

Werbung
Die Cache-Architektur der AMD-Prozessoren hatte im Vergleich zum Pentium D bislang einen Vorteil, da dieser Prozessor nur Daten in den Cache des anderen Prozessors übertragen kann, indem er den sowieso schon stark frequentierten FSB nutzt. AMD hat die beiden Kerne über eine Crossbar verbunden und somit ist ein Zugriff schneller möglich. Durch den SmartCache haben jedoch nun wieder der Core Duo und Core2 Duo die Nase vorne.
Die beiden Kerne der Dual-Core-Prozessoren verwenden einen gemeinsamen L2-Cache. Zunächst muss der FSB nicht mehr für den Datentransfer verwendet werden, wodurch die Ressourcen nun für den Speicher voll zur Verfügung stehen. Auch sind keine Daten im Cache doppelt vorhanden, da beide Prozessoren denselben Cache verwenden. Der Clou ist zudem, dass der SmartCache dynamisch auf beide Kerne aufgeteilt werden kann. Ist der erste Kern also beispielsweise gar nicht beschäftigt, steht dem zweiten Kern die komplette Cache-Größe zur Verfügung. Sind beide aktiv, reservieren sie sich genau so viel Platz, wie sie benötigen. Der Cache wird also effektiv genutzt.
Profitieren können im Vergleich also auch Single-Threaded-Anwendungen: Die Core2-Duo-Modelle mit 4 MB L2-Cache reservieren bei derartigen Applikationen die vollen 4 MB Cache für die einzelne Anwendung. Damit laufen auf den neuen Prozessoren auch diese Anwendungen etwas schneller.
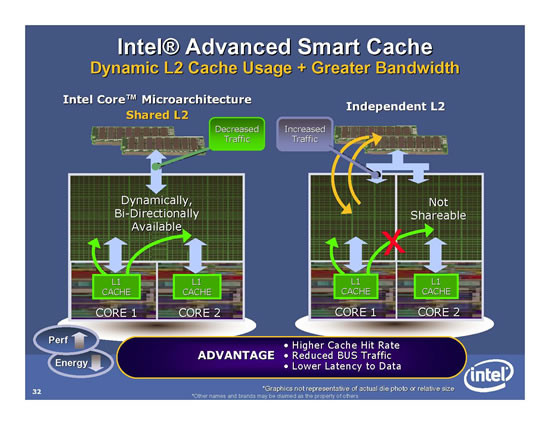
Der SmartCache an sich bewirkt auch wieder ein erhöhtes Stromsparpotential. Der Bus wird weniger belastet:

Die zweite große Verbesserung betrifft den Speicherzugriff. Auch hier hat AMD bislang einen großen Vorteil durch den integrierten Memorycontroller. Durch diesen lässt sich eine extrem gute Latenz zum Speicher erreichen, die Performance ist entsprechend hoch. Allerdings hat ein derartiger Speichercontroller auch diverse Nachteile: Die Implementierung eines neuen Speicherstandards führt zu einem kompletten Redesign eines Prozessors und ist nur mit hohem Aufwand zu erreichen. Demnach legt man sich längerfristig auf einen Standard fest. Auch ist durch den integrierten Controller ein höherer Stromverbrauch in der CPU vorhanden.
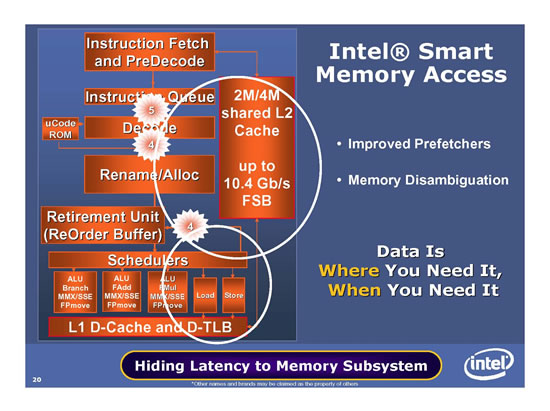
Intel bleibt also beim gesplitteten Ansatz: Memorycontroller in der Northbridge des Chipsatzes, dadurch erkauft man sich eine höhere Flexibilität. Die Performance versucht man hingegen mit Intel Smart Memory Access zu erreichen. Zum einen hat man die Prefetch-Mechanismen verbessert und kann somit schneller die Daten in den Cache laden, die man tatsächlich benötigt. Das Ziel ist es, möglichst keinen Cache-Miss zu bekommen und sämtliche benötigte Daten direkt aus dem großen L2-Cache zu bekommen. Intel hat hierfür zwei Data- und einen Instruction-Prefetcher pro Kern, welche multiple Muster simultan behandeln können. Zusätzlich existieren zwei Prefetcher im L2-Cache. Ein Monitor reguliert die Agressivität und den Trafficbedarf.
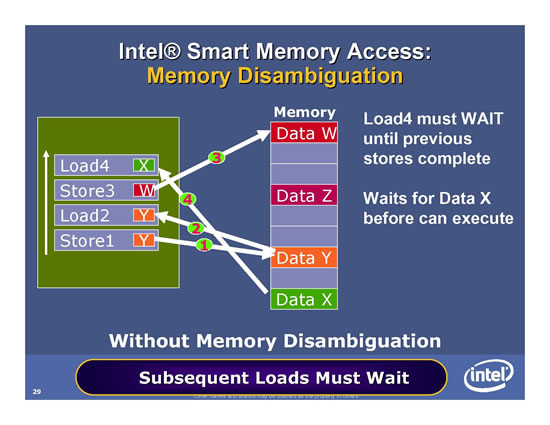
Mittels Memory Disambiguation beschleunigt Intel zudem die Performance der Out-Of-Order Memory Pipelines. Das folgende Bild beschreibt einen Speicherzugriff in einem normalen System ohne Memory Disambiguation. Hier muss das System mit dem Laden der Daten X für "Load4" abwarten, bis die Daten des "Store3"-Befehls im Speicher geschrieben worden sind. Erst im Anschluss können die Daten gelesen werden für den Load4 - hierdurch entsteht eine Wartezeit (Latenz).
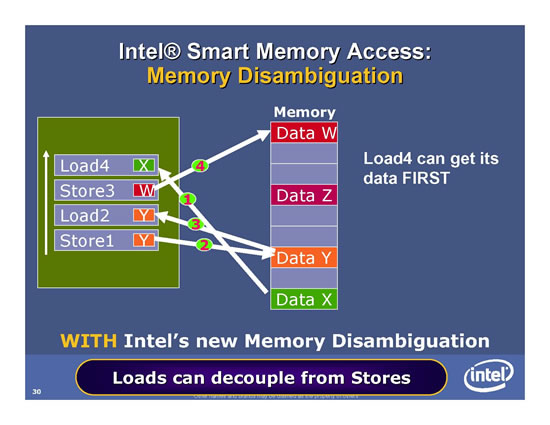
Mit Memory Disambiguation kann der Load4 bereits als erstes ausgeführt werden. Es findet somit eine getrennte Bearbeitung von Loads und Stores statt. Damit dies funktioniert muss der Prozessor vorher überprüfen, ob die Daten im Speicher durch vorherige Rechenschritte eventuell noch verändert werden. Würde diese Überprüfung nicht statt finden, würde der Prozessor eventuell mit falschen Daten rechnen. Aus diesem Grund muss der Prefetcher an dieser Stelle gute Arbeit leisten.
Die Technik ist dabei nichts neues für Intel: In der IA64-Technik setzt Intel bereits seit längerem derartiges ein.
