

Werbung
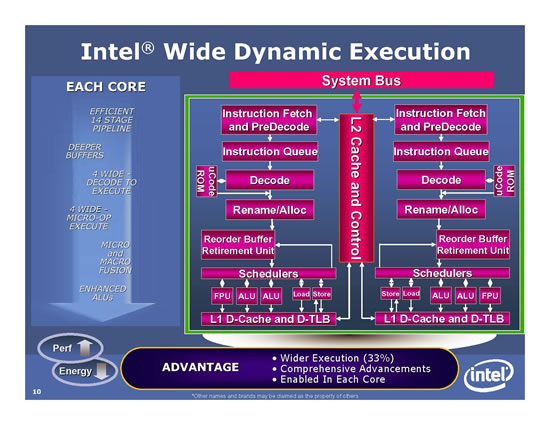
Intel veränderte trotz Ähnlichkeit der Taktfrequenzen zum Core Duo die zugrundeliegende Architektur deutlich. Durch diese Änderungen entstand wohl auch die größte Auswirkung auf die Performance. Bislang arbeiteten der Pentium M und auch der Pentium 4 mit einer dreifach multiskalar ausgelegten Pipeline. Der Core2 Duo besitzt ein vierfach multiskalares Design, er kann also 33 % mehr Befehle gleichzeitig abarbeiten als die bisherigen Prozessoren. Bildhaft vorstellen kann man sich dies mittels einer vierspurigen Autobahn, über die mehr Autos ohne Stau fahren können als bei einer dreispurigen Fahrbahn.
| Core-Architektur | Netburst-Architektur | |
| Design | 4-fach multiskalar | 3-fach multiskalar |
| Pipeline | 14-stufig | 31-stufig |
| Erweiterungen | Micro-Ops Fusion Makro-Fusion | Micro-Ops Fusion |
| Weitere Verbesserungen | Verbesserung der Branch Prediction Größere Zwischenspeicher | - |
Auch wurde die Pipeline verändert: Statt einer 12-stufigen bzw. 31-stufigen Pipeline von Pentium M und Pentium D verwendet die Core-Architektur eine 14-stufige Pipeline, der man zusätzlich größere Puffer spendiert hat. Der L2-Instruction-Cache ist nun 32 kB groß. Zudem analysiert der Prozessor in der Pre-Dekodierphase, ob zwei aufeinanderfolgende Befehle zusammengefasst werden können. Durch Makro-Fusion können zusammengehörige Rechenschritte wie „Compare“ und „Jump“ in einem einzelnen Rechenschritt bearbeitet werden. In älteren Architekturen wurden diese Befehle getrennt abgearbeitet, benötigten also zwei Rechenschritte.
Mit Macro-Fusion ist es möglich, Instruktionen also schneller abzuarbeiten, wenn diese zusammen gehören. Im unteren Bild wurden bislang alle Befehle des Instruction Queues (oben links) einzeln abgearbeitet. Mit Marcro-Fusion können die Instruktionen "cmp eax, [mem2]" und "jne targ" zusammen abgearbeitet werden. Ein µ-Op steht dann für insgesamt zwei Operationen:
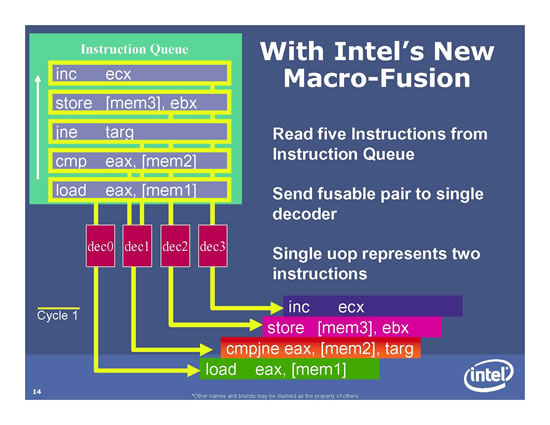
Insgesamt können durch Macro-Fusion also maximal aus dem L1-Cache fünf Instruktionen pro Taktzyklus geholt werden, wenn sich zwei µ-Ops zusammenfassen lassen. Mehrere Zusammenfassungen sind leider nicht möglich, da nur einer der vier Dekoder in der Lage ist, µ-Ops zusammen zu fassen.
Durch die kürzere Pipeline fällt ein Problem der Netburst-Architektur weg: Verspekuliert sich ein Prozessor an einem Schritt der Pipeline beim Vorherbestimmen von Ergebnissen, muss die Pipeline verworfen werden und wieder von Beginn berechnet werden. Also ist die Herausforderung bislang gewesen, durch sehr gute Prefetcher ein Verrechnen zu verhindern. Leider gelingt dies nicht immer - und wenn zu häufig eine komplette Pipeline verworfen werden muss, wird zum einen Strom für die erneute Berechnung verschwendet, zum anderen sinkt aber auch die Performance.
Mit einer 14-stufigen Pipeline ist dieses Problem nicht mehr so gravierend vorhanden, da die Anzahl der Stufen nun niedriger ist. Zudem hat Intel die Branch Prediction verbessert, die Sprungvorhersagen sind somit genauer und ein Leeren der Pipeline ist seltener nötig.
