Warum das mit jedem Kern einzeln geht, ist mir aber nicht klar.
Er will über die Feiertage die Core2Core Latenz Messung mit einbauen.
Er will über die Feiertage die Core2Core Latenz Messung mit einbauen.
Hat schon jemand 8000er Ram mit dem 7800x3d getestet? Mich würd interessieren wie der Speicher in CS2, Valorant und COD performt.
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Youtube Videos ab jetzt direkt anzeigen
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Youtube Videos ab jetzt direkt anzeigen
G
Gelöschtes Mitglied 189335
Guest
Nachricht gelöscht
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.432
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
Ein weiterer Nutzer/Reviewseite welche Memory timings nicht skallieren können~

Wenn man schon sich die mühe macht ein Video zu schneiden
So sollte man wenigstens auch versuchen die Timings gleichzustellen.
Ebenso muss man gegentesten ob FCLK nicht schon beginnt zu trotteln wenn man aus heiterem Himmel 150mV wegschneidet.

Abseits autocorrection , könnte es sogar gleich enden. Den einerseits sind Spiele keine Benchmarks und andererseits füllen sie kaum Ram bzw nicht jeder Test füllt den X3D Cache.
Aber hier testet man Äpfel vs Kirschen.
Birnen wären es , wenn man wenigstens PostPackageRepair bei Mem nicht erzwingen würde mit den "zuu niedrigen" 2ndaries bei 7800.
Äpfel vs Äpfel wäre es dann wenn man die Spannungen gleich lässt, und das 6400er Preset hochskaliert.
Oder beide auf 2100 FCLK rennt mit niedrigen Spannungen (da ansonsten Gear 2 womöglich nicht stabil sein wird)
Hier hat man 3+ Variablen und ich selber könnte nichtmal herausfinden was man überhaupt vergleicht
~ Skalliert der Titel mit MCLK
~ Skalliert der Titel mit niedriger Zugriffszeit
~ Kümmert es die CPU wie hoch UCLK rennt.
Ich weiß es nicht. Was testet man ?
Allerdings haben solche Ergebnisse zuu viele Variablen und man sollte es besser nochmal versuchen.
Valo, nur wenn es mehr als 4 Kerne ladet
CS , eigentlich das selbe.
Apex womöglich das selbe. Recht unoptimiert und eine Große map + kann 24 threads belasten. Sollte rüberleaken
Alles nur wenn die Kerne auch den Max boost halten und der Nutzer nicht dank zuu niedrigem CO throttled.
Dann , könnte man eventuell im Cache limiter landen und erst dann ! , spielt es eine Rolle wie schlecht Optimiert bzw wie Groß der Titel ist den man rennt.
Nach all diesen Variablen
Sollte man 7600MT/s auf 4 dimm-slot Boards einfacher hinbekommen, bzw 7800 auf 2 Dimm-Slot Boards
Als das 6200/6400 Gegenstück. Bei niedrigerer Spannung.
Was 2100 FCLK dann benötigt ist eine weitere Variable
Aber für X3D CPUs ist die Interne Bandwidth nahe zu 500GB/s.
Es ist genug. FCLK ist halb/unwichtig.
Da spielen zwischen 80GB/s mem und 100GB/s mem kaum eine Rolle.
CoreClock aka Cache-Clock spielt eine wichtige Rolle ~ und dann je nach Titel ob Cache rüberleakt (aka zuu voll) oder der Titel ein IndieSpiel ist bzw keinerlei kerne auslastet.
Keine Kernlast = genug cache = mem unwichtig.
Soweit sehe ich keinen Reviewer/Public Media - auch nicht die Mainstream internationalen ~ welche es per SKU korrekt testen.
Damit inkludiere ich 25+ Reviewer und Tester - including Overclocker.
Es ist traurig. Man missversteht was man eigentlich testet.
EDIT:
Von dem kleinen Teil an Overclocker welche es versuchen zu testen kommt dann
"X skalliert nicht, Y ist zuu schwer zu rennen ~ brauchst du nicht. Not worth it"
Leider denke ich dass auch das eine fehlerhafte Zeichnung der Realität ist
Es muss nicht skalieren damit es in der Realität schneller sein kann/bzw schon ist.
