Windows weiss im Gegensatz zu früher mit den HDD's nicht, wo was auf der SSD gespeichert ist. Das wird alles durch den SSD-Controller gemanaged.
Ja und nein! HDDs rechnen die LBAs stur auf CHS um und speichern die Daten dann dort, sofern der Sektor nicht durch einen Reservesektor ersetzt und daher umgemappt wurde. Bei SSDs mappt der Controller sowieso die ganze LBAs aus immer wieder anderen Adressen im Flash, da weiß nur er selbst, wo was steht. Aber das Filesystem muss ja trotzdem an die Daten kommen, sonst wären die ja verloren. Das geht eben über die Logische Block Adresse (LBA) und über die werden alle Daten zugeordnet, normalerweise immer 512 Byte für jede LBA.
Nun reichen 512 Byte aber natürlich für die Allermeisten Dateien nicht für aus und damit belegen sie dann mehrere bzw. sogar sehr viele LBAs, alleine schon weil die übliche Clustersize ja 4k beträgt, aber das ist für das eigentlich Problem gar nicht einmal relevant. Schreibt man nun eine 8k große Daten und dann eine 32k große, so belegt die 8k Datei z.B. die ersten 16 LBAs (0-15) und die 32k dann die folgenden 64 LBAs (16-79). Wird die 8k Datei nun vergrößert, etwa weil es eine Log-Datei ist die immer weiter wächst, wird sie fragmentieren, weil die nachfolgenden LBAs ja schon belegt sind, das 2. Fragment wird dann also z:B. die LBAs 80-87 belegen. Dahinter wird wieder eine andere Datei geschrieben und das nächste Fragment landet dann noch weiter hinten usw., sagen wir bis die Datei 128k groß ist.
Liest man diese ganze Datei, so wird eben kein einzelner Lesezugriff über 128k fällig, wie es der Fall wäre wenn die Daten nicht fragmentiert ist, sondern es müssen viele kleine Zugriffe über 8k oder 4k erfolgen, je nach Größe der einzelnen Fragmente und wenn Du Dir mal die Transferraten einer SSD im Verhältnis zum Zugriffslänge ansiehst, z:B. im Ergebnis von ATTO (obwohl der 4 Overlapping I/Os macht, also höhere Werte ausgibt als bei einem einzelnen Zugriff), dann weißt Du eben auch, dass die Transferraten bei 4k oder 8k immer weit unter denen bei 128k liegen und selbst bei 128k, der typischen Länge der Zugriffe bei IOMeter, erreichen die meisten SSD noch nicht einmal ihre Spitzenwerten.
Ein Defragmentieren bringt also rein gar nichts, ausser, dass der SSD-Controller die Daten irgendwie hin und her schiebt.
Deshalb bringt die Defragmentierung durchaus was, denn wenn eine Datei massiv fragmentiert ist, dann werden ja viele Zugriffe über kurzen Längen fällig und die sind nun einmal langsamer, die Daten ja auch intern nicht über so viele NANDs verteilt. Nach dem Defragmentieren liegen die Dateien dann wieder in Zusammenghängenden LBA Bereichen und können mit wenigen Befehlen die lange Zugriffe machen gelesen oder auch überschrieben werden. Wo die Daten im NAND liegen, spielt dabei keine Rolle!
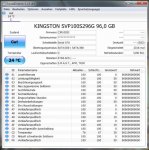
sind diese Probleme bei der V100 auch zu erwarten?
Die Kingston V100 ist uralt, hat eine miesen JM618 Controller, nur SATA 3Gb/s und eine mehr als bescheidene Random Performance, die willst Du doch wohl nicht noch kaufen, zum die
Neu alles andere als günstig ist. Wenn Du schon eine hast, dann sei beruhigt, die V100 ist eben alt und aus einer Zeit, als gute NANDs auch noch besser auf dem Markt verfügbar waren. Außerdem hat sie keinen Sandforce, man hätte bei der Verwendung anderer NANDs also auch andere Angaben zum Performance machen müssen. Die Datenkompression und das Benchen mit extrem komprimierbaren Daten beim Sandforce ersparen das dem Hersteller und der Kunde wird eben überrascht, was die reale Performance angeht, da reale Daten eben nie so extrem komprimierbar sind.



")

")
 Ich huldige ihm auch, um die Beiträge nicht ertragen zu müssen, ist er schon ewig auf der Igno-Liste, anders kann man hier auch gar nicht mehr lesen, hält ja sonst keiner aus.
Ich huldige ihm auch, um die Beiträge nicht ertragen zu müssen, ist er schon ewig auf der Igno-Liste, anders kann man hier auch gar nicht mehr lesen, hält ja sonst keiner aus.