Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
-
Hardwareluxx führt derzeit die Hardware-Umfrage 2025 (mit Gewinnspiel) durch und bittet um eure Stimme.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
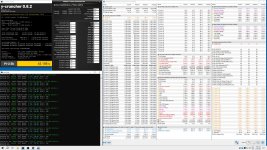
[Sammelthread] Intel DDR5 RAM OC Thread
- Ersteller even.de
- Erstellt am
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.480
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
Im Optimalfallinnerhalb von 60mV liegen oder mindestens voneinander weg sein?
90-105 wären schön, aber dann kommt RTT instabilität ins Spiel.
60 passt ganz gut.
Bis maximal 300mV, wobei ich bislang nur bis 240mV "stabil" sah.
Es ist nicht mein Ergbeniss, weswegen es "eventuell bis 240mV" heißt
VDDQ_CPU = VDDQ_MEM minus X (Delta)VDDQ TX?
bedeutet
SA 1,175 VDDQTX =>1,325
Und VDDQ_CPU sollte über SA sein.
amd_man_bavarian
Experte
- Mitglied seit
- 23.09.2023
- Beiträge
- 740
- Ort
- BoB
- Details zu meinem Desktop
- Prozessor
- ! Intel Core Ultra 7 265Kf !
- Mainboard
- MSI MEG Z890 ACE
- Kühler
- Alpenföhn Brocken 4 Max + 2x Noctua NFA12x25 chromax black swap
- Speicher
- ADATA XPG Lance DDR5 9200 @ 8933 C40
- Grafikprozessor
- ASUS Tuf RTX 4070TI Super OC
- SSD
- Samsung 990Pro 1TB
- HDD
- --
- Opt. Laufwerk
- --
- Soundkarte
- Realtek ALC4080 + DAB
- Gehäuse
- Endorfy ARX 700 Air
- Netzteil
- BeQuiet Dark Power Pro 11 650W Platinum
- Betriebssystem
- Windows 11 Pro 24H2
- Webbrowser
- FireFox
- Internet
- ▼50MBit ▲10 MBit
Guten Morgen
Da mein I5 immer noch in der RMA unterwegs ist habe ich mir zwischenzeitlich Ersatz besorgt. Laut Asrock CPU Bewertung hat dieser einen SP von 81, was bisher mein höchster Wert für einen I5 ist.
So wie es scheint ist es ein ganz guter. Oder wie ist Eure Meinung dazu ?
Bisher scheinen 7800 MT/s stabil auf den Asrock Z790 Nova zu laufen.
Ich habe Ihn auf 5,7 P-Cores / 4,3 E-Cores @ Offset +0,55 ~VCore 1,32V
Für den Ram SA 1,085V , VDD CPU 1,35V , VDD_MRC 1,175V , VDD_IMC 1,35V , VDD 1,45V , VDDQ 1,39V , VPP 1,805V
Das Ganze schaut bisher so aus (Wobei der Focus Richtung Stabilität und nicht zum Benchen oder für Rekorde geht) :




TM5 oder Karhu hab ich noch nicht getestet, aber das kommt noch.
Schöne Grüße und Frohe Ostern,
Andreas
Da mein I5 immer noch in der RMA unterwegs ist habe ich mir zwischenzeitlich Ersatz besorgt. Laut Asrock CPU Bewertung hat dieser einen SP von 81, was bisher mein höchster Wert für einen I5 ist.
So wie es scheint ist es ein ganz guter. Oder wie ist Eure Meinung dazu ?
Bisher scheinen 7800 MT/s stabil auf den Asrock Z790 Nova zu laufen.
Ich habe Ihn auf 5,7 P-Cores / 4,3 E-Cores @ Offset +0,55 ~VCore 1,32V
Für den Ram SA 1,085V , VDD CPU 1,35V , VDD_MRC 1,175V , VDD_IMC 1,35V , VDD 1,45V , VDDQ 1,39V , VPP 1,805V
Das Ganze schaut bisher so aus (Wobei der Focus Richtung Stabilität und nicht zum Benchen oder für Rekorde geht) :
TM5 oder Karhu hab ich noch nicht getestet, aber das kommt noch.
Schöne Grüße und Frohe Ostern,
Andreas
xST4R
Enthusiast
- Mitglied seit
- 22.10.2017
- Beiträge
- 3.860
Tausch
wenn der focus stabilität ist , frage ich mich wieso du diese nicht auch Testes ? die von dir verwendeten benchmarks sind nicht geeignet um diese zu bestimmen ...
Guten Morgen
Da mein I5 immer noch in der RMA unterwegs ist habe ich mir zwischenzeitlich Ersatz besorgt. Laut Asrock CPU Bewertung hat dieser einen SP von 81, was bisher mein höchster Wert für einen I5 ist.
So wie es scheint ist es ein ganz guter. Oder wie ist Eure Meinung dazu ?
Das Ganze schaut bisher so aus (Wobei der Focus Richtung Stabilität und nicht zum Benchen oder für Rekorde geht) :
wenn der focus stabilität ist , frage ich mich wieso du diese nicht auch Testes ? die von dir verwendeten benchmarks sind nicht geeignet um diese zu bestimmen ...
amd_man_bavarian
Experte
- Mitglied seit
- 23.09.2023
- Beiträge
- 740
- Ort
- BoB
- Details zu meinem Desktop
- Prozessor
- ! Intel Core Ultra 7 265Kf !
- Mainboard
- MSI MEG Z890 ACE
- Kühler
- Alpenföhn Brocken 4 Max + 2x Noctua NFA12x25 chromax black swap
- Speicher
- ADATA XPG Lance DDR5 9200 @ 8933 C40
- Grafikprozessor
- ASUS Tuf RTX 4070TI Super OC
- SSD
- Samsung 990Pro 1TB
- HDD
- --
- Opt. Laufwerk
- --
- Soundkarte
- Realtek ALC4080 + DAB
- Gehäuse
- Endorfy ARX 700 Air
- Netzteil
- BeQuiet Dark Power Pro 11 650W Platinum
- Betriebssystem
- Windows 11 Pro 24H2
- Webbrowser
- FireFox
- Internet
- ▼50MBit ▲10 MBit
Tausch
wenn der focus stabilität ist , frage ich mich wieso du diese nicht auch Testes ? die von dir verwendeten benchmarks sind nicht geeignet um diese zu bestimmen ...
TM5 oder Karhu hab ich noch nicht getestet, aber das kommt noch.