Wenn MCLK immer skalieren würde wie bei Zen1/2, dann deutet das auf ein Architektur Problem.
Ja, X3D Leakt noch Cache (leider). Ich habe es selber getestet. Aber es ist soo selten und nur bei sehr unoptimierten Titeln. Bei voller Auslastung !
// NonX3D 1CCD umso mehr ~ aber die haben eher FCLK probleme.
Das macht Gear2 weiterhin nicht irrelevant oder "schlechter". Nur dass es aufgrund vielen anderen vorherigen! Variablen, Memory als solches selten beginnt eine Rolle zu Spielen.
// UCLK ist intern. MemoryClock ist extern , weit weg von der CPU.
Dennoch ist es einfacher 1850-1950MHz Gear 2 zu rennen, anstelle 3200-3300MHz Gear 1 🤭
Wie immer, das ist nur meine Sichtweise und Beobachtung. Man muss nicht unbedingt die selbe hegen~~
Wenn man schon sich die mühe macht ein Video zu schneiden
So sollte man wenigstens auch versuchen die Timings gleichzustellen.
Ebenso muss man gegentesten ob FCLK nicht schon beginnt zu trotteln wenn man aus heiterem Himmel 150mV wegschneidet.
Beitrag automatisch zusammengeführt:
Abseits autocorrection , könnte es sogar gleich enden. Den einerseits sind Spiele keine Benchmarks und andererseits füllen sie kaum Ram bzw nicht jeder Test füllt den X3D Cache.
Aber hier testet man Äpfel vs Kirschen.
Birnen wären es , wenn man wenigstens PostPackageRepair bei Mem nicht erzwingen würde mit den "zuu niedrigen" 2ndaries bei 7800.
Äpfel vs Äpfel wäre es dann wenn man die Spannungen gleich lässt, und das 6400er Preset hochskaliert.
Oder beide auf 2100 FCLK rennt mit niedrigen Spannungen (da ansonsten Gear 2 womöglich nicht stabil sein wird)
Hier hat man 3+ Variablen und ich selber könnte nichtmal herausfinden was man überhaupt vergleicht
~ Skalliert der Titel mit MCLK
~ Skalliert der Titel mit niedriger Zugriffszeit
~ Kümmert es die CPU wie hoch UCLK rennt.
Ich weiß es nicht. Was testet man ?
Allerdings haben solche Ergebnisse zuu viele Variablen und man sollte es besser nochmal versuchen.
Beitrag automatisch zusammengeführt:
COD als sehr unoptimierter Titel könnte sogar skallierenMich würd interessieren wie der Speicher in CS2, Valorant und COD performt.
Valo, nur wenn es mehr als 4 Kerne ladet
CS , eigentlich das selbe.
Apex womöglich das selbe. Recht unoptimiert und eine Große map + kann 24 threads belasten. Sollte rüberleaken
Alles nur wenn die Kerne auch den Max boost halten und der Nutzer nicht dank zuu niedrigem CO throttled.
Dann , könnte man eventuell im Cache limiter landen und erst dann ! , spielt es eine Rolle wie schlecht Optimiert bzw wie Groß der Titel ist den man rennt.
Nach all diesen Variablen
Sollte man 7600MT/s auf 4 dimm-slot Boards einfacher hinbekommen, bzw 7800 auf 2 Dimm-Slot Boards
Als das 6200/6400 Gegenstück. Bei niedrigerer Spannung.
Was 2100 FCLK dann benötigt ist eine weitere Variable
Aber für X3D CPUs ist die Interne Bandwidth nahe zu 500GB/s.
Es ist genug. FCLK ist halb/unwichtig.
Da spielen zwischen 80GB/s mem und 100GB/s mem kaum eine Rolle.
CoreClock aka Cache-Clock spielt eine wichtige Rolle ~ und dann je nach Titel ob Cache rüberleakt (aka zuu voll) oder der Titel ein IndieSpiel ist bzw keinerlei kerne auslastet.
Keine Kernlast = genug cache = mem unwichtig.
Soweit sehe ich keinen Reviewer/Public Media - auch nicht die Mainstream internationalen ~ welche es per SKU korrekt testen.
Damit inkludiere ich 25+ Reviewer und Tester - including Overclocker.
Es ist traurig. Man missversteht was man eigentlich testet.
