
Werbung
Wie erwartet hat NVIDIA auf der Keynote der GTC 2022 den Nachfolger der Ampere-Architektur namens Hopper vorgestellt. Die GH100-GPU ist der Datacenter-Ableger – analog zur GA100-GPU der Vorgänger-Architektur. Gefertigt wird die GH100-GPU in 4 nm bei TSMC (N4) und die Anzahl der Transistoren gibt NVIDIA mit 80 Milliarden an. Der Vorgänger brachte es auf 54 Milliarden Transistoren und wurde in 7 nm gefertigt.
Die Hopper-Architektur ist nach Grace Hopper, einer US-amerikanischen Informatikerin benannt. NVIDIA bleibt seiner Tradition die Architekturen nach Mathematikern und Informatikern zu benennen also treu. GH100 lautet der Name der GPU, H100 ist das entsprechende Produkt.
Als erster GPU-Beschleuniger unterstützt die GH100-GPU PCI-Express 5.0 und als Speicher kommen sechs HBM3-Chips mit einer Speicherbandbreite von 3 TB/s und einer Kapazität von 80 GB zum Einsatz. Allerdings scheint NVIDIA nur fünf der vorhandenen sechs Chips zu verwenden – genau wie auf die GA100-GPU. Warum dies der Fall ist, können wir aktuell noch nicht sagen. Die Ausbeute in der Fertigung des Chips dürfte hier aber eine Rolle spielen.
600 W soll sich die GH100-GPU auf dem SMX-Modul genehmigen dürfen. Dies wurde auch in etwa so erwartet, schließlich kam der Vorgänger bereits auf 500 W und bei den GPU-Beschleunigern ist schon länger ein Trend zu 500 W und mehr erkennbar.

Zentrales Element der GH100-GPU sind sicherlich die Recheneinheiten. 18.432 FP32-Recheneinheiten befinden sich in einem H100-Beschleuniger. Hinzu kommen 9.216 INT32- und ebenso viele FP64-Recheneinheiten sowie die Tensor Cores der vierten Generation. Vor allem Berechnungen mit 16 und 8 Bit stehen im Fokus dieser Einheiten. Die Rechenleistung eines H100-Beschleunigers liegt bei 60 TFLOPS für doppelte Genauigkeit (FP64).
| H100 | A100 | Instinct MI250X | |
| Fertigung | 4 nm | 7 nm | 6 nm |
| Anzahl der Transistoren | 80 Milliarden | 54 Milliarden | 58 Milliarden |
| FP64-Rechenleistung (TFLOPS) | 60 | 19,5 | 47,9 |
| FP32/TF32-Rechenleistung (TFLOPS) | 1.000 | 156 | 47,9 |
| FP16-Rechenleistung (TFLOPS) | 2.000 | 624 | 383 |
| FP8-Rechenleistung (TFLOPS) | 4.000 | - | - |
| Speicher | 80 GB HBM3 3 TB/s | 80 GB HBM2 2 TB/s | 128 GB HBM2E 3,2 TB/s |
| PCIe | 5.0 | 4.0 | 4.0 |
| Interconnect | NVLink 900 GB/s | NVLink 600 GB/s | Infinity Links 800 GB/s |
| TDP | 600 W | 500 W | 560 W |
Zunächst einmal aber fällt sicherlich auf, dass NVIDIA für die GH100-GPU bereits auf TSMC N4 zurückgreift, während es beim Vorgänger noch N7 war. AMD fertigt die beiden Chiplets der Instinct MI250X in 6 nm – ebenfalls bei TSMC. Die Komplexität der GH100-GPU wird deutlich, wenn man sich die Anzahl der Transistoren anschaut. 80 Milliarden sollen es hier sein. Die GA100-GPU kam auf 54 Milliarden und die zwei Chips der Instinct MI250X bringen es auf 58 Milliarden.
Wie bereits im ersten Abschnitt erläutert, bleibt es bei 80 GB an Speicher. Der Wechsel von HBM2 auf HBM3 bringt aber ein deutliches Plus in der Speicherbandbreite mit sich. Die 128 GB der Instinct MI250X sind aber sowohl in der Kapazität als auch Bandbreite aktuell nicht zu schlagen.
Etwas schwierig ist der Vergleich der Rechenleistung. NVIDIA gibt hier für den A100-Beschleuniger sowohl die Werte für den Shader-Output, als auch den für eine ideale Auslastung der Tensor Cores an. Diese Maximalwerte haben wir jeweils in die Tabelle aufgenommen. Für den neuen H100-Beschleuniger kennen wir den genauen Aufbau der GPU noch nicht und haben die Were genommen, die NVIDIA uns angegeben hat.

Die externe Anbindung findet einerseits per PCIe 5.0 statt, um die Datenmodelle aber ausreichend schnell zwischen mehreren GPUs austauschen zu können, sieht NVIDIA die vierte Generation des NVLink vor. NVIDIA spricht hier davon, dass die NVLink-Verbindung die siebenfache Bandbreite von PCIe 5.0 erreichen soll. 900 GB/s pro GH100-GPU sind es laut NVIDIA. Die gesamte externe Anbindung der GH100-GPU erreicht laut NVIDIA fast 5 TB/s. Der neue NVLink spielt auch im Zusammenhang mit dem Grace-Prozessor eine wichtige Rolle. Dazu aber mehr in einer gesonderten Meldung.
Transformer Engine und 4. Generation der Tensor Cores
Für die Hopper-Architektur steht einmal mehr maximale Flexibilität im Fokus. Der GPU-Beschleuniger H100 soll sowohl hochpräzise wissenschaftliche Berechnungen mit doppelter Genauigkeit (FP64) als auch solche für AI-Anwendungen (INT8, FP8 und FP16) ausführen können – unter möglichst idealer Nutzung der zur Verfügung stehenden Ressourcen.
Dazu führt NVIDIA mit der Hopper-Architektur einerseits die Tensor Kerne der vierten Generation ein und kombiniert diese mit einer Software- bzw. Ausführungsschicht namens Transformer Engine.
Die Tensor Cores der Hopper-Architektur können Mixed FP8 oder FP16 ausführen. Für FP8 ist der Durchsatz doppelt so hoch wie für FP16. Von NVIDIA trainierte Heuristiken bestimmen, ob die Berechnungen in FP8 oder FP16 durchgeführt werden. TensorFloat32 (TF32) bleibt das Standard-Format in TensorFlow und PyTorch, diese Berechnungen werden von der Transformer Engine aber in FP8 und FP16 zerlegt, um die Hardware in Form der Tensor Cores möglichst ideal zu nutzen.
Das bisher beschriebene betrifft das Training von AI-Modellen. Für das Inferencing weiterhin wichtig sind INT8-Berechnungen. Auch diese können für die Hopper-Architektur optimiert vorbereitet und dann berechnet werden, so dass die H100-Beschleuniger im Vergleich zum Vorgänger ebenfalls deutlich schneller werden sollen.
NVLink Switch System
NVLink kommt aber nicht nur zur Verbindung von acht GH100-GPUs in einem DGX-H100-System zum Einsatz, sondern kann nun per NVLink Switch System auf komplette Racks ausgeweitet werden. Bis zu 256 H100-GPUs kommen somit per NVLink zusammengefasst werden.


Die zusammengefasste Bandbreite in einem NVLink Switch System beträgt 70,4 TB/s. Das Management eines solchen Netzwerk verlangt aber auch eigene Rechenleistung die laut NVIDIA bei 192 TFLOPS liegen soll. Zum Vergleich: Der neue Ethernet-Switch Spectrum-4 kommt auf 50,2 TBit/s (6,275 TB/s).
Neben der Integration in die GH100-GPU sowie für Grace Hopper und den Grace CPU Superchip wird NVLink auch in der Hinsicht geöffnet, dass man dies als Standard sieht, den auch andere Chip-Hersteller umsetzen können, um sich so mit der Hardware von NVIDIA direkt zu verbinden.
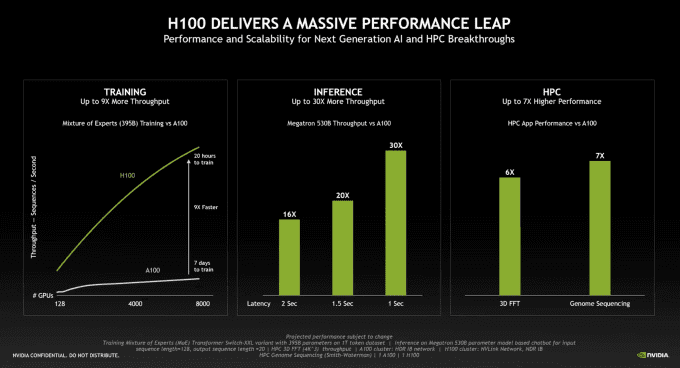
NVIDIA erwartet, dass der H100-GPU-Beschleuniger um den Faktor neun schneller sein kann, als sein Vorgänger. Dies hängt sicherlich auch mit der jeweiligen Anwendung zusammen. Es geht vor allem darum die Zeiten für die einzelnen Trainings-Durchläufe zu reduzieren.
Die H100-GPU wird es sowohl auf einer SMX-Karte als auch als PCI-Express-Steckkarte geben. Zudem packt NVIDIA eine H100-GPU mit einer ConnectX-7 auf ein PCB. Im Edge-Computing sollen die Vorteile der schnellen Anbindung und Verarbeitung ausgespielt werden.
Ab dem dritten Quartal will NVIDIA die ersten H100-GPUs ausliefern. Die Fertigung soll bereits begonnen haben. NVIDIA wird sich auf Basis des H100-GPU-Beschleunigers einen eigenen Supercomputer aufbauen. Dieser soll aus 576 DGX H100-Systemen mit jeweils acht H100 bestehen.
Update:
Nach der Keynote hat NVIDIA einige weitere Details zum Vollausbau des GH100-Chips sowie der Umsetzung der konkreten Produkte in Form der SMX5- und PCIe-Variante veröffentlicht. Der Chip kommt in 4 nm gefertigt auf eine Chipgröße von 814 mm².
| GH100 (Vollausbau) | H100 SMX5 | H100 PCIe | |
| GPCs | 8 | 8 | 7 oder 8 |
| TPCs | 72 | 66 | 57 |
| SMs | 144 | 132 | 114 |
| FP32-Einheiten | 18.432 | 16.896 | 14.592 |
| L2-Cache | 60 MB | 50 MB | 50 MB |
| Tensor Cores | 576 | 528 | 456 |
| Speicher | 96 GB HBM3/HBM2E | 80 GB HBM3 | 80 GB HBM2E |
| TDP | - | 600 W | 350 W |
Der Vollausbau der GH100-GPU kommt auf 8 GPCs, 72 TPCs (9 TPCs pro GPC) und zwei SMs pro TPC. Dies resultiert in 144 SMs für den voll funktionsfähigen Chip. Diesen kann NVIDIA aber in dieser Form nicht nutzen und muss schon für den H100-Beschleuniger rund 10 % der Funktionseinheiten abschalten. Es kommen also nur noch 132 SMs und somit 16.896 Shadereinheiten zum Einsatz. Entsprechend reduziert sich auch die Anzahl der Tensor Cores (vier pro SM) sowie der L2-Cache. Von den sechs HBM3- bzw. HBM2E-Speicherchips sind nur fünf aktiv. Die TDP der PCI-Express-Variante soll bei 350 W liegen.
