Hallo,
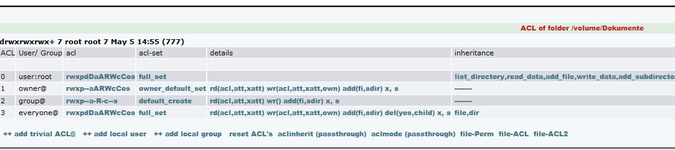
was mich stutzig macht sind die Unix permissions 700 (owner only)
alle meine Shares, bei denen ich von Windows aus die ACLs gesetzt habe, hier also Windowsuser und -groups verrechtet habe, weisen eine Unix permission von 700 auf.
btw:
was ist den ein von Euch praktizierter Weg um die spätere
kostengünstige Erweiterung eines ZFS-Pools sicherstellen zu können. Es gibt ja bestimmte Regeln, die VDEVs auszusehen haben, wenn ein Pool erweitert wird. Bisher habe ich ein RAIDZ2 aus 8x 2TB Platten, eine Erweiterung müsste dann eigendlich durch ein vdev der gleichen Art geschehen, leider nicht sehr preiswert.
Macht es Sinn, die Devices kleiner zu machen, in meinem Fall z.B. 2x ein RAIDZ1 aus 4 Platten, bei einer Erweiterung müssen dann nur 4 weitere Platten gekauft werden, nicht gleich 8. Am feinsten lässt sich eine Erweiterung bei einem Pool aus Mirrors graduieren, hier stört mich aber, das im Ernstfall genau beide Platten eines vdevs ausfallen könnten und der Pool dann hin ist (oder sind dann nur die Daten weg, die gerade auf diesem Mirror lagen?), vom Plattenverbrauch mal ganz abgesehen.
Wie groß bildet Ihr so Eure einzelnen vdevs? RaidZ2 aus 6 Platten? Oder viele kleine RaidZ1 mit ein oder zwei Hotspare für den ganzen Pool?
Das alles natürlich unter dem Aspekt des Privatusers, kein Firmeneinsatz.
@gea: Du bietest für die nichtkommerzielle Heim-Nutzung eigene Preise für Deine Extensions an. Finde ich toll. Gibt es hier auch die Möglichkeit einenen zeitlich nicht beschränkten key zu erhalten, wenn man z.B. gleich für 4 oder 5 Jahre bezahlt?
Gruß Millenniumpilot