
Werbung
Mit GM107 auf der GeForce GTX 750 und GTX 750 Ti hat NVIDIA bereits bewiesen, dass auch im aktuellen 28-nm-Prozess eine Verbesserung der Effizienz zu erreichen ist. Ob die im Frühjahr gezeigte Steigerung in diesem Bereich allerdings auch auf eine höhere Leistung skaliert, ist einfach abzuschätzen.
Mit der angesprochenen 1. Generation der Maxwell-Architektur hatte NVIDIA das Ziel das Performance/Watt-Verhältnis um den Faktor zwei zu verbessern. Nebenbei sei einmal erwähnt, dass Maxwell inzwischen die 10. Generation einer GPU-Architektur von NVIDIA ist - den Aufkauf von 3dfx und die dort entwickelten Architekturen natürlich eingeschlossen. Etwa 2011 hat man bei NVIDIA damit begonnen an Maxwell zu arbeiten und großen Einfluss hatte dabei auch die gleichzeitige Arbeit an Tegra K1, dem ersten SoC von NVIDIA mit einer vollständigen Desktop-Architektur. Fortschritte bei der Effizienz des Tegra K1 flossen bei Maxwell mit ein.

Das Gesamtschaubild von GM204 mit Maxwell-Architektur zeigt zunächst einmal die um die eigentlichen Recheneinheiten platzierten Module wie das Das PCI-Express-3.0-Interface, die Speichcontroller, den L2-Cache, die ROPs und die GigaThread-Engine, die um das Graphics Processing Cluster angeordnet sind. Vier SMM (Maxwell-Streaming-Multiprozessoren) sind in einem GPC zusammengefasst. Insgesamt verbaut sind in der GM204-GPU vier GPC-Cluster zu jeweils eben vier SMM. Jeder dieser Maxwell-Streaming-Multiprozessoren teilt sich wiederum in vier Blöcke zu je 32 Shadereinheiten auf. 4 GPC x 4 SMM x 4 SMM-Blöcke x 32 ALUs ergeben beim Vollausbau die insgesamt 2.048 Shadereinheiten. Jeder SMM besitzt zusätzlich jeweils acht Textureinheiten. Somit kommt die GM204-GPU auf insgesamt 128 dieser Einheiten. Weiterhin vorhanden sind 64 ROPs und vier Speichercontroller mit jeweils 64 Bit.
Obiger Absatz beschreibt den Aufbau der GM204-GPU auf der GeForce GTX 980. Etwas anders schaut dies bei der GeForce GTX 970 aus, denn hier hat NVIDIA drei SMM deaktiviert, sodass insgesamt nur noch 1.664 Shadereinheiten zur Verfügung stehen (13 SMM x 4 SMM-Blöcke x 32 ALUs = 1.664 Shadereinheiten).
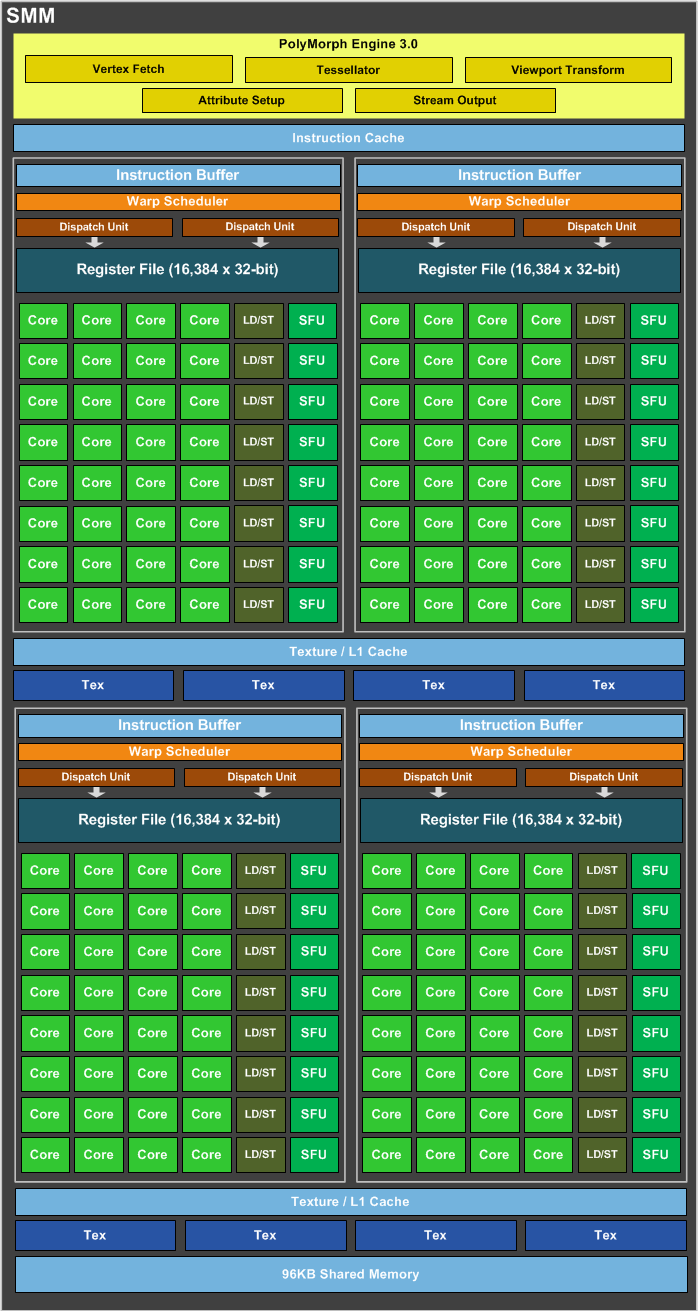
Die höhere Effizienz von Maxwell erreicht NVIDIA durch gleich mehrere Maßnahmen. So hat man den L2-Cache im Vergleich zu Kepler von 256 kB auf 2.048 kB aufgebohrt. Verblieben ist man aber bei einer Bandbreite von 512 Byte pro Takt zu diesem Cache. Im Vergleich zur Maxwell-Architektur der 1. Generation leicht vergrößert hat man den Shared Memory eines jeden SMM. Dieser ist nun 96 kB und nicht mehr nur 64 kB groß. Ebenfalls eine Rolle spielen soll die Polymorph Engine in Version 3.0. Die PolyMorph-3.0-Engine ist maßgeblich verantwortlich für Vertex-Fetch, Tessellation, Attribute-Setup, Viewport-Transform und den Stream-Output. Sind die SMM-Cluster und die PolyMorph-3.0-Engine durchlaufen, wird das Ergebnis an die Raster-Engine weitergeleitet. In einem zweiten Schritt beginnt dann der Tessellator mit der Berechnung der benötigten Oberflächen-Positionen, die dafür sorgen, dass je nach Abstand der nötige Detailgrad ausgewählt wird. Die korrigierten Werte werden wiederum an das SMM-Cluster gesendet, wo der Domain-Shader und der Geometrie-Shader diese dann weiter ausführen. Der Domain-Shader berechnet die finale Position jedes Dreiecks, indem er die Daten des Hull-Shaders und des Tessellators zusammensetzt. An dieser Stelle wird dann auch das Displacement-Mapping durchgeführt. Der Geometrie-Shader vergleicht die errechneten Daten dann mit den letztendlich wirklich sichtbaren Objekten und sendet die Ergebnisse wieder an die Tessellation-Engine für einen finalen Durchlauf. Im letzten Schritt führt die PolyMorph-3.0-Engine die Viewport-Transformation und eine perspektivische Korrektur aus. Letztendlich werden die berechneten Daten über den Stream-Output ausgegeben, indem der Speicher diese für weitere Berechnungen freigibt. Mit diesem Prozess verbunden sind zahlreiche Render-Features, auf die wir auf den kommenden Seiten aber noch ausführlich kommen.

Noch einmal zurück auf die einzelnen SMM-Blöcke: Jedem 32er Block stehen ein Instruction Buffer und ein Warp Schedular zur Verfügung. Jeweils zwei Dispatch Units haben Zugriff auf 16.384 Register mit jeweils 32 Bit. Auch hier lohnt wieder ein Blick auf die "Kepler"-Architektur. 128 Shaderheinheiten werden mithilfe von vier Warp Schedulern und acht Dispatch Units über 65.536 Register bei ebenfalls 32 Bit die Daten bzw. Rechenaufgaben zugeteilt. Jeder Shadereinheit stehen bei Maxwell also theoretisch 512 Register zur Verfügung, während es bei Kepler nur rund 341 sind. Eben solche Maßnahmen sollen auch dazu führen, dass jeder Shader bis zu 35 Prozent schneller arbeiten kann. Weiterhin einen Einfluss hat auch das Verhältnis zwischen Shadereinheiten und den sogenannten Special Function Units (SFU). Während dies bei Kepler 6/1 beträgt, liegt das Verhältnis bei Maxwell bei 4/1. Gleiches gilt auch für die Load/Store Units (LD/ST). Spezielle Double-Precision-Einheiten sind im Blockdiagramm nicht zu sehen und werden vermutlich erst mit einer möglichen GM210-GPU eingeführt werden (analog zur Entwicklung von GK104 zu GK110). Laut NVIDIA beträgt das Single-Precision/Double-Precision-Verhältnis 1/24, so wie auch schon bei den ersten Kepler-Chips der ersten Generation (GK104).
