
Werbung

Durch Klick auf das Bild gelangt man zu einer vergrößerten Ansicht
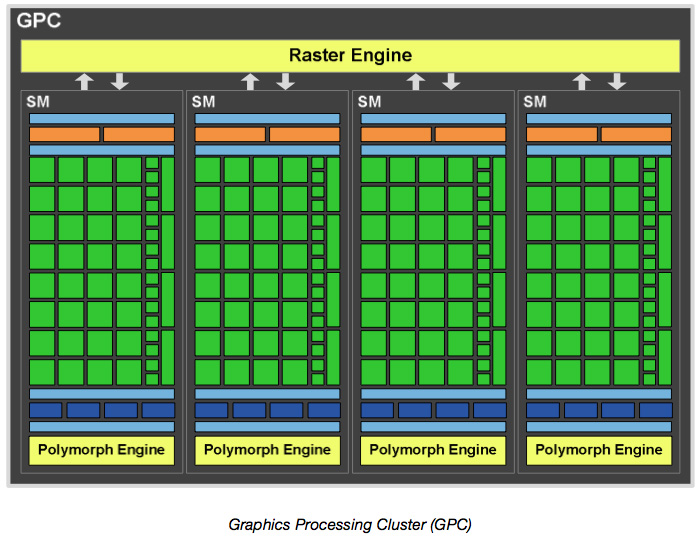
Mit der GF110-GPU erreicht Fermi den von NVIDIA gewünschten Vollausbau mit 512 Shader-Prozessoren. Diese entstammen vier Graphics Processing Clustern (GPC) mit jeweils vier Streaming-Multiprozessoren (SM). Die daraus resultierenden 16 Streaming-Multiprozessoren, die wiederum aus 32 Shader-Prozessoren bestehen, ergeben dann die insgesamt 512 Shader-Prozessoren.
Durch Klick auf das Bild gelangt man zu einer vergrößerten Ansicht
Ein Graphics-Processing-Cluster besteht aus einer Raster-Engine und bis zu vier Streaming-Multiprozessoren. Die GPCs bilden den wichtigsten Block innerhalb der GF110-GPU, denn sie stellen die Basis für die wichtigsten Operationen dar. Das GPC arbeitet effizienter als vorangegangenen Architekturen, da es Vertex-, Geometrie-, Textur- und Pixel-Operationen vereint und gleichzeitig mit den Anforderungen skaliert.
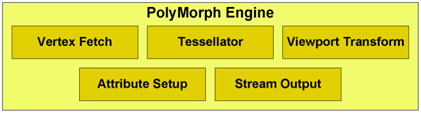
Jede SM-Einheit besitzt eine PolyMorph-Engine, insgesamt kann die GF110 also auf 16 zurückgreifen (bei der GeForce GTX 480 sind es 15). Die PolyMorph Engine ist maßgeblich verantwortlich für Vertex-Fetch, Tessellation, Attribute-Setup, Viewport-Transform und den Stream-Output. Sind die SM-Einheit und die PolyMorph Engine durchlaufen, wird das Ergebnis an die Raster Engine weitergeleitet. In einem zweiten Schritt beginnt dann der Tesselator mit der Berechnung der benötigten Oberflächen-Positionen, die dafür sorgen, dass je nach Abstand der nötige Detailgrad ausgewählt wird. Die korrigierten Werte werden wiederum an die SM-Einheit gesendet, wo der Domain-Shader und der Geometrie-Shader diese dann weiter ausführen. Der Domain-Shader berechnet die finale Position jedes Dreiecks indem er die Daten des Hull-Shaders und des Tesselators zusammensetzt. An dieser Stelle wird dann auch das Displacement-Mapping durchgeführt. Der Geometrie-Shader vergleicht die errechneten Daten dann mit den letztendlich wirklich sichtbaren Objekten und sendet die Ergebnisse wieder an die Tesselation-Engine, für einen finalen Durchlauf. Im letzten Schritt dann führt die PolyMorph-Engine die Viewport-Transformation und eine perspektivische Korrektur aus. Letztendlich werden die berechneten Daten über den Stream-Output ausgegeben, indem der Speicher diese für weitere Berechnungen freigibt. Während diese Schritte als Fixed-Function-Operationen bisher (pre Fermi) in einer Pipeline verarbeitet wurden, können sie auf der GF110 parallel berechnet werden, was die Geschwindigkeit der Berechnung deutlich erhöhen soll.

Vier parallele Raster-Engines sorgen auf der GF100-GPU nach der PolyMorph-Engine für eine möglichst detailreiche Darstellung der errechneten Werte. Dazu ist die Raster-Engine in drei Stufen aufgeteilt. Im Edge-Setup werden nicht sichtbare Dreiecke bestimmt und durch ein "Back Face Culling" entfernt. Jedes Edge-Setup kann pro Takt einen Punkt, eine Linie oder ein Dreieck berechnen. Der Rasterizer zeichnet sich für die Bestimmung der durch Antialiasing berechneten Werte verantwortlich. Jeder Rasterizer kann pro Takt acht Pixel berechnen, insgesamt ist die GF110-GPU also in der Lage 32 Pixel pro Takt zu berechnen. Zum Abschluss vergleicht die Z-Cull-Unit die gerade errechneten Pixel mit bereits im Framebuffer existierenden. Liegen die gerade berechneten Pixel geometrisch hinter denen die sich bereits im Framebuffer befinden, werden sie verworfen.
Die ROP-Units der GF100-GPU wurden bereits entscheidend überarbeitet, um sowohl den Durchsatz als auch die Effizienz zu steigern. Für die neue GF-110-GPU hat sich daran nichts geändert. Acht ROP-Units sind zu einer ROP-Partition zusammengefasst, von denen die GF110-GPU sechs besitzt. Jede ROP-Unit kann einen 32 Bit Integer-Pixel pro Takt ausgeben. Ebenfalls möglich ist ein FP16-Pixel über zwei Takte oder ein FP32-Pixel über vier Takte.
Auch bei der Speicheranbindung hat sich nichts getan. Jede ROP-Partition ist über ein 64 Bit breites Speicherinterface angebunden. Bei sechs ROP-Partitionen kommen wir wieder auf ein 384 Bit breites Speicherinterface.
