Werbung
Special-Function-Units:
Sogenannte Special-Function-Units (SFUs) übernehmen Berechnungen, die keiner Multiplikation oder Addition entsprechen. Vier dieser SFUs stehen in der GF100-GPU zur Verfügung. Jede SFU kann pro Takt und Thread eine Berechnung durchführen. Größere Befehle können über bis zu acht Takte ausgedehnt werden. Damit die Dispatch-Unit in dieser Zeit nicht auf die SFUs warten muss und weiterhin die übrigen Shader-Prozessoren versorgen kann, arbeiten die SFU-Pipelines getrennt von dieser.
16 Load/Store-Units:
Zu den SMs und SFUs gesellen sich noch Load/Store-Units. Jeder Streaming-Multiprozessor verfügt über 16 Load/Store Units, die für 16 Threads pro Takt die Quell- und Ziel-Adressierung im Speicher und Cache berechnen.
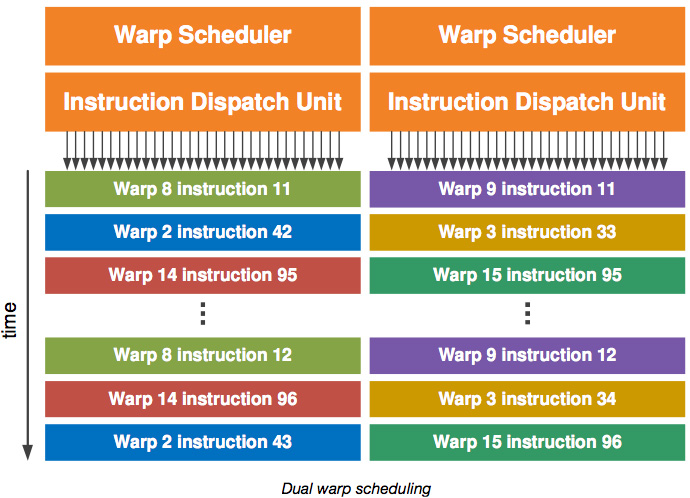
Dual-Warp-Scheduler:
Die Streaming-Multiprozessoren des GF100 verfügen über jeweils zwei Warp-Scheduler und Instruction-Dispatch-Units. Ein Warp ist eine Zusammenstellung von 32 parallelen Threads, die sich die gleiche Pipeline innerhalb der SIMT-Architektur (Single-Instruction, Multiple-Thread) teilen. Der Warp-Scheduler wählt sich zwei Warps und verteilt die zu berechnenden Funktionen auf bis zu 16 Shader-Prozessoren, 16 Load/Store-Units oder die vier SFUs.
Durch Klick auf das Bild gelangt man zu einer vergrößerten Ansicht
Texture-Units:
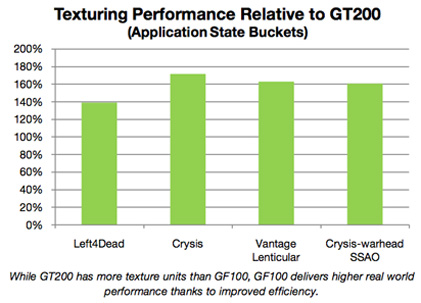
Jede SM-Einheit verfügt über vier Texture-Units. Jede Texture-Unit berechnet Texture-Adressierungen und kann bis zu vier Texturen pro Takt verarbeiten. Das Ergebnis kann dann entweder gefiltert oder ungefiltert zurückgegeben werden. Bekannt sind hier die Filter-Modi Bilinear, Trilinear und das anisotropische Filtern. Soweit entspricht das Vorgehen aber noch dem aus der bekannten GT200-Architektur. NVIDIA hat die Texture-Unit allerdings in die SM-Einheiten verpflanzt, um dort die Effizienz durch die Verwendung des Texture-Caches und den höheren Taktraten zu verbessern. Bei der GT200-Architektur mussten sich drei SM-Einheiten eine Texture-Einheit teilen. Nun verfügt jede SM-Einheit über ihre eigene Texture-Unit und auch über dedizierten L1-Texture-Cache. Zudem arbeiten sie nicht mehr auf den Taktraten der GPU, sondern auf denen der Shader-Prozessoren.
Durch Klick auf das Bild gelangt man zu einer vergrößerten Ansicht
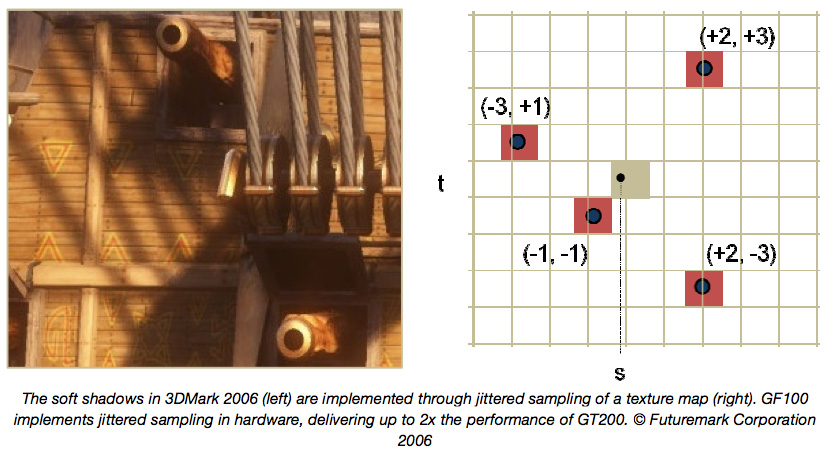
Neben dem dedizierten L1-Texture-Cache, sorgt auch der L2-Cache für eine bessere Performance, denn damit ist der Gesamtspeicher dreimal größer als bei der GT200-Architektur. Zusätzlich unterstützt die GF100-GPU auch noch die BC6H- und die BC7-Texture-Kompression aus der DirectX-11-Spezifikation. Ebenfalls in DirectX-11 vorgesehen ist ein Feature namens Jittered-Sampling durch "Four-Offset-Gather4". Hierbei können aus einem 128x128-Pixel-Feld vier Texel pro Instruction entnommen werden, was die Berechnung von Soft-Shadows, Ambient-Acclusion und dem weiteren Post-Processing erleichtert.