EDIT:
Von dem kleinen Teil an Overclocker welche es versuchen zu testen kommt dann
"X skalliert nicht, Y ist zuu schwer zu rennen ~ brauchst du nicht. Not worth it"
Leider denke ich dass auch das eine fehlerhafte Zeichnung der Realität ist
Es muss nicht skalieren damit es in der Realität schneller sein kann/bzw schon ist.
Wenn MCLK immer skalieren würde wie bei Zen1/2, dann deutet das auf ein Architektur Problem.
Ja, X3D Leakt noch Cache (leider). Ich habe es selber getestet. Aber es ist soo selten und nur bei sehr unoptimierten Titeln. Bei voller Auslastung !
// NonX3D 1CCD umso mehr ~ aber die haben eher FCLK probleme.
Das macht Gear2 weiterhin nicht irrelevant oder "schlechter". Nur dass es aufgrund vielen anderen vorherigen! Variablen, Memory als solches selten beginnt eine Rolle zu Spielen.
// UCLK ist intern. MemoryClock ist extern , weit weg von der CPU.
Dennoch ist es einfacher 1850-1950MHz Gear 2 zu rennen, anstelle 3200-3300MHz Gear 1 🤭
Wie immer, das ist nur meine Sichtweise und Beobachtung. Man muss nicht unbedingt die selbe hegen~~
Zuletzt bearbeitet:
Bullseye13
Enthusiast
- Mitglied seit
- 05.05.2015
- Beiträge
- 3.991
- Ort
- Steiamoak
- Desktop System
- AM5 2023 build
- Details zu meinem Desktop
- Prozessor
- AMD R9 7950X @ TechN AM4
- Mainboard
- ASUS TUF Gaming X670E-Plus
- Kühler
- Wasserkühlung: Intern: 1x420mm 1x 360mm| Extern: Mora3Pro 420
- Speicher
- 4x16GB Kingston FURY Beast RGB @ 6000 CL30
- Grafikprozessor
- ASUS TUF 7900XT
- Display
- Xiaomi Mi Curved 34" 144Hz - i <3 it
- SSD
- WD_Black SN850X 1TB & WD_Black SN770 2TB
- Soundkarte
- Onboard
- Gehäuse
- Lian Li Lancool III
- Netzteil
- NZXT C Series 2022 C1200 Gold ATX 3.0
- Keyboard
- Logitech G910 Orion Spectrum
- Mouse
- Logitech G502 SE Hero
- Betriebssystem
- Windows 11
- Webbrowser
- Google Chrome
- Sonstiges
- Aquacomputer Double Protect Ultra - Gelb
Hat noch wer Verbesserungsvorschläge?
Läuft jetzt ziemlich rund.

Läuft jetzt ziemlich rund.
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.432
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
SD auf 1 oder 0 (wenn 0 ≠ Auto)
WRWR gleich RDRD oder CCDLWR Math
SCLs sind mathematische Formeln. Keine fixierten Werte wie 4 oder 8.
Dual CCDs haben als Problem erst die Intercore latency.
Sprich ring ist langsam. Es braucht FCLK bevor memory beginnt eine Rolle zu Spielen.
Core/Cache Clock über 5.5GHz sind mehr als genug.
X3D hat dieses Problem nicht.
X3D performt nur schlecht dank der Nutzer. Auf stock allerdings passt es. Nur wenn man CO nicht hinbekommt und Autokorrektur sich erzwingt;
2100 FCLK passen gut.
Ansonnsten MCLK +1 step und 2033/2067 FCLK
Die synchronization ist wichtig.
Nicht jeder MCLK step passt gut mit jedem FCLK step.
Laufen wird es, aber eines wartet auf das andere.
EDIT:
Die Kommunikation dessen, kann man mit SiSoftware Sandra , Inter-Thread tests gegentesten
Bzw microbenchmarks.
Man sieht deutlich wie sich alle Cache zwischenschritte verhalten und ab wann/bzw ob überhaupt memory clock eine rolle spielt.
