
Werbung
Nicht kleckern, sondern klotzen – so könnte das Motto der diesjährigen Hot-Chips-Konferenz lauten. Die Hersteller überbieten sich mit größeren und letztendlich auch schnelleren Chips, doch der Aufwand, der betrieben wird, ist ebenfalls enorm. Über NVIDIAs Blackwell-GPU haben wir bereits berichtet wie über den Telum II von IBM, der mit gigantischen Caches aufwarten kann. Auch Intels Xeon 6 SoC alias Granite Rapids-D ist mit zwei Compute-Chiplets und gefertigt in Intel 3 sowie einem I/O-Chiplet aus der Intel-4-Fertigung nicht minder beeindruckend.
Auf der Hot Chips präsentierten jedoch noch weitere Chiphersteller ihre neusten Designs, bzw. gaben Details zu dem bekannt, was vielleicht schon vor wenigen Monaten angekündigt wurde, es aber nur wenige Details gab. Wir haben ein paar dieser Details zusammengefasst.
Ampere One mit gleich drei Chiplets
Nicht neu, aber für Datacenter-Prozessoren auf die Spitze getrieben, hat Ampere Computing den Chiplet-Ansatz. Die ARM-Kerne stellen eine direkte Konkurrenz zur x86-Übermacht von AMD und Intel dar. Da Microsoft, Amazon und Co. bereits eigene ARM-Prozessoren entwickelt haben, werden eben diese aus den Cloud-Instanzen so schnell nicht wieder verschwinden.
Ampere Computing hat ambitionierte Pläne, hängt diesen im Hinblick auf die Auslieferung der Prozessoren meist aber etwas hinterher. Nichtdestotrotz nutzte man die Hot Chips zur detaillierten Vorstellung des AmpereOne mit 192 Kernen und wahlweise acht oder zwölf DDR-Kanälen.


Zentraler Baustein des AmpereOne ist das Compute-Chiplet mit den bis zu 192 Custom-ARM-Kernen. Diese sind in einem 8x9-Mesh organisiert und per Mesh-Interconnect miteinander verbunden. Die Bandbreite des Meshs soll bei 5,7 TB/s liegen. Gefertigt wird das Compute-Chiplet in 5 nm bei TSMC.
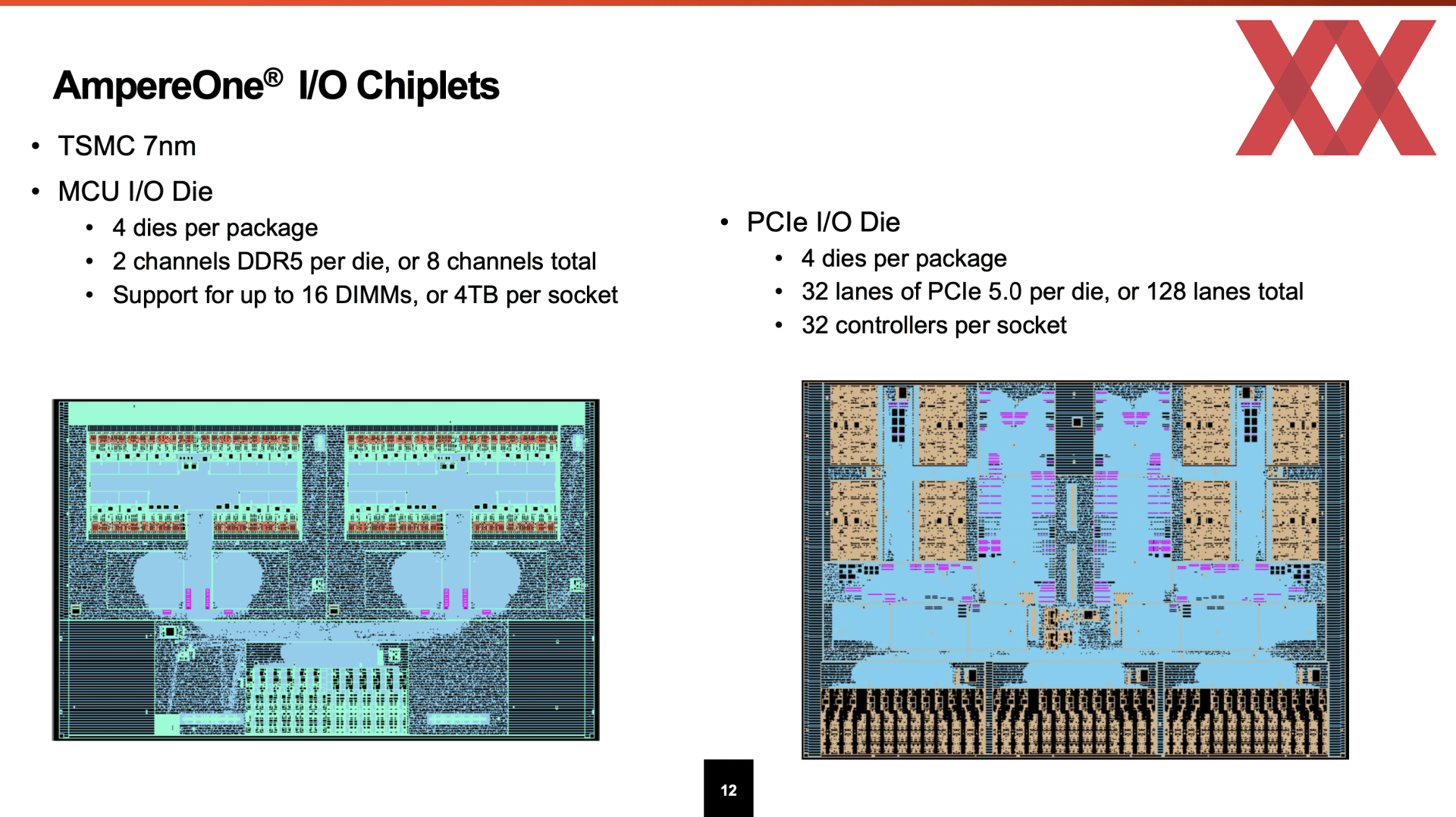
Rings um das Compute-Chiplet platziert AmpereComputing vier PCIe-I/O-Dies. Diese stellen jeweils 32 PCI-Express-5.0-Lanes zur Verfügung. Wahlweise vier oder sechs MCU-I/O-Dies stellen die Speicheranbindung zur Verfügung. Jeder MCU-I/O-Die bietet zwei DDR5-Kanäle, so dass derer entweder acht oder zwölf angeboten werden können. Beide I/O-Dies lässt AmpereComputing in 7 nm bei TSMC fertigen.
Den AmpereOne mit 192 Kernen und acht Speicherkanälen will Ampere Computing aktuell ausliefern. Die Variante mit zwölf Speicherkanälen folgt im vierten Quartal. Als AmpereOne MX soll dann 2025 eine Variante mit 256 Kernen folgen. Weiterhin auf der Roadmap steht der AmpereOne Aurora mit bis zu 512 Kernen.
FuriosaAI setzt auf 12Hi-HBM3 und CoWoS-S
Das südkoreanische Startup FuriosaAI präsentierte auf der Hot Chips RNGD Tensor Contraction Processor, der vor allem für das Inferencing von KI-Modellen vorgesehen ist. Man will es in dieser Hinsicht mit dem Branchen-Primus NVIDIA und den H100-Beschleunigern aufnehmen können, wenngleich hier anzumerken sei, dass NVIDIA bereits die verbesserte Variante H200 sowie in Kürze die Blackwell-Generation im Angebot hat.
Auch für FuriosaAI wird es darum gehen, eine Alternative zu NVIDIA darstellen zu können – sei es über Preis, Verfügbarkeit oder bestenfalls Effizienz.


Der auf der Beschleuniger-Karte eingesetzte SoC wird in 5 nm bei TSMC gefertigt. Die Chipgröße wird mit 653 mm² angeben. Die Anzahl der Transistoren liegt bei etwa 40 Milliarden. Damit bewegt man sich hier im Bereich des IBM Telum II. Dem SoC zur Seite stehen 2x 24 GB HBM3 und das gesamte Package wird ebenfalls bei TSMC mittels CoWoS-S-Technologie gefertigt.
Die Processing Elemente im SoC können auf 256 MB SRAM direkt auf dem Chip zurückgreifen, bevor es dann mit 1,5 TB/s auf den HBM3 geht. Die Bandbreite zum SRAM gibt FuriosaAI mit 384 TB/s an. Der Beschleuniger hat eine TDP von 150 W und kann daher recht einfach gekühlt werden. Mit einer Rechenleistung von 512 TFLOPS für FP8-Berechnungen stellt der RNGD Tensor Contraction Processor in etwa ein Drittel der Rechenleistung einer L40S-GPU von NVIDIA bereit.
Meta MTIA: Kleiner und effizienter Inferencing-Chip
Bereits im Februar sprach Meta erstmals über den MTIA (Meta Training and Inference Accelerator) der zweiten Generation.

Der Chip wird in 5 nm bei TSMC gefertigt und kommt auf eine Chipfläche von 421 mm². Die TDP liegt bei 90 W und unterstreicht, dass Meta den Beschleuniger vor allem auf eine hohe Effizienz beim Inferencing ausgelegt hat. Dem Chip zur Seite stehen 128 GB an LPDDR5-6400 mit einer Speicherbandbreite von 204,8 GB/s. Der Meta MTIA wird bereits in den eigenen Datacentern eingesetzt.
Microsoft Maia 100: Großer Chip mit schneller Anbindung
Ende des vergangenen Jahres sprach Microsoft erstmals über eine Eigenentwicklung: den KI-Beschleuniger Maia 100. Diesen will Microsoft sowohl für das Training als auch das Inferencing einsetzen. Bisher hielt sich der Software-Gigant allerdings mit technischen Details zurück.


Der Chip kommt auf eine Fläche von 820 mm² und wird in 5 nm bei TSMC gefertigt. Die 64 GB an HBM2E kommen auf eine Bandbreite von 1,8 TB/s. Die Integration des gesamten Packages erfolgt ebenfalls bei TSMC im CoWoS-S getauften Verfahren. Microsoft gibt die Gesamtkapazität für den L1- und L2-Cache mit 500 MB an, was vergleichsweise viel ist. Bei guter Effizienz arbeitet der Chip mit einer TDP von 500 W, maximal möglich sind aber auch bis zu 700 W.
Die Anbindung an das Host-System erfolgt über 16 PCI-Express-5.0-Lanes. Das Netzwerk-Backend kommt mit 12 400GbE-Verbindungen auf 600 GB/s.