Da ich die CPU seit gestern gestern habe, hatte ich noch nicht die Zeit zum länger testen.
Wenn Y-Cruncher nicht funktioniert brauche ich die Stabilität garnicht erst testen. Wobei anzumerken ist das einschlägige OC-Foren sehr oft Y-Cruncher für Stabilitätstests nutzen. Ein Beispiel hierfür ist u.a. Igorslab .
Wie bereits gesagt kommen die hier häufig genutzen Test auch noch .
xST4R
Enthusiast
- Mitglied seit
- 22.10.2017
- Beiträge
- 3.860
erstmal glückwunsch zur neuen cpu ,
ycruncher ist ja auch richtig , allerdings mit einem VST benchmark und nicht einem "normalen"")
und igorslab kann man sich sparen ... siehe vermutliche "Manipulation" an Ergebnissen vom Apex Lüfter Test ...
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Youtube Videos ab jetzt direkt anzeigen
um den ram zu testen ist karhu/tm5/ycruncher mit vst profil genau das richtige alles andere zeigt im grunde genau garnichts
grüße und einen schönen tag
ycruncher ist ja auch richtig , allerdings mit einem VST benchmark und nicht einem "normalen"
und igorslab kann man sich sparen ... siehe vermutliche "Manipulation" an Ergebnissen vom Apex Lüfter Test ...
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Youtube Videos ab jetzt direkt anzeigen
um den ram zu testen ist karhu/tm5/ycruncher mit vst profil genau das richtige alles andere zeigt im grunde genau garnichts
grüße und einen schönen tag
Zuletzt bearbeitet:
amd_man_bavarian
Experte
- Mitglied seit
- 23.09.2023
- Beiträge
- 740
- Ort
- BoB
- Details zu meinem Desktop
- Prozessor
- ! Intel Core Ultra 7 265Kf !
- Mainboard
- MSI MEG Z890 ACE
- Kühler
- Alpenföhn Brocken 4 Max + 2x Noctua NFA12x25 chromax black swap
- Speicher
- ADATA XPG Lance DDR5 9200 @ 8933 C40
- Grafikprozessor
- ASUS Tuf RTX 4070TI Super OC
- SSD
- Samsung 990Pro 1TB
- HDD
- --
- Opt. Laufwerk
- --
- Soundkarte
- Realtek ALC4080 + DAB
- Gehäuse
- Endorfy ARX 700 Air
- Netzteil
- BeQuiet Dark Power Pro 11 650W Platinum
- Betriebssystem
- Windows 11 Pro 24H2
- Webbrowser
- FireFox
- Internet
- ▼50MBit ▲10 MBit
Ich weiß das natürlich FFT und VST zum testen bei Y-Cruncher genutzt wird. Aber um mal hallo zu sagen taugt auch der kurze Bench.
Naja Igorslab würde ich nicht abschreiben, gerade im Bezug auf die Ram tests, denn die hat überwiegend nicht der entfernte Pascal gemacht.
Ich hätte genauso Overclock.net nennen können.
Selbst Cinebench zeigt schon unstimmigkeiten beim Ram an, daher auch der kurze test mit Super Pi 32M welcher dieses ebenfalls aufzeigt.
Aber ich werde mich bemühen die Anerkannten Stabilitätstests nachzureichen")
Wie gesagt hab ich die CPU erst seit gestern und hatte Nachtschicht und somit nicht die zeit genaueres zu sagen und zu zeigen, weshalb ich ja schrieb
Auch Dir Grüße und einen schönen Tag 🐰
FFT und VST zum testen bei Y-Cruncher genutzt wird. Aber um mal hallo zu sagen taugt auch der kurze Bench.Naja Igorslab würde ich nicht abschreiben, gerade im Bezug auf die Ram tests, denn die hat überwiegend nicht der entfernte Pascal gemacht.
Ich hätte genauso Overclock.net nennen können.
Selbst Cinebench zeigt schon unstimmigkeiten beim Ram an, daher auch der kurze test mit Super Pi 32M welcher dieses ebenfalls aufzeigt.
Aber ich werde mich bemühen die Anerkannten Stabilitätstests nachzureichen
Wie gesagt hab ich die CPU erst seit gestern und hatte Nachtschicht und somit nicht die zeit genaueres zu sagen und zu zeigen, weshalb ich ja schrieb
Bisher scheinen 7800 MT/s stabil auf den Asrock Z790 Nova zu laufen
Auch Dir Grüße und einen schönen Tag 🐰
xST4R
Enthusiast
- Mitglied seit
- 22.10.2017
- Beiträge
- 3.860
Ich weiß das natürlich
Naja Igorslab würde ich nicht abschreiben, gerade im Bezug auf die Ram tests, denn die hat überwiegend nicht der entfernte Pascal gemacht.
Ich hätte genauso Overclock.net nennen können.
Selbst Cinebench zeigt schon unstimmigkeiten beim Ram an, daher auch der kurze test mit Super Pi 32M welcher dieses ebenfalls aufzeigt.
Aber ich werde mich bemühen die Anerkannten Stabilitätstests nachzureichen
Wie gesagt hab ich die CPU erst seit gestern und hatte Nachtschicht und somit nicht die zeit genaueres zu sagen und zu zeigen, weshalb ich ja schrieb
Auch Dir Grüße und einen schönen Tag 🐰
ich hab igorslab abgeschrieben , wer so mit seiner com und generell mit allen leuten umgeht gehört hier nicht mehr hin ... in die tech welt. und wieso sollte man einem unabhängigen labor noch IRGENDWAS glauben nach dieser geschichte da ... wer einmal lügt dem glaubt man nicht ... das sprichtwort gibts ja nicht ohne grund ...
gibt schon genügend youtuber die gekauft sind und nur quatschen was die firmen wollen ... da brauch ich nicht auch noch sowas als "testlabor"
und ich seh das auch komplett anders ein "normaler bench" sagt 0 aus auch ein cb23 sagt nicht viel über den ram aus
aber gut , meinungen dürfen auch auseinander gehen
amd_man_bavarian
Experte
- Mitglied seit
- 23.09.2023
- Beiträge
- 740
- Ort
- BoB
- Details zu meinem Desktop
- Prozessor
- ! Intel Core Ultra 7 265Kf !
- Mainboard
- MSI MEG Z890 ACE
- Kühler
- Alpenföhn Brocken 4 Max + 2x Noctua NFA12x25 chromax black swap
- Speicher
- ADATA XPG Lance DDR5 9200 @ 8933 C40
- Grafikprozessor
- ASUS Tuf RTX 4070TI Super OC
- SSD
- Samsung 990Pro 1TB
- HDD
- --
- Opt. Laufwerk
- --
- Soundkarte
- Realtek ALC4080 + DAB
- Gehäuse
- Endorfy ARX 700 Air
- Netzteil
- BeQuiet Dark Power Pro 11 650W Platinum
- Betriebssystem
- Windows 11 Pro 24H2
- Webbrowser
- FireFox
- Internet
- ▼50MBit ▲10 MBit
Andere Quelle zum thema Ram zusammenhang und Cinebench Siehe 22.30 :
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Youtube Videos ab jetzt direkt anzeigen
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Youtube Videos ab jetzt direkt anzeigen
zebra_hun
Profi
Ich teile jetzt eine Erfahrung darüber, wie empfindlich der LGA1700-Sockel ist.
Ich habe die CPUs gewechselt, weil ich eine andere gekauft habe. Im Moment habe ich nebenbei die alte CPU umgebaut, die viele Tests bestanden hat.
Natürlich ist es nicht stabil, es ist unmöglich, es zweimal auf die gleiche Weise zu installieren. Ich habe keinen Drehmomentschraubendreher (Nm), ich glaube, ich ziehe ihn ganz normal von Hand an.
Bisher war kein LGA-Sockel so empfindlich.
Was war das Fehlerphänomen? Y Cruncher war instabil. Er rannte keine einzige Minute. Der Sockel und die Unterseite der CPU sind sauber, kein Schmutz. Aufgrund der Rohre ist es nicht leicht zu entfernen.
Ich habe es zum ersten Mal mit der IMC-Spannung versucht, 1,35750 V oder 1,35650 V statt 1,35 V (nächster Schritt), Fehler im 3. Schritt.
SA hat auch nicht geholfen.
Interessanterweise löste die Erhöhung von TX auf 1,21–1,215 V das Problem sofort.
Ich werde es nicht herausnehmen und wieder einbauen, da die neue CPU in 1 Woche eingebaut wird, und dann mit ihr.
Wenn ich es herausnehme, erhalte ich in jedem Fall einen anderen MCSP, aber einen stabilen Wert. Jetzt beträgt er aktuell 74 76 76 76.
Wenn ich mich richtig erinnere, waren es auch 84. Ich weiß nicht, ob es an der hohen Frequenz oder am schlechten Kontakt liegt. Tatsächlich reagiert der LGA1700 zu empfindlich auf Druck. Schlimm, das hatte ich noch nie zuvor.
Nur eine Stunde lang getestet, gehts gut wieder.
Ich habe die CPUs gewechselt, weil ich eine andere gekauft habe. Im Moment habe ich nebenbei die alte CPU umgebaut, die viele Tests bestanden hat.
Natürlich ist es nicht stabil, es ist unmöglich, es zweimal auf die gleiche Weise zu installieren. Ich habe keinen Drehmomentschraubendreher (Nm), ich glaube, ich ziehe ihn ganz normal von Hand an.
Bisher war kein LGA-Sockel so empfindlich.
Was war das Fehlerphänomen? Y Cruncher war instabil. Er rannte keine einzige Minute. Der Sockel und die Unterseite der CPU sind sauber, kein Schmutz. Aufgrund der Rohre ist es nicht leicht zu entfernen.
Ich habe es zum ersten Mal mit der IMC-Spannung versucht, 1,35750 V oder 1,35650 V statt 1,35 V (nächster Schritt), Fehler im 3. Schritt.
SA hat auch nicht geholfen.
Interessanterweise löste die Erhöhung von TX auf 1,21–1,215 V das Problem sofort.
Ich werde es nicht herausnehmen und wieder einbauen, da die neue CPU in 1 Woche eingebaut wird, und dann mit ihr.
Wenn ich es herausnehme, erhalte ich in jedem Fall einen anderen MCSP, aber einen stabilen Wert. Jetzt beträgt er aktuell 74 76 76 76.
Wenn ich mich richtig erinnere, waren es auch 84. Ich weiß nicht, ob es an der hohen Frequenz oder am schlechten Kontakt liegt. Tatsächlich reagiert der LGA1700 zu empfindlich auf Druck. Schlimm, das hatte ich noch nie zuvor.
Nur eine Stunde lang getestet, gehts gut wieder.
Anhänge
wheeler II
Enthusiast
Hallo an die Experten hier,
ich benötige Eure Unterstützung.
im DDR4 Thread habe ich kein how to gefunden, habe aber 32GB DDR5
Mein Problem ist das mein Rechner einfriert, und ca. 30-40sec benötigt um Programme etc zu öffnen
Bootzeit ca. 4min bis alles oben ist
EDIT: hab das Bios auf Standard zurückgesetzt und erneut Xmp1 gewählt
Bootzeit ca. 1min, Rechner nach 1min 20 einsatzbereit
Da ich den Rechner kurz zuvor "stabil" hatte, habe ich von Xmp1 versuchsweise auf Xmp2 umgestellt, dann war es noch schlimmer mit den "freezern"
Dachte... ich kann problemlos auf xmp1 zurück, aber die freezer bleiben...
PC hatte zuvor 1min bootzeit und lief stabil sehr schnell.
(Ich hätte einfach nicht auf xmp2 stellen sollen...)
Ich denke es hängt daran das meine Ram nicht richtig laufen.
Kann mich dabei bitte jemand unterstützen?
Was muß ich im Bios für diese Speicher einstellen?
- ich glaube hier passt etwas nicht.
lt. Asus sollte der DDR5laufen
G.Skill Trident Z5 (2 x 16GB, 6400 MHz, DDR5-RAM, DIMM)
F5-6400J3239G16GX2-TZ5K
Netzteil: be quiet! STRAIGHT POWER 11 PC Netzteil ATX 1000W
Grafigkarte: Nvidia GeForce RTX 4060Ti
asus-rog-maximus-z690-hero
CPU: I7 14700K
Bios ist neu: 3302
CPU-Z
meldet 3200 MHz




Ich komme im Bios soweit klar, aber mit OC für RAM habe ich keine Erfahrung und brauche daher jemanden der mir hier mit einfachen Anweisungen hilft.
PC ist nicht auf Gaming ausgelegt, dient nur für Windows/NAS Filme/ kleine Vid. schneiden und ist ein upgrade nach 15 Jahren...
Werden noch weitere Infos zum PC benötigt?
Danke
Werner
ich benötige Eure Unterstützung.
im DDR4 Thread habe ich kein how to gefunden, habe aber 32GB DDR5
Mein Problem ist das mein Rechner einfriert, und ca. 30-40sec benötigt um Programme etc zu öffnen
Bootzeit ca. 4min bis alles oben ist
EDIT: hab das Bios auf Standard zurückgesetzt und erneut Xmp1 gewählt
Bootzeit ca. 1min, Rechner nach 1min 20 einsatzbereit
Da ich den Rechner kurz zuvor "stabil" hatte, habe ich von Xmp1 versuchsweise auf Xmp2 umgestellt, dann war es noch schlimmer mit den "freezern"
Dachte... ich kann problemlos auf xmp1 zurück, aber die freezer bleiben...
PC hatte zuvor 1min bootzeit und lief stabil sehr schnell.
(Ich hätte einfach nicht auf xmp2 stellen sollen...)
Ich denke es hängt daran das meine Ram nicht richtig laufen.
Kann mich dabei bitte jemand unterstützen?
Was muß ich im Bios für diese Speicher einstellen?
- ich glaube hier passt etwas nicht.
lt. Asus sollte der DDR5laufen
G.Skill Trident Z5 (2 x 16GB, 6400 MHz, DDR5-RAM, DIMM)
F5-6400J3239G16GX2-TZ5K
Netzteil: be quiet! STRAIGHT POWER 11 PC Netzteil ATX 1000W
Grafigkarte: Nvidia GeForce RTX 4060Ti
asus-rog-maximus-z690-hero
CPU: I7 14700K
Bios ist neu: 3302
CPU-Z
meldet 3200 MHz
Ich komme im Bios soweit klar, aber mit OC für RAM habe ich keine Erfahrung und brauche daher jemanden der mir hier mit einfachen Anweisungen hilft.
PC ist nicht auf Gaming ausgelegt, dient nur für Windows/NAS Filme/ kleine Vid. schneiden und ist ein upgrade nach 15 Jahren...
Werden noch weitere Infos zum PC benötigt?
Danke
Werner
Zuletzt bearbeitet:
AndreasP1981
Experte
- Mitglied seit
- 12.11.2015
- Beiträge
- 321
- Ort
- Bei Rastatt
- Details zu meinem Desktop
- Prozessor
- Ryzen 9800X3D
- Mainboard
- ASrock X870e Taichi Lite
- Kühler
- Arctic LF III 420
- Speicher
- G.Skill F6-6000J2636G32GX2-TZ5NR
- Grafikprozessor
- Gainward GeForce RTX™ 4090 Phantom "GS"
- Display
- LG Ultragear 32"
- SSD
- WD Black SN750SE / WD Black SN850 / Samsung 990 Pro / InnovationIT Y
- Gehäuse
- Deepcool Morpheus
- Netzteil
- FSP Hydro PTM X Pro 1200W
- Keyboard
- NZXT Function 2022
- Mouse
- Corsair Scimitar RGB Elite Wireless
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Chrome
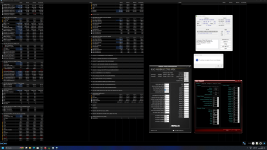
@Veii
moin... lange Nacht gehabt mit hunderten von Bluescreens und y-cruncher attemps...

bist du dir damit sicher?
Unzählige male die Wiederherstellungsoptionen heute Nacht gesehen...
Ich hab nicht eine Spannung Kombination gefunden die weder Bluescreen, Y-Cruncher Absturz/Fehler oder WHEA Fehler produziert...
Um 2:30 Uhr hab ich mich dann fürs Schlafen gehen entschieden...
moin... lange Nacht gehabt mit hunderten von Bluescreens und y-cruncher attemps...
SA möchtest du auf 1.12-1.175 bekommen. Höhere SA niedrigere VDDQ delta. (beginne mit 8000MT/s, selbe Timings)
bist du dir damit sicher?
Unzählige male die Wiederherstellungsoptionen heute Nacht gesehen...
Ich hab nicht eine Spannung Kombination gefunden die weder Bluescreen, Y-Cruncher Absturz/Fehler oder WHEA Fehler produziert...
Um 2:30 Uhr hab ich mich dann fürs Schlafen gehen entschieden...
Zuletzt bearbeitet:

- Mitglied seit
- 19.08.2003
- Beiträge
- 3.206
- Desktop System
- Lieselotte
- Details zu meinem Desktop
- Prozessor
- 16-Core AMD Ryzen 9 9950X3D
- Mainboard
- ASRock X870E Taichi Bios 3.20
- Kühler
- CPU Cooler Alphacool Core 1 ; Supernova 1260mm ; EKWB Coolstream Xe 360; NexXxoS ST20 HPE; VPP Apex
- Speicher
- G Skill F5-6400J3039G16GX2-TR5NS
- Grafikprozessor
- ASUS TUF RTX 4080 SUPER GAMING OC
- Display
- LG UltraGear 34GP950G-B
- SSD
- CT2000T700SSD3 2TB ; WD_BLACK SN850X 2TB ; CT2000BX500SSD1
- HDD
- WD Black SATA 8TB
- Gehäuse
- PHANTEKS Enthoo 719
- Netzteil
- be quiet! Dark Power Pro 12 1500W
- Keyboard
- Logitech G915
- Mouse
- Logitech G604; G502X ; Razer Naga V2
- Betriebssystem
- WIN 11 24H2
tras = tcl +trcd + trp (12 o. 15) + Sicherheit (12) = 110 ; trfcpb faktor meine ich sind 26 : 576/26 geht nicht auf - also 572 . Ich glaube unter 1,2 SA wird das nicht laufen -so oder so. Brauchen die Patriot echt über 1,5 für 200MHZ mehr als XMP , oder ist die XMP / 8000 Spannung nicht 1,35 wie bei meinen Gskills ?@Veii
moin... lange Nacht gehabt mit hunderten von Bluescreens und y-cruncher attemps...
Anhang anzeigen 985380
bist du dir damit sicher?
Unzählige male die Wiederherstellungsoptionen heute Nacht gesehen...
Ich hab nicht eine Spannung Kombination gefunden die weder Bluescreen, Y-Cruncher Absturz/Fehler oder WHEA Fehler produziert...
Um 2:30 Uhr hab ich mich dann fürs Schlafen gehen entschieden...
AndreasP1981
Experte
- Mitglied seit
- 12.11.2015
- Beiträge
- 321
- Ort
- Bei Rastatt
- Details zu meinem Desktop
- Prozessor
- Ryzen 9800X3D
- Mainboard
- ASrock X870e Taichi Lite
- Kühler
- Arctic LF III 420
- Speicher
- G.Skill F6-6000J2636G32GX2-TZ5NR
- Grafikprozessor
- Gainward GeForce RTX™ 4090 Phantom "GS"
- Display
- LG Ultragear 32"
- SSD
- WD Black SN750SE / WD Black SN850 / Samsung 990 Pro / InnovationIT Y
- Gehäuse
- Deepcool Morpheus
- Netzteil
- FSP Hydro PTM X Pro 1200W
- Keyboard
- NZXT Function 2022
- Mouse
- Corsair Scimitar RGB Elite Wireless
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Chrome
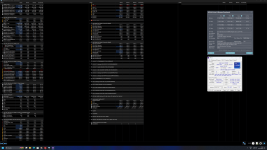
dachte irgendwo gelesen zu habend der trfcpb faktor sei 32...tras = tcl +trcd + trp (12 o. 15) + Sicherheit (12) = 110 ; trfcpb faktor meine ich sind 26 : 576/26 geht nicht auf - also 572 . Ich glaube unter 1,2 SA wird das nicht laufen -so oder so. Brauchen die Patriot echt über 1,5 für 200MHZ mehr als XMP , oder ist die XMP / 8000 Spannung nicht 1,35 wie bei meinen Gskills ?
das Gefühl hab ich mittlerweile auch das es unter 1,2 SA nicht läuft... aber ich warte mal Veii`s meinung ab.
das sind die Profile:
also ja, XMP Spannung ist höher.
- Mitglied seit
- 19.08.2003
- Beiträge
- 3.206
- Desktop System
- Lieselotte
- Details zu meinem Desktop
- Prozessor
- 16-Core AMD Ryzen 9 9950X3D
- Mainboard
- ASRock X870E Taichi Bios 3.20
- Kühler
- CPU Cooler Alphacool Core 1 ; Supernova 1260mm ; EKWB Coolstream Xe 360; NexXxoS ST20 HPE; VPP Apex
- Speicher
- G Skill F5-6400J3039G16GX2-TR5NS
- Grafikprozessor
- ASUS TUF RTX 4080 SUPER GAMING OC
- Display
- LG UltraGear 34GP950G-B
- SSD
- CT2000T700SSD3 2TB ; WD_BLACK SN850X 2TB ; CT2000BX500SSD1
- HDD
- WD Black SATA 8TB
- Gehäuse
- PHANTEKS Enthoo 719
- Netzteil
- be quiet! Dark Power Pro 12 1500W
- Keyboard
- Logitech G915
- Mouse
- Logitech G604; G502X ; Razer Naga V2
- Betriebssystem
- WIN 11 24H2
32 sind trfc2
AndreasP1981
Experte
- Mitglied seit
- 12.11.2015
- Beiträge
- 321
- Ort
- Bei Rastatt
- Details zu meinem Desktop
- Prozessor
- Ryzen 9800X3D
- Mainboard
- ASrock X870e Taichi Lite
- Kühler
- Arctic LF III 420
- Speicher
- G.Skill F6-6000J2636G32GX2-TZ5NR
- Grafikprozessor
- Gainward GeForce RTX™ 4090 Phantom "GS"
- Display
- LG Ultragear 32"
- SSD
- WD Black SN750SE / WD Black SN850 / Samsung 990 Pro / InnovationIT Y
- Gehäuse
- Deepcool Morpheus
- Netzteil
- FSP Hydro PTM X Pro 1200W
- Keyboard
- NZXT Function 2022
- Mouse
- Corsair Scimitar RGB Elite Wireless
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Chrome
dann hab ich die irgendwie zueinander geworfen... Danke32 sind trfc2
Beitrag automatisch zusammengeführt:
war tRAS nicht:tras = tcl +trcd + trp (12 o. 15) + Sicherheit (12) = 110
minimum tRAS = tRCD + tRTP
safe = tCWL + tRCD + tWR
Zuletzt bearbeitet:
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.480
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
Danke dass du auf mich hörst68 / 68 / 68 / 68 / 68 🫶
Bitte vergiss mich nicht sobald du berühmt wirst 🤭
Ja ne, ich sollte das Bild entfernenbist du dir damit sicher?
Die tWRRD ist falsch. Weitaus zu tief
tWR 2 RD delay ist
CWL + WTR_X + BC8 + 2
In ATC ausgelesen
CWL + WTR_X + BC4 + 2
RAS:
:
LUXX sheet.
RAS is a dynamic value, and you set the minimum starting point.
I like to start and stay at RCD+RTP+4 (pagesize focused) like anta taught. Looking on it as delay between actions instead on a single action - aka tRTP is rather used here.
SafeRAS is silly because that depends on the design. It works and works well, but RAS and RC are managed on Intels side slightly different.
Soo its mostly just a waste to run it here that way.
The only goal for RAS is , to be long enough to not cause ROW miss
And optimally not be short enough so that it messes with parallelization between active and "have to start" reads.
Its goal is to end when it has to end (longer than CAS with RCD happening ability), instead of force additional delay to be inserted,
and given its dynamicness might as well add delay there.
^ Because having one ROW open longer, to make sure things process while another one is targeted ~ is barely to any penalty.
Same goes for tRP.
It has to come after RAS finishes its work, and another bankgroup or even subchannel is targeted.
Soo its work goes in the background and it doesnt matter what value it is at. Its good to be exactly as long as RCD, soo there is no potential for drop/repeat.
tRP only starts to matter if RAS is too short and causes an issue. Then all things halt and tRP is inserted beforehand to fix wrong accessed ROWs.
Only then you notice a performance difference with it, as you caused an emergency halt.
tWR
LUXX Sheet
Aber tWR und tWTR_X , sind ein ungelöstes Problem
Undefiniert ebenso.
Nicht jeder Read ist ein Read+Precharge (RD vs RDA) und nicht jeder Write passiert einzeln in der Mitte von einem Read.
Manchmal ist der erste write innerhalb 4nCK (in der Mitte von dem BurstChop 8 delay)
Manchmal sind es 2 writes ohne read dazwischen. Dann ist der erste innerhalb 4nCK und der 2. muss abwarten bis BC8 fertig ist um sich dann zu starten 4+pauseX(4)+4)
Im controller ist die Formel 4+8. Der 2. write kann physikalisch nicht schneller als BC8/2 + BC8 , sein. Internes clock limit.
Es ist "kompliziert" wenn man 2 MC-Links hat zu beiden Subchannels des RAMs.
Sie bleiben nur 32bit und nicht 64bit weit. Aber da writes von der CPU Seite geschehen, wird hier getrickst.
Der eigentliche minimum tWR delay beträgt 48nCK.
Und tWR muss mindestens so lange sein wie WTR_AutoPre oder WTR_L (WR to WR same position roundtrip, no autoprecharge)
Es ist sehr sehr kompliziert, und im Grundegenommen ist dein Limit nur (Single sided DIMM = Wert 24-30, dual sided DIMM = Wert 48+)
Es kommt auf die CPU an wie sie die Writes ausführt, wann sie sie ausführt und wann (versteckt) tWR ausgeführt wird um nicht in den Reads reinzufallen.
Den WRites können immer ausgeführt werden.
Meine Empfehlung ?
RRDL 12, WTRL 24, WR 24
Es hat schon gleich oder über WTRL zu sein, und WTRA intern ist automatisiert.
Manchmal komme ich auf Wert 30 manchmal auf Wert 24. Soweit läuft Wert 24 gut genug, als dass man WTRS minimum 4 auf RRDS minimum 8 ~ nicht erhöhen muss.
Sollte man CPU seitige Write Probleme bekommen, dann muss WR, WTR und eventuell WRRD_X hoch
amd_man_bavarian
Experte
- Mitglied seit
- 23.09.2023
- Beiträge
- 740
- Ort
- BoB
- Details zu meinem Desktop
- Prozessor
- ! Intel Core Ultra 7 265Kf !
- Mainboard
- MSI MEG Z890 ACE
- Kühler
- Alpenföhn Brocken 4 Max + 2x Noctua NFA12x25 chromax black swap
- Speicher
- ADATA XPG Lance DDR5 9200 @ 8933 C40
- Grafikprozessor
- ASUS Tuf RTX 4070TI Super OC
- SSD
- Samsung 990Pro 1TB
- HDD
- --
- Opt. Laufwerk
- --
- Soundkarte
- Realtek ALC4080 + DAB
- Gehäuse
- Endorfy ARX 700 Air
- Netzteil
- BeQuiet Dark Power Pro 11 650W Platinum
- Betriebssystem
- Windows 11 Pro 24H2
- Webbrowser
- FireFox
- Internet
- ▼50MBit ▲10 MBit
Im Moment bekomme ich 7800 nicht so recht Stable aber zumindest 7600 und das mit CL34 , ist ja so schlecht auch nicht.
Karhu ist 45Minuten durchgelaufen, das langt mir erstmal an stabilität da ich keinen Sponsor habe der mir den Strom für ne 24 Stunden Session bezahlt
Das ganze wird am Wochenende noch in Anwendungen getestet , aber ich denk das kann so bleiben.
SA ist auf 1,095V , VDD 1,4V , VDDQ 1,34V , VDD CPU/MRC auf 1,35V , VDDQTX zwangsläufig auch, da es bei meinem Board nicht manuell gesetzt werden kann.

@wheeler II /Werner : Das Aktuelle Bios ist 3401 beim Z690 Maximus Hero .
Im Bios unter den Memory einstellungen ganz nach unten scrollen . Dort MRC Fastboot deaktivieren, MRC Full aktivieren für ein gescheites Training und stabilität.
Bei der sparte Xtreme tuning nach unten scrollen. da tauchen dann CPUspannungen usw. auf . Wenn du SA Voltage siehst und diese > 1,2Volt ist mal senken auf ~1,1V , Dann weiter nach unten scrollen auf Advanvced Memory Voltage Dort die Spannungen mal von 1,4V auf 1,35V setzen.
Das Ganze mit dem XMP mit Asus Optimierten Timings. Weiß aus dem Kopf gerade nicht mehr alle Bezeichnungen von Asus, drum hab ich es nach bestem Gewissen umschrieben ^^
Karhu ist 45Minuten durchgelaufen, das langt mir erstmal an stabilität da ich keinen Sponsor habe der mir den Strom für ne 24 Stunden Session bezahlt
Das ganze wird am Wochenende noch in Anwendungen getestet , aber ich denk das kann so bleiben.
SA ist auf 1,095V , VDD 1,4V , VDDQ 1,34V , VDD CPU/MRC auf 1,35V , VDDQTX zwangsläufig auch, da es bei meinem Board nicht manuell gesetzt werden kann.
@wheeler II /Werner : Das Aktuelle Bios ist 3401 beim Z690 Maximus Hero .
Im Bios unter den Memory einstellungen ganz nach unten scrollen . Dort MRC Fastboot deaktivieren, MRC Full aktivieren für ein gescheites Training und stabilität.
Bei der sparte Xtreme tuning nach unten scrollen. da tauchen dann CPUspannungen usw. auf . Wenn du SA Voltage siehst und diese > 1,2Volt ist mal senken auf ~1,1V , Dann weiter nach unten scrollen auf Advanvced Memory Voltage Dort die Spannungen mal von 1,4V auf 1,35V setzen.
Das Ganze mit dem XMP mit Asus Optimierten Timings. Weiß aus dem Kopf gerade nicht mehr alle Bezeichnungen von Asus, drum hab ich es nach bestem Gewissen umschrieben ^^
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.480
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
DDR5 Layout & Buswidth + Minimum "single active" ROW on 1Cell1Transistor design ~ within same Bank.dachte irgendwo gelesen zu habend der trfcpb faktor sei 32...
// credits , help assisted by Micron. Not my illustrations.
16 Collums each , at the same time within BurstLength 16 ~ on 31+X wide Bus.
Minimum could be steps of 16, but per bank refresh doesnt work as fine granular.
Steps of 32 is fine to not conflict and result in 2048 potential attempts of refresh.
Well, the story is longer, but this would explode this thread
On those 16 selected columns per active ROW,
They get decoded by SenseAmp , and then transferred over
Or its slightly different in how they reached higher density.
I keep using 32 for both so far.
In both cases it makes sense (as 24 or 32, in such case rather 16) but i need time to research how density was reached without VIA's.
Should be simple to figure out, because design data is for 2GB ICs.