Ab wann FCLK syncron ist, usw~~
- Mitglied seit
- 09.01.2004
- Beiträge
- 4.844
- Desktop System
- Schrankrechner
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 9800X3D
- Mainboard
- ASUS Crosshair X670E Gene
- Kühler
- TechN AM4 / Watercool HK5 / 2x560 AC XT45 / 2x D5N + AC Nickel Dualtop / Ultitube
- Speicher
- 2x16GB A-Die
- Grafikprozessor
- RTX 4090 Founders Edition
- Display
- LG 27GN950 + LG 27UL850
- SSD
- 4TB WD SN850X
- Gehäuse
- Thermaltake P3 Red im Schrank
- Netzteil
- Corsair AX1600i
- Betriebssystem
- Windows 10 22H2
- Sonstiges
- Sonos Beam + 2x Sonos Era100
- Internet
- ▼200 Mbit
@Veii Wahrscheinlich tRFC zu niedrig? Nach Reous Liste sollten 24GB M-Dies aber auch bis ~160ns gehen oder? Irgendwie scheint da bei ~180ns bei mir Ende zu sein. TRAS ist auf Optimum. VDD/Q Spannung jetzt gerade mal 1,55, absichtlich etwas überhöht. Ich versuche noch einmal 186ns bei 1,5V über Nacht.
8000 hab bisher mit egal welchen Settings und Spannungen nicht ans laufen gebracht.
Werte großteils mit eurem Rechner eingestellt, danke dafür. Ein Verbesserungsvorschlag wäre noch eine weitere Tabelle, die die End-Werte so darstellt wie im Zentiming. Dann kann man schnell vergleichen, ob man falsch liegt/was vergessen hat")
8000 hab bisher mit egal welchen Settings und Spannungen nicht ans laufen gebracht.
Werte großteils mit eurem Rechner eingestellt, danke dafür. Ein Verbesserungsvorschlag wäre noch eine weitere Tabelle, die die End-Werte so darstellt wie im Zentiming. Dann kann man schnell vergleichen, ob man falsch liegt/was vergessen hat
Anhänge
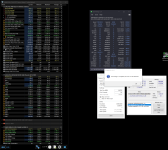
![2023-12-13 22_12_27-HWiNFO64 v7.66-5271 Sensor Status [1 value hidden].png](/community/data/attachments/812/812607-b3766c2d2f5875b7432dee0d8e572e0c.jpg)
Wolf87
Experte
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.432
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
Kannst du mir/uns garantieren dass das Hynix und keine Micron's sind ?@Veii Wahrscheinlich tRFC zu niedrig? Nach Reous Liste sollten 24GB M-Dies aber auch bis ~160ns gehen oder? Irgendwie scheint da bei ~180ns bei mir Ende zu sein.
Micron hat die JEDEC specs bis 8800MT/s ausgelegt.
^ 1.1v
Die letzten Corsairs unter 7200MT/s waren Micron's.
Microns sind nicht schlecht, bloß die ehmaligen 16gb dimms etwas immature.
Im Gesamtbild sind sie bis 8800MT/s worin Hynix nur bis 6400MT/s specs setzt.
@Veii woran erkennt man das im Inter Thread Test bzw in microbench fclk syncron läuft
AMD DDR5 OC And 24/7 Daily Memory Stability Thread
Klar und deutlich🤭
Natürlich muss man auch verstehen wann und wieso es skallieren würde, aber das wären nur Kleinigkeiten~
Moin
Beitrag automatisch zusammengeführt:
Ich warte weiterhin dass man mich ohne ECLK einholt ~ aber ja
Inter-core & thread "usable" Bandwidth ist eigentlich das wichtigste. Als Gesammtbild.
Welche Datengröße kann wie schnell angesprochen werden , mit welcher Bandbreite.
Ein Resultat aus CoreClk x Ring x SOCCLK x UCLK&MCLK.
Der Rest skaliert dann je nach Titel manchmal weniger, manchmal mehr.
Man sollte bei Last welche nicht mal 80% der CPU belasten - keinerlei Skallierung erwarten.
Den L$ ist mehr als schnell genug auf den X3D's um Intern Daten hin-und-her zu tauschen.
Die Latenz ebenso ~ 9ns to 20ns max. Wortwörtlich vorbildlich.
Die CPU würden die 52-55ns Memory überhaupt nicht kümmern. Dafür kann es 2x die Daten schneller im Cache verarbeiten welche ebenso über 150GB/s erreichen.
Anstelle auf 50ns Mem mit ~100GB/s zu warten.
Bei den non X3D's und besonders die Dual CCDs mit ~60-65ns Roundtrip latency , sieht das Thema schon ganz anders aus.
Da kann und sehr wahrscheinlich wird es ebenso (da L$ zu klein ist), eher zum DRAM springen.
Wenn Ring schnell genug ist, aber nun ja.
Es sind einiges an Variablen im CPU-Design, als dass/bevor man es zu MCLK schieben kann/muss.
Einiges muss schnell genug sein, bevor MCLK überhaupt ~global~ etwas bringen kann.
Skalieren tut's immer. Ob es allerdings dazu kommt aktiv benützt zu werden, ist eine andere Frage.
Jeder Clock auf Ryzen ist loadbalanced
Hoher FCLK zb bringt nicht immer was ~ wenn du eher Probleme im Core/Cache Clock hast.RDNA includiert;
TL;DRSkalieren tut's immer. Ob es allerdings dazu kommt aktiv benützt zu werden, ist eine andere Frage.
Es bringt immer was Gear2 zu rennen.
Es ist einfacher und es hängt von anderen Variablen (pro SKU unterschiedlich) ab, ob dein MCLK überhaupt ein Benefit liefert oder nicht.
"Verschwendet" wäre die Zeit nicht. Aktiv Geld dafür auszugeben muss man mit einer X3D CPU aber eher nicht. ~ An der haakt es an CoreClk zuerst.
7600 ist einfacher als 6400MT/s 🤭 Naja je nachdem.
Der Vergleichspunkt (ab welchem Clock es "Sinn" macht) skaliert je nach den vorherigen Variablen.
6200/7600 , 6400/7800-8000MT/s sind eher gleich auf.
6200MT/s sollten sehr viele CPUs können, 6400 aber eher die wenigen.
6600 womöglich nur 1-2%. 6400 womöglich nur 12-15%.
Kann skallieren.
Macht für manche Spaß
Man sollte keine Wunder erwarten.
Skalliert jederzeit oder skaliert später ~ SiSandra ist dein Freund. Hoffentlich auch bald RopBench.
Gibt keine Garantie dass es aktiv skaliert, da es 3 Variablen vor MCLK gibt welche ge'maxt werden müssen bevor es an MCLK haapert.
Das sollte als zufriedenstellende Antwort reichen~~
Einfach immer mit SiSandra gegentesten ob das Gesammtbild besser wird, wenn man selber keine Skalierung feststellen kann.
Zuletzt bearbeitet:
Bullseye13
Enthusiast
- Mitglied seit
- 05.05.2015
- Beiträge
- 3.991
- Ort
- Steiamoak
- Desktop System
- AM5 2023 build
- Details zu meinem Desktop
- Prozessor
- AMD R9 7950X @ TechN AM4
- Mainboard
- ASUS TUF Gaming X670E-Plus
- Kühler
- Wasserkühlung: Intern: 1x420mm 1x 360mm| Extern: Mora3Pro 420
- Speicher
- 4x16GB Kingston FURY Beast RGB @ 6000 CL30
- Grafikprozessor
- ASUS TUF 7900XT
- Display
- Xiaomi Mi Curved 34" 144Hz - i <3 it
- SSD
- WD_Black SN850X 1TB & WD_Black SN770 2TB
- Soundkarte
- Onboard
- Gehäuse
- Lian Li Lancool III
- Netzteil
- NZXT C Series 2022 C1200 Gold ATX 3.0
- Keyboard
- Logitech G910 Orion Spectrum
- Mouse
- Logitech G502 SE Hero
- Betriebssystem
- Windows 11
- Webbrowser
- Google Chrome
- Sonstiges
- Aquacomputer Double Protect Ultra - Gelb
Ich hab diesen Block eigentlich gemäß der Excel Tabelle eingestellt.SD auf 1 oder 0 (wenn 0 ≠ Auto)
WRWR gleich RDRD oder CCDLWR Math
SCLs sind mathematische Formeln. Keine fixierten Werte wie 4 oder 8.
Core/Cache Clock über 5.5GHz sind mehr als genug.
X3D hat dieses Problem nicht.
X3D performt nur schlecht dank der Nutzer. Auf stock allerdings passt es. Nur wenn man CO nicht hinbekommt und Autokorrektur sich erzwingt;
2100 FCLK passen gut.
Ansonnsten MCLK +1 step und 2033/2067 FCLK
Die synchronization ist wichtig.
Nicht jeder MCLK step passt gut mit jedem FCLK step.
Laufen wird es, aber eines wartet auf das andere.
Falls das nicht passt, hab ich die Tabelle wohl nicht verstanden.
Kannst mir eventuell zum Screenshot die Zahlen schreiben?
Ich bin mir nicht sicher ob ich deine Abkürzungen alle richtig verstehe.
FCLK 2100 werd ich dann als nächstes versuchen.
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.432
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
Müsstest zwischen 2033,2067,2100 gegentesten ab wann es sich am besten zu diesem MCLK verträgt. (sollte eine .5ns Reduktion bei der "random" Zugriffszeit" zu mem geben)FCLK 2100 werd ich dann als nächstes versuchen.
Einfach die SD's für Single Sided dimms wegKannst mir eventuell zum Screenshot die Zahlen schreiben?
Also so tief wie möglich rennen.
0 = Komplett Deaktiviert (nicht möglich auf AMD)
1 = Übersprungen, aber ODTEnableDly existiert.
2+ = Geladen und gegebenenfalls vom Controller korrigiert, fals zu niedrig.
Sie werden momentan als Puffer für 2ndaries benützt, aber du brauchst diesen nicht wirklich auf 16/24GB Single-sided DIMMs
Zb nur weil man Single Sided dimms rennt, heißt es nicht dass beide SD/DD/SC_Long nicht rennen~
Alles was du eingibst wird geladen. Manchmal durch SPD Hub logic übersprungen (wie zb das _L'ongs aktiv vermieden werden), aber alle Offset Timings werden aktiv draufgeladen.
Bloß hast du mit Single-Sided Dimms keinerlei Vorteil durch die _SD's. Mit den _DD's allerdings schon
Beitrag automatisch zusammengeführt:
Das selbe bei tWRRD.1 = Übersprungen, aber ODTEnableDly existiert.
2+ = Geladen und gegebenenfalls vom Controller korrigiert, fals zu niedrig.
Wird eigentlich auf Single-Sided DIMMs nicht benötigt.
Wert 1 = skip, instant
Wert 2+ = Geladen und potentiell korrigiert fals zu tief.
Kann man als Pause verwenden, muss man aber nicht.
Ich nehme es aus syncronizationsgründen zu anderen Timings bzw für PHYRDL und W/RPRE Delays.
Und weil der tWTRS Exploit auf 4 (half) nicht einfach zu rennen ist + jede Timing operation einen kleinen "breathing delay" irgendwo braucht * . Abseits dem Controller (PHY/ODT) delay.
Dafür ist RTP & WR eigentlich da, aber ich mag den Einfluss nicht welche diese Timings haben. WRRD und DD's sind gute Pufferzonen & Subchannels existieren. Somit passen sie gut~
* Einige persönliche Gründe.
Beitrag automatisch zusammengeführt:
@Gr3yh0und
Bitte zuerst mit TM5 dann wieder mit Karhu gegentesten
Mir gefallen von Grundauf nicht deine RTTs (unnötig stark)
Zwischen WRRD 3 und 6, bzw 4 - solltest du gegentesten können. Mit Benchmate, Pyprime 2B (5x öffnen, Realtime Priority & consistency zwischen den Run's testen ~ bzw hier screenshotten und hier hochladen)
Oder TM5 sollte dir (wegen den SCL's) schon vorher schreien 🤭
Du hast noch viel Spielraum mit FCLK ~ aber später dann.
Denke 8000MT/s bzw eigentlich sollte 8800MT/s dein Ziel werden.
Alles dazwischen ist broken.
Nachdem alle ODTs & RTTs passen~
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 76
- Aufrufe
- 9K
[Kaufberatung]
Ryzen 9000x3d - Vor dem Kauf technische Fragen bzgl. Ram
- Antworten
- 6
- Aufrufe
- 768
- Antworten
- 2
- Aufrufe
- 300
- Antworten
- 1
- Aufrufe
- 724
- Antworten
- 12
- Aufrufe
- 2K