

Werbung
Verbesserungen der Kerne
Die Architektur des Penryn, also die Core-Mikroarchitektur, hat Intel noch an einigen Stellen beim Bloomfield-Kern aufbohren können: Macrofusion wurde nun auch im 64-Bit-Modus unterstützt, ein neuer Loop Stream Detector beinhaltete nun auch die Decode-Funktion, weiterhin erkennt der Loop Detector Schleifen zuverlässiger. Wie bei fast jedem neuen Prozessor hat Intel auch die Branch-Prediction-Einheit wieder einmal verbessert. Hierdurch wird eine höhere Performance und ein niedrigerer Stromverbrauch erreicht, da bei einer fehlerhaften Sprungvorhersage der Arbeitsschritt erneut berechnet werden muss.
Die Execution-Engine hat Intel verändern müssen, da bei der Nehalem-Mikroarchitektur nun 128 µOps abgearbeiten werden können (Merom 96, Dothan 64). Um die Engine also ständig zu füllen, mussten vorgelagerte Strukturen verbessert werden. So besitzen die Reservation Station, Load Buffers und Store Buffers mehr Ressourcen.
Aber: Intel setzt für den Bloomfield-Prozessor und den Lynnfield-Prozessor dieselben Kerne ein - verändert hat sich also hier nichts.
Caches
Jeder Nehalem-Core (also sowohl Lynnfield als auch Bloomfield) besitzt einen 32 kB großen Instruction- und einen 32 kB großen Data-Cache. Hinzu kommt ein 256 kB großer L2-Cache. Im Vergleich zum bisherigen 6 MB großen L2-Cache des Penryns ist dieser also deutlich kleiner, dafür aber sehr viel schneller angebunden. Zudem kann jeder Core auf seinen eigenen L2-Cache zugreifen. Einen ähnlichen gemeinsamen Cache wie beim Penryn gibt es erst auf L3-Ebene: Hier kommt beim Nehalem ein 8 MB großer Shared-L3-Cache (16-fach assoziativ) zum Einsatz. Alle Caches sind inclusive, alle L1-/L2-Register sind also auch im L3-Cache gespeichert. Der Nehalem besitzt einen Snoop-Filter, der alle Nachteile eines Inclusive-Caches ausmerzen soll.
Auch bei den Caches gibt es Unterschiede zwischen dem Core- und Uncore-Bereich: Die L1- und L2-Caches laufen auf Prozessortakt, also auf 2,66 bis 3,2 GHz, je nach Prozessormodell. Der Uncore-Bereich läuft hingegen auf einer anderen Taktfrequenz und somit auch der L3-Cache, der Bestandteil des Uncore-Bereiches ist.
Intel hat neue unified 2nd-Level-TLB (Translation-Lookaside-Buffers) implementiert, weiterhin können unaligned Cache Accesses (MOVUPS/D, MOVDQU) nun genauso schnell abgearbeitet werden, als wenn sie „aligned“ wären.
Hyperthreading
Intel besitzt mehrere Design-Teams, die sich abwechseln: Der Nehalem entstammt aus der Feder des Design-Teams in Oregon, die zuletzt mit der Pentium-4-Architektur eine Bruchlandung namens Prescott hingelegt hatten. Ein Feature besaß der Prescott jedoch, das ihm in einigen Benchmarks zu einer gehörigen Mehrperformance verhalf: Hyperthreading. Das gesammelte Know-How hat das Design-Team aus Oregon in die Core-Mikroarchitektur einfließen lassen und verhilft Hyperthreading nun zu einem Comeback in verbesserter Form.

Die korrekte Bezeichnung für Hyperthreading ist „Simultaneous Multithreading“, es können also zwei Threads zur gleichen Zeit von einem Kern bearbeitet werden. Aus diesem Grund sind im Taskmanager beim Core i7 auch acht Threads zu sehen: Jeder Kern kann zwei Threads abarbeiten, also sind maximal acht Threads gleichzeitig möglich. Hyperthreading bringt beim bestehenden Core-Design einen Vorteil, da die vierfach multiskalare Ausführungseinheit besser mit Aufgaben gefüttert werden kann. Hyperthreading bringt so einen Performancevorteil bei minimalen Kosten und minimal höherem Stromverbrauch, da nur wenige Transistoren pro Kern hinzukommen und somit die Die-Fläche kaum steigt.
Beim Lynnfield-Prozessor unterstützt nur der Core i5 kein Hyperthreading: Er besitzt nur reine vier Kerne ohne diese Funktion.
Exkurs: Performanceauswirkung von Hyperthreading
„Simultaneous Multi-Threading“ lässt sich im BIOS der meisten Mainboards abschalten - dann läuft der Core i7 nur mit seinen vier Kernen, er arbeitet dann nur einen Thread pro Core ab. Sinn macht die Abschaltung allerdings nicht mehr, während früher Hyperthreading bei einigen Programmen Probleme bereitete: Wenn eine Applikation noch nicht für den Multi-Thread-Bereich ausgelegt war oder die Workloads ungünstig aufgeteilt hat, konnte es zu kleineren Einbußen in der Performance kommen. Mittlerweile sind aber sämtliche Standardapplikationen und auch die Betriebssysteme für den Multi-Thread-Bereich optimiert - schon aufgrund der Multi-Core-Prozessoren. Probleme kann es allerdings noch in Spielen geben, wo die Performance leicht unter dem reinen Vierkern-Betrieb liegt.
Von Hyperthreading profitieren allerdings nur Programme, die ihre Workload auch auf mehrere Threads aufteilen können. Single-Task-Programme wie SuperPi nutzen nur einen Thread und zeigen deshalb keine Reaktion. Auch Programme, die beispielsweise vier Threads nutzen zeigen im Core i7 keine Beschleunigung, da sie aufgesplittet auf vier Kerne mit einer identischen Performance laufen. Hyperthreading macht dann nur für den Multi-Tasking-Bereich Sinn, wenn also mehrere Programme parallel ablaufen müssen (Virusscanner, Firewall, Backup-Software im Hintergrund).
Wir haben drei klassische Benchmarks ausgesucht, die alle mehr als vier Threads nutzen können und zeigen die Performanceauswirkungen von Hyperthreading in diesem optimalen Fall:
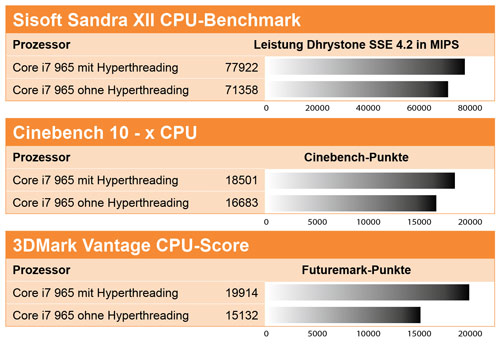
Für den Test schalteten wir den Turbo-Modus des Core i7 ab, um möglichst wenig Einfluss anderer Bereiche auf das Ergebnis zu haben. Wie zu sehen ist, hat Hyperthreading teilweise einen massiven Einfluss auf die Performance. Im 3DMark Vantage erreicht der Prozessor eine um 33% gesteigerte Leistung - vergleichend könnte man sagen, dass hier ein Sechs-Kern-Prozessor ohne Hyperthreading notwendig wäre, um die Leistung des Quad-Cores mit Hyperthreading zu erreichen. Derartig massiv sind die Geschwindigkeitsvorteile in anderen Bereichen nicht, auch wenn 11% mehr bei Cinebench und knapp 9 % mehr bei Sisoft Sandra ein sehr gutes Ergebnis sind.
Interessant ist natürlich gleichzeitig auch ein Blick auf den Energieverbrauch des Prozessors. Bei Cinebench 10 wurde ein Anstieg von 10 % gemessen - hier entspricht der Mehrverbrauch also ungefähr der zusätzlichen Leistung. Im Idle-Betrieb ändert sich der Energieverbrauch des Prozessors nicht.
Virtualisierung, SSE 4.2 und weiteres
Im Hinblick auf eine verbesserte Performance bei der Nutzung der Virtualisierung hat Intel die Latenzzeit zwischen den Wechseln zwischen virtuellen Maschinen beschleunigt und Extended Page Tables hinzugefügt, um die Anzahl der Wechsel zu minimieren. Durch eine Virtual Processor ID muss zudem der TLB bei Wechseln nicht mehr geleert werden.
Auch SSE hat Intel beim Nehalem zu SSE4.2 aufgebohrt: Neue Instruktionen kommen im Vergleich zum Penryn hinzu (STTNI, ATA). Veränderungen vom Bloomfield zum Lynnfield-Kern haben sich auch hier nicht ergeben.