Zuletzt bearbeitet:
AndreasP1981
Experte
- Mitglied seit
- 12.11.2015
- Beiträge
- 321
- Ort
- Bei Rastatt
- Details zu meinem Desktop
- Prozessor
- Ryzen 9800X3D
- Mainboard
- ASrock X870e Taichi Lite
- Kühler
- Arctic LF III 420
- Speicher
- G.Skill F6-6000J2636G32GX2-TZ5NR
- Grafikprozessor
- Gainward GeForce RTX™ 4090 Phantom "GS"
- Display
- LG Ultragear 32"
- SSD
- WD Black SN750SE / WD Black SN850 / Samsung 990 Pro / InnovationIT Y
- Gehäuse
- Deepcool Morpheus
- Netzteil
- FSP Hydro PTM X Pro 1200W
- Keyboard
- NZXT Function 2022
- Mouse
- Corsair Scimitar RGB Elite Wireless
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Chrome
Bei dem Wissen das du hier einbringst ist es schwer dies nicht zu tun! 🫶Danke dass du auf mich hörst
Den Ansporn hab ich nicht mehr in meinem AlterBitte vergiss mich nicht sobald du berühmt wirst 🤭
möchte nur das die Kiste gut läuft zum Zocken und hier und da mal bissl Benchen.
now i remember where i read it 😜I keep using 32 for both so far.
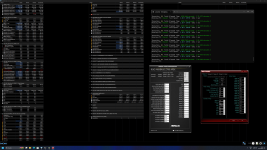
jetzt objektiv betrachtet:

tRAS = tcl + trp = 60
tRFC2 Faktor 32 = 21*32 = 672
tRFCpb Faktor 32 = 18*32 = 576
RTL`s R2-R7 = 0
tRDRD _dr _dd = 0
tRDWR _dr _dd = 0
tWRRD _dr _dd = 0
tWRWR _dr _dd = 0
VDDMEM 1,49
VDDQMEM 1,43
VDDQTX 1,30
IMC 1,39375 (0,00625 Steps Danke Dafür
 )
)sollte soweit richtig sein und für ein 48er kit nicht so schlecht?
Knackpunkt, ich komm nicht unter 1,25 VCCSA
Gestartet bevor ich Schlafen ging heute Nacht:

und heute Morgen den Screenshot gemacht...
wenn das ok ist bleibt das jetzt erstmal so vorab, das Game Y-Cruncher hat einen verdammt hohen Frust Faktor.
Beitrag automatisch zusammengeführt:
besser bekomm ich wohl nicht hin, entweder CPU / RAM / Mainboard / Benutzer irgendwo innerhalb der Variablen liegt wohl der Fehler
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.480
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
RCD+RTP , +4tRAS = tcl + trp = 60
Besser etwas mehr als manchmal etwas zu wenig.
Es stört kaum.
CAS und RAS sind getrennt. Am Schluss wartet man auf RAS bzw bis der Read command die aktive ROW schließt, wenn es nicht RAS macht
(RAS aus ROW offline / aber auch Read with AutoPrecharge = active row off)
RAS geht über CAS oder RCD, weswegen man den Command länger aktiv haben möchte.
Es ist normal das Commands überlappen. Es ist aber wichtig wann sie enden. Mehr ist manchmal besser.
EDIT:
Als Beispiel wenn RAS zu tief ist, außer dass es gerne mal ROWs misst.
Wird nur auf einem RDA anstelle RD command gewartet, was langsam ist. Den RAS stoppt früh, Row ist noch aktiv, RAS stop wird ignoriert und auf ein AP command gewartet.
Den ein AutoPrecharge nach jedem Read dauert, anstelle nur ein (p)recharge von der Bank wenn sie unbenutzt wird.
Beides richtig und beides stabil, aber eigentlich langsam und innefizient.
RTL`s R2-R7 = 0
Diese sind wichtig.
Welche auch immer die 25er bei dem Boardlayout sind, die können weg.
Die APEX sind bekannt, die anderen Boards vertauschen gerne mal die channels.
hahawenn das ok ist bleibt das jetzt erstmal so vorab, das Game Y-Cruncher hat einen verdammt hohen Frust Faktor.
Bestimmte SA erwarten bestimmte Spannungen. Und es hat ein CVDD2 limit.Knackpunkt, ich komm nicht unter 1,25 VCCSA
Wenn dir mal wieder danach ist
Kannst du gerne mit dem VDDQ Training auf AUS
Rausloten wie tief du mit CVDDQ gehen kannst.
130mV delta ist nicht besonders viel. Erwartet, aber nicht besonders viel.
Das selbe mit "wie hoch" kannst du gehen bis du ein limit erreichts.
Das kann runter
Momentan ist es 20 & 10 (ATC ließt es falsch, eig richtig aber dennoch falsch)
WTR_L ist selten, etwas delay hier stört nicht
WTR_S geschieht immer. Runter auf 4. Wenn es nicht geht runter auf RRDS-1.
4 geht allerdings bei Intel recht einfach, wenn deine Timings ok sind.
CPU & Arch & Biosdesign Thema.
Die zwei können auch auf 21 runter.
CCDL (read 2 read roundtrip) & RD to WR Delay ~ sind nicht besonders anders.
RDWR auf 21 bis 8400MT/s. Geht auch tiefer, aber kann WTR & WR Probleme bereiten.
tPPD auf 2 anstelle stock auf 4.
Zuletzt bearbeitet:
AndreasP1981
Experte
- Mitglied seit
- 12.11.2015
- Beiträge
- 321
- Ort
- Bei Rastatt
- Details zu meinem Desktop
- Prozessor
- Ryzen 9800X3D
- Mainboard
- ASrock X870e Taichi Lite
- Kühler
- Arctic LF III 420
- Speicher
- G.Skill F6-6000J2636G32GX2-TZ5NR
- Grafikprozessor
- Gainward GeForce RTX™ 4090 Phantom "GS"
- Display
- LG Ultragear 32"
- SSD
- WD Black SN750SE / WD Black SN850 / Samsung 990 Pro / InnovationIT Y
- Gehäuse
- Deepcool Morpheus
- Netzteil
- FSP Hydro PTM X Pro 1200W
- Keyboard
- NZXT Function 2022
- Mouse
- Corsair Scimitar RGB Elite Wireless
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Chrome
alle 25er? denn R1 steht auch auf 25 im BIOS
Diese sind wichtig.
Welche auch immer die 25er bei dem Boardlayout sind, die können weg.
Die APEX sind bekannt, die anderen Boards vertauschen gerne mal die channels.
Ok werd ich mal testen. better safe then sorry also.RCD+RTP , +4
Besser etwas mehr als manchmal etwas zu wenig.
Es stört kaum.
CAS und RAS sind getrennt. Am Schluss wartet man auf RAS bzw bis der Read command die aktive ROW schließt, wenn es nicht RAS macht
(raus aus ROW offline / aber auch Read with AutoPrecharge = active row off)


RAS geht über CAS oder RCD, weswegen man den Command länger aktiv haben möchte.
Es ist normal das Commands überlappen. Es ist aber wichtig wann sie enden. Mehr ist manchmal besser.
tWTR L 24 ATC sollte dann 28 zeigen denke ich
Das kann runter
Momentan ist es 20 & 10 (ATC ließt es falsch, eig richtig aber dennoch falsch)
WTR_L ist selten, etwas delay hier stört nicht
WTR_S geschieht immer. Runter auf 4. Wenn es nicht geht runter auf RRDS-1.
4 geht allerdings bei Intel recht einfach, wenn deine Timings ok sind.
CPU & Arch & Biosdesign Thema.

Die zwei können auch auf 21 runter.

CCDL (read 2 read roundtrip) & RD to WR Delay ~ sind nicht besonders anders.
RDWR auf 21 bis 8400MT/s. Geht auch tiefer, aber kann WTR & WR Probleme bereiten.
tPPD auf 2 anstelle stock auf 4.
tWTR S 4 werd ich versuchen wenn nicht dann 7 tRRDS -1
soweit richtig?
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.480
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
soweit richtig?
Beides geht,alle 25er? denn R1 steht auch auf 25 im BIOS
wenn du einen "single channel" anstelle quad channel bug hinbekommst
Dann sollte R1 & R3 noch aktiv
Aber wenn R3 aus ist vom 2nd slot, sollte auch R1 aus sein
Je nach Board ist das Layout anders
Müsste bei dir R0 & R2 sein ?
Das 2 mal pro MemoryController Link.
AndreasP1981
Experte
- Mitglied seit
- 12.11.2015
- Beiträge
- 321
- Ort
- Bei Rastatt
- Details zu meinem Desktop
- Prozessor
- Ryzen 9800X3D
- Mainboard
- ASrock X870e Taichi Lite
- Kühler
- Arctic LF III 420
- Speicher
- G.Skill F6-6000J2636G32GX2-TZ5NR
- Grafikprozessor
- Gainward GeForce RTX™ 4090 Phantom "GS"
- Display
- LG Ultragear 32"
- SSD
- WD Black SN750SE / WD Black SN850 / Samsung 990 Pro / InnovationIT Y
- Gehäuse
- Deepcool Morpheus
- Netzteil
- FSP Hydro PTM X Pro 1200W
- Keyboard
- NZXT Function 2022
- Mouse
- Corsair Scimitar RGB Elite Wireless
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Chrome
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.480
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
AndreasP1981
Experte
- Mitglied seit
- 12.11.2015
- Beiträge
- 321
- Ort
- Bei Rastatt
- Details zu meinem Desktop
- Prozessor
- Ryzen 9800X3D
- Mainboard
- ASrock X870e Taichi Lite
- Kühler
- Arctic LF III 420
- Speicher
- G.Skill F6-6000J2636G32GX2-TZ5NR
- Grafikprozessor
- Gainward GeForce RTX™ 4090 Phantom "GS"
- Display
- LG Ultragear 32"
- SSD
- WD Black SN750SE / WD Black SN850 / Samsung 990 Pro / InnovationIT Y
- Gehäuse
- Deepcool Morpheus
- Netzteil
- FSP Hydro PTM X Pro 1200W
- Keyboard
- NZXT Function 2022
- Mouse
- Corsair Scimitar RGB Elite Wireless
- Betriebssystem
- Windows 11 Pro
- Webbrowser
- Chrome
das erste mal das ich dir nicht rechtgeben kann und mag! Das bisschen wissen über DDR5 das ich hab ist zu 99,99% vom hier mitlesen und die Unterstützung deinerseits.I did nothing.
Also nimm das Kompliment gefälligst an
Erstmal ist Ostern, bissl Zocken und, wie hieß dan nochmal... ...achso Reallife, Familie Freunde und so...8200 when™ ?
TM5& karhu test it
Wahrscheinlich wenn ab Sonntag oder halt dann im laufe der Zeit.
Will ja die CPU auch mal ausloten. Nicht nur schnell was einstellen um was zu Probieren.
Muss mich mal in den ganzen TVB kram einlesen.
Der KF war da mehr auf der Kooperativen Seite, beim KS bin ich mir noch nicht sicher...
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.480
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
SA auf 1.2Mein Problem ist das mein Rechner einfriert,
Bei 1.25 (stock) kann es vorkommmen dass es freezed.
Veii
Enthusiast
- Mitglied seit
- 31.05.2018
- Beiträge
- 1.480
- Desktop System
- QA Platform
- Laptop
- ASUS 13" ZenBook OLED [5600U]
- Details zu meinem Desktop
- Prozessor
- Intel Core Ultra 9 285K
- Mainboard
- ASRock OC Formula
- Kühler
- Alphacool T38 280mm
- Speicher
- G.Skill Z5 CK 9600
- Grafikprozessor
- GTX1080ti KP [XOC ROM] // EVGA GTX 650 1GB [UEFI GOP]
- Display
- KOORUI GN10 miniLED
- SSD
- Samsung EVO 850
- Soundkarte
- ESI Ambier i1 & AKG P820
- Gehäuse
- Open-Bench
- Netzteil
- Corsair SF85 // Seasonic GX-550
- Keyboard
- Topre Realforce 108UBK 30g [Silenced]
- Mouse
- Endgame-Gear OP1 8K
- Betriebssystem
- Win11
- Internet
- ▼42 MBit ▲15 MBit
Zum Memtimings test gehört ein CPU test~Karhu ist 45Minuten durchgelaufen, das langt mir erstmal an stabilität da ich keinen Sponsor habe der mir den Strom für ne 24 Stunden Session bezahlt
Wenn nicht 60-90min, dann wenigstens 30min.
amd_man_bavarian
Experte
- Mitglied seit
- 23.09.2023
- Beiträge
- 740
- Ort
- BoB
- Details zu meinem Desktop
- Prozessor
- ! Intel Core Ultra 7 265Kf !
- Mainboard
- MSI MEG Z890 ACE
- Kühler
- Alpenföhn Brocken 4 Max + 2x Noctua NFA12x25 chromax black swap
- Speicher
- ADATA XPG Lance DDR5 9200 @ 8933 C40
- Grafikprