Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden. Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
NOTICE: cpu1: started, but not running in the kernel yet
WARNING: cpu1: timed out
NOTICE: System detected 8 cpus, but only 7 cpu(s) were enabled during boot.
NOTICE: Use "boot-ncpus" parameter to enable more CPU(s). See eeprom(8).
Kommt aber nicht immer die Meldung.
Wenn Du diese Anzeige nicht sehen willst, registriere Dich und/oder logge Dich ein.
Ich würde mit eeprom die Boot Einstellungen nicht ohne große Not verändern.
Um herauszufinden ob das Problem nur beim Booten besteht oder auch danach
kann man sich im Fall der Fälle die CPU cores bei laufendem OS anzeigen lassen:
prtdiag | grep CPU
ps
Falls das Problem "früher" nicht auftrat, kann es auch mit den Anpassungen
aufgrund der aktuellen Sicherheits-Probleme mit Intel und AMD CPUs liegen,
die fortlaufend in Illumos eingepflegt werden.
Ich habe heute mal zum Testen neuer Hardware OmniOS r151048i installiert und dann als Eval napp-it 21.06 -> 23.06 -> 24.01.
Dabei ist mir aufgefallen, dass in der 24.01 der iozone Test nicht funktioniert. Ich habe mich dann auf die Suche gemacht um das Problem zu finden.
Im napp-it Verzeichnis "/var/weg-gui/data/tools/iozone" liegt das iozone File mit 0 Byte Länge. Die Rechte sind aber alle richtig gesetzt.
Zurück auf 23.06 war die Datei mit 255072 Byte vorhanden.
Schlussfolgerung da stimmt was bei der Installation nicht. Ich habe dann die 23.06 und die 24.01 heruntergeladen und das Archiv mal überprüft, dabei kam
Folgendes mit 7-Zip und RAR heraus:
! F:\napp-it-24.01.zip: Checksum error in web-gui\data_24.01\tools\iozone\iozone. The file is corrupt
! F:\napp-it-24.01.zip: Checksum error in web-gui\data_24.01\tools\omnios\fswatch\fswatchbinaries_1.17.1.tar.gz. The file is corrupt
! F:\napp-it-24.01.zip: The archive is corrupt
! F:\napp-it-23.06.zip: Checksum error in web-gui\data_23.06\tools\omnios\perl_5.22\CGI\Expect.pm. The file is corrupt
! F:\napp-it-23.06.zip: The archive is corrupt
Ein Auspackern unter Omnios mit unzip ergibt den selben Fehler File iozone = 0 Byte.
@gea
Es scheinen mindestens diese 2 Install-Zip defekt zu sein. Kannst du das verifizieren?
Vg
Beitrag automatisch zusammengeführt:
@ gea
die 24.dev ist auch betroffen...
mit RAR getestet:
! F:\napp-it-24.dev.zip: Checksum error in web-gui\data_24.dev\tools\iozone\iozone. The file is corrupt
! F:\napp-it-24.dev.zip: Checksum error in web-gui\data_24.dev\tools\omnios\fswatch\fswatchbinaries_1.17.1.tar.gz. The file is corrupt
! F:\napp-it-24.dev.zip: The archive is corrupt
Danke für die Info.
Ich habe die ZIP Archive getestet und neu hochgeladen.
Bei welcher Umkopieraktion die Dateien verfälscht wurden, kann ich jetzt nicht sagen.
ZFS meldet das ja sofort, das ZIP Archiv auf dem Webserver erst beim Auspacken,
nachdem ich nun mein Solaris endlich auf den Gigabyte Epyc Board installiert bekommen habe, gibt es nun die nächste Hürde bez. Import des bestehenden Pools.
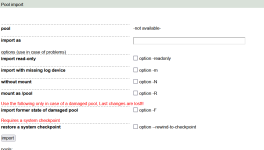
Der Pool wird mir nicht angezeigt unter nappit als Import bereit, dafür weiter unten folgende Info
warning: Pool hostid does not match physical hostid.
Konnte ich nicht, weil mir kein Pool zum Importieren angezeigt wurde. Hat genauso wie im Bild ausgeschaut, nur unten bei den exportet Pools war er aufgelistet. Hatte es auf blöd ohne versucht, weil ich mir gedacht hab, vlt macht er dann "import all available" aber nein, ging nicht.
Fiktives Szenario:
Power Loss beim Resilvering vom Z1.
Was passiert nach dem reboot? Gehts einfach weiter? Neustart vom Resilvering? Kanns sein, dass irgendwas ungünstigeres passiert?
Ist mir bloß eingefallen wegen dem USV-Gedanke...
...
Wenn ich aber die großen Daten kopiere, 50gb mit je ca. 6 gb/File, dann hab ich den Effekt, dass ich mit 280 mb/s schreibe und nur mit 80 mb/s lese. Ob das evtl. an der LZ4 Komprimierung liegt?
Also ich hab jetzt mit 4 statt 3 Platten ein neues Z1 gemacht, diesmal mit LZ4 wie default, jetzt läuft alles.
Obs echt ein defektes SATA Kabel war oder sowas? Die Backplane, die ich benutzt hab, ist nicht so 100% vertrauenswürdig, irgendwie, 2/5 Slots scheinen nicht zu gehen, wer weiss. Hab zwar keine Fehler bekommen, bestimmt aber auch nicht alle möglichen Tools zur Fehleranalyse (Smart etc.) ausgeschöpft, mangels eingeschränktem Wissen ...
Hmhmhm, wie isn das mit dem Metadata VDEV? Ist wohl besser das auf den Datendisks zu lassen, bezüglich Ausfallssicherheit und Wiederherstellbarkeit, oder?
Wie isn das mit den Metadaten, können die im RAM-Cache gehalten werden?
Ich hab hier nämlich einige Ordner, wo wirklich viel Dateien drin sind... ist nicht ideal aber ist halt so.
Special vdevs sind kein Cache sondern Speicherort für Metadaten oder kleine Dateien. Fällt dieses vdev aus ist der Pool futsch. Mindestanforderung ist daher ein 2way mirror, in kritischen Fällen ein 3way,
Metadaten landen immer im readcache. Special vdev beschleunigt neben dem Lesen aber auch das Schreiben.
Arc arbeitet mit einer read last/ read most optimierung.
Wenn der Arc groß genug ist, hat man gute Chancen dass Metadaten beim zweiten Zugriff im Cache sind. Hat man ein L2Arc so hat man zudem einen persistenten Lesecache (vergisst nichts beim Reboot)
Special vdev brauchen den wiederholten Zugriff nicht da die Metadaten direkt auf schnellem Storage liegen.
Nein, der L2Arc wird selber als zusätzlicher Cache benutzt. Sollte ja bis zu 10x so groß wie der Arc sein aber halt nicht so schnell. Auch verbraucht der L2Arc etwas RAM zum Verwalten.
Ist halt die Frage, ob das sinnvoll wäre.
Werden die Metadaten da dann auch rein gelegt?
Mein Ziel isses, dass die Ordnerstruktur und deren Inhalt möglichst schnell angezeigt werden, gar nicht so das schnelle Lesen der Files selbst. Damit man einfach schnell navigieren kann.
Die Metadaten werden beim Lesen als Kopie in den Cache gelegt. Schneller wirds also erst beim wiederholten Zugriff. Mit ausreichend Lese Cache (Arc, L2Arc) werden bis zu 80% der Lesezugriffe aus dem Cache bedient. Kontrollieren kann man das mit dem arcstat Script.
Will man beim ersten Zugriff bessere Performance oder wenn viele Nutzer viele kleine Dateien bearbeiten, so ist aber ein special vdev Mirror das Mittel der Wahl.
Meingott, ist ZFS nice.
Ich wollt so einen 100gb Ordner mit reichlich "Kleinscheiß" drin auf den drehenden Rost schieben, habs aber wegen schlechten Durchsatz gleich wieder abgebrochen. Dann dachte ich, ich mach ein Archiev draus, als besserer Win-Kacknoob mach ich natürlich erstmal ein 7zip, dauert aber auch ewig (warum auch immer, entweder ist der default-algo so elendig langsam oder... an der Hardware kanns eig. nicht liegen, war alles auf M.2 usw.).
Ich bin dann schnell auf die Idee gekommen einen Tarball draus zu machen, und den einfach so aufs NAS zu schieben (LZ4 eingestellt). .tar war angenehm flott erstellt.
Habs dann aufs NAS geschoben, und die LZ4 Kompression war ähnlich effektiv wie das 7zip (so eins hatte ich noch von der Vorgängerversion des Ordners, Größe fast ident) herumliegen.
Hab mit zfs get compressratio abgefragt, war bei 105% (das 7zip war ähnlich, evtl. im Bereich Richtung 106%).
Ob ich zstd-5 probieren sollte? Wsl. unnötig.
Eigentlich schon ziemlich cool, hat mich heute schon etwas beeindruckt (und ich lass mich nicht so einfach beeindrucken).
Ich mache gerade eine kleine Benchmark Reihe von Controllern (9300-8i vs 9400-8i vs 9500-8i vs 9600-24i alle am Expander vs 9600-24i direct attach).
Interessante Ergebnisse teilweise.
Aktuell kämpfe ich noch mit dem 9600-24i: An dieser Stelle DANKE FÜR NICHTS Broadcom, dass ich manuell per udev regel TRIM aktivieren muss (SSD Micron 5300 PRO SATA, hängt direkt per direct attach backplane am Controller. Data Set Management TRIM supported (limit 8 blocks) + Deterministic read ZEROs after TRIM. Glaube dem Controller passt nicht dass Write Same nicht supported ist
Neueste Firmware + Treiber sind natürlich drauf...
Ergebnisse und fio Skripte lade ich hier ASAP hoch
Kann man schon machen, aber nur wenn man wissen will wie gut der Cache hilft z.B. im Vergleich zu deaktiviertem Cache - nicht wenn man wissen will wie schnell der Pool eigentlich ist.
Ich taste mich gerade an deiner Implementierung von fswatch heran.
Mir stellen sich da ein paar Fragen bez. der Nutzung, denn bei fswatch logs habe ich keine zur Ansicht, mon ist aktiv, daher sitzt die Ursache wohl eher vor den Monitoren ^^
1. Hat die unterschiedliche Beispielangabe bei den Pfaden einen Grund? (.../data1, ../data2 ohne "", bei ../data3, .../data4 ist es mit "")
2. Unter der Voraussetzung, dass es dann funktioniert, stelle ich mir die dann wichtigste Frage, wie nutze ich fswatch, um damit z. B. ein Script ausführen zu lassen. Was ich bisher gefunden habe bezieht sich einmal als Befehl auf die Shell und dann auch auf Linux, nicht auf Solaris. Sollte es da dann überhaupt Unterschiede geben.
- Fswatch kann einen oder mehrere Ordner überwachen
- Zu "", wenn keine Leerzeichen im Pfad sind, kann man die Anführungszeichen auch weglassen
- Man sollte keine Ordner mit zu vielen Dateien überwachen, da hatte ich auch schon kein Log
Hab ein Windows-Backup (der Win7 Backupper am Win10) vom C: gemacht aufs NAS, etwa 300gb.
Auf ein Z1 mit LZ4 (3+1 Ultrastar), habs probehalber auf eine SSD (870 evo sata) kopiert (über den Win Explorer, Daten sind am NAS direkt gegangen, da keine Netzwerklast... wie auch immer das über SMB genau geht, da fehlt mir das Wissen). Das Verschieben war "relativ langsam" ~80-300mb/s je nach dem, ZSTD12 gefühlt langsamer, prakitsch aber ähnlich.
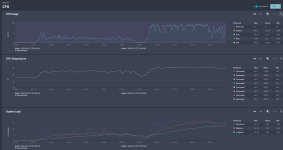
LZ4: Quelle.
ZSTD5: ~27 min, ist am Screenshot der "erste" Lauf. Stromverbrauch nicht gemessen.
ZSTD12: ~30 min, ist am Screenshot abgeschnitten, ist der 2. "Lauf". Viel CPU Load. ~122W, idle macht das NAS ca. 50W.
fastZSTD5: ~26 min, sehr wenig CPU Load, ~65W Aufnahme beim Kopieren.
Müsste man schauen, ob zstd3/4 noch brauchbare jKompression mit weniger Rechenaufwand bringen würde. Freut mich jetzt aber nicht, dauert mir zu lang, und mags nicht mitm halben backup machen.

 ...
...