
Werbung
Mit "Kepler" hat NVIDIA zahlreiche Änderungen an der Architektur vorgenommen, die wir uns nun anschauen wollen.


Die Streaming-Multiprozessoren kennen wir schon aus der "Fermi"-Generation. Dort befanden sich in jedem SM 32 Cores. Mit der GeForce GTX 680 bzw. der GK104-GPU setzt NVIDIA nun auf die SMX-Einheiten, die über 192 Cores verfügen. Somit stehen nicht nur insgesamt mehr Cores zur Verfügung, sondern es hat sich auch das Verhältnis von Cores zur Control-Logic deutlich zugunsten der Recheneinheiten gewendet.

Die GeForce GTX 680 kommt mit ihren acht SMX also auf 8 x 192 = 1536 Cores.
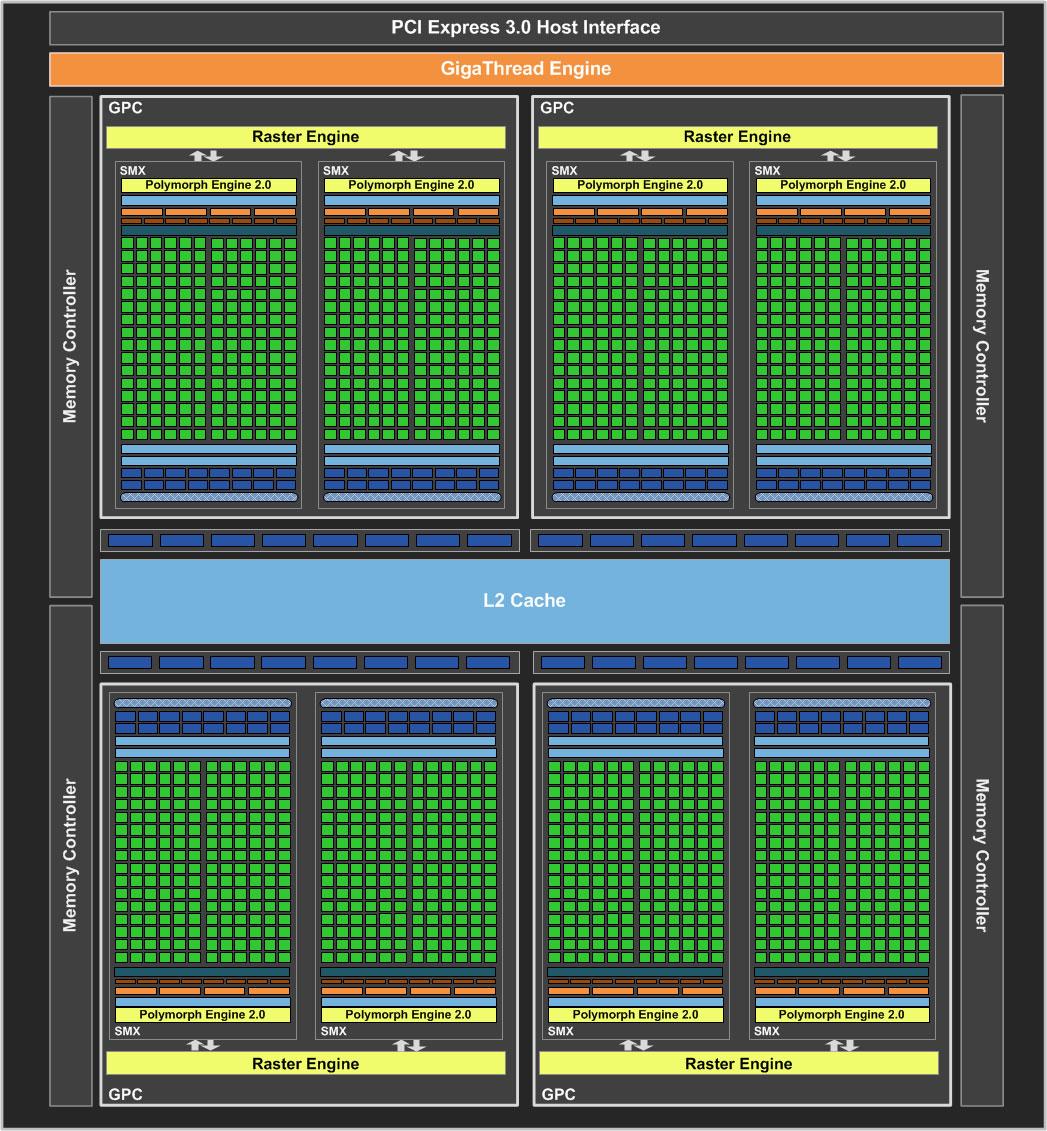
Das Blockdiagramm von "Kepler" zeigt in den äußeren Bereichen das PCI-Express-3.0-Host-Interface sowie die vier Speicher-Controller, die insgesamt auf eine Breite von 256 Bit kommen. Die eigentliche Rechenarbeit wird innerhalb der vier Graphics-Processing-Clustern (GPC), die wiederum aus jeweils zwei SMX-Cluster bestehen, durchgeführt.
Der L2-Cache ist bei "Fermi" 768 kByte groß und erlaubt den Datenaustausch zwischen den Graphics-Processing-Clustern. NVIDIA kann die Größe des L2-Cache bei "Kepler" auf 512 kByte reduzieren, erhöht aber die Bandbreite pro Takt von 384 Byte auf 512 Byte. Innerhalb der SMX-Cluster ist dann noch ein 64 kByte großer L1-Cache bzw. shared Memory zu finden.
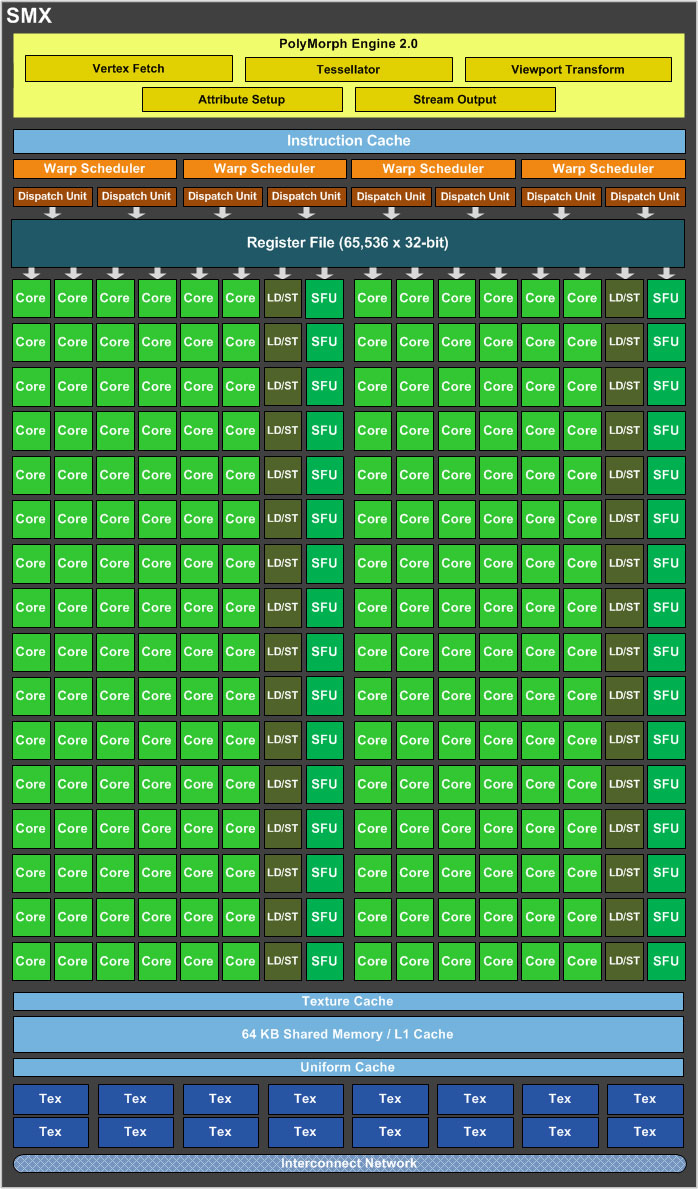
Ein SMX-Cluster besteht aus 192 Cores, 16 Texture-Units und einer Polymorph-2.0-Engine. Jedes SMX-Cluster besitzt eine PolyMorph-2.0-Engine, insgesamt kann der GK104 also auf 8 zurückgreifen (bei der GeForce GTX 580 waren es noch 16). Die PolyMorph-2.0-Engine ist maßgeblich verantwortlich für Vertex-Fetch, Tessellation, Attribute-Setup, Viewport-Transform und den Stream-Output. Sind die SMX-Cluster und die PolyMorph-2.0-Engine durchlaufen, wird das Ergebnis an die Raster-Engine weitergeleitet. In einem zweiten Schritt beginnt dann der Tessellator mit der Berechnung der benötigten Oberflächen-Positionen, die dafür sorgen, dass je nach Abstand der nötige Detailgrad ausgewählt wird. Die korrigierten Werte werden wiederum an das SMX-Cluster gesendet, wo der Domain-Shader und der Geometrie-Shader diese dann weiter ausführen. Der Domain-Shader berechnet die finale Position jedes Dreiecks, indem er die Daten des Hull-Shaders und des Tessellators zusammensetzt. An dieser Stelle wird dann auch das Displacement-Mapping durchgeführt. Der Geometrie-Shader vergleicht die errechneten Daten dann mit den letztendlich wirklich sichtbaren Objekten und sendet die Ergebnisse wieder an die Tessellation-Engine für einen finalen Durchlauf. Im letzten Schritt dann führt die PolyMorph-2.0-Engine die Viewport-Transformation und eine perspektivische Korrektur aus. Letztendlich werden die berechneten Daten über den Stream-Output ausgegeben, indem der Speicher diese für weitere Berechnungen freigibt.
Während die Polymorph-2.0-Engine in weiten Teilen identisch zur "Fermi"-Architektur ist, hatte NVIDIA wieder einmal die Tessellation-Performance im Auge. Gerade nachdem AMD mit der "Southern-Islands"-Generation die Tessellation-Engine deutlich verbessert hatte, wollte NVIDIA diesem Trend nicht entgegen treten. Laut NVIDIA kommt die GeForce GTX 680 auf eine bis zu viermal höhere Tessellation-Performance im Vergleich zur Radeon HD 7970.

Vier parallele Raster-Engines sorgen bei GK104 nach der PolyMorph-2.0-Engine für eine möglichst detailreiche Darstellung der errechneten Werte. Dazu ist die Raster-Engine in drei Stufen aufgeteilt. Im Edge-Setup werden nicht sichtbare Dreiecke bestimmt und durch ein "Back Face Culling" entfernt. Jedes Edge-Setup kann pro Takt einen Punkt, eine Linie oder ein Dreieck berechnen. Der Rasterizer zeichnet sich für die Bestimmung der durch Antialiasing berechneten Werte verantwortlich. Jeder Rasterizer kann pro Takt acht Pixel berechnen, insgesamt ist die GK104-GPU also in der Lage 32 Pixel pro Takt zu berechnen. Zum Abschluss vergleicht die Z-Cull-Unit die gerade errechneten Pixel mit bereits im Framebuffer existierenden. Liegen die gerade berechneten Pixel geometrisch hinter denen, die sich bereits im Framebuffer befinden, werden sie verworfen.
Die ROP-Units wurden bei "Kepler" im Vergleich zu "Fermi" deutlich in ihrer Anzahl überarbeitet. Pro SMX-Cluster verfügt der GK104 über vier ROP-Units, insgesamt kommt die GPU also auf 32. Zum Vergleich: Bei GF110 setzt NVIDIA noch auf 48 ROP-Units. Acht ROP-Units sind zu einer ROP-Partition zusammengefasst, von denen die GK104-GPU vier besitzt. Jede ROP-Unit kann einen 32 Bit Integer-Pixel pro Takt ausgeben. Ebenfalls möglich ist ein FP16-Pixel über zwei Takte oder ein FP32-Pixel über vier Takte.
Die Anzahl der Textur-Units hat sich zum Vorgänger verdoppelt. Jedes SMX-Cluster verfügt über 16 Texture-Units, somit kommt der GK104 auf der GeForce GTX 680 auf 128.
Auch bei der Speicheranbindung hat sich einiges getan. Jede ROP-Partition ist über ein 64 Bit breites Speicherinterface angebunden. Bei vier ROP-Partitionen kommen wir auf ein 256 Bit breites Speicherinterface. GF110 verfügt über sechs ROP-Partitionen und somit über ein 384 Bit breites Interface.

Mit "Kepler" setzt NVIDIA auf eine neue Gewichtung was das Verhältnis der Cores zum Takt und der Control-Logic betrifft. "Fermi" wurde in 40 nm gefertigt und verfügte über 3 Milliarden Transistoren. Die Shader-Prozessoren wurden mit dem doppelten Takt im Vergleich zur restlichen GPU betrieben, um zwei Berechnungen pro GPU-Takt auszuführen. Nur durch diese "Hotclocks" konnte die nötige Rechenleistung erreicht werden.
Mit "Kepler" setzt NVIDIA auf eine neue Fertigung und kann die Problematik der Chipfläche (aufgrund der Fertigung und hohen Anzahl an Transistoren) wieder etwas entschärfen.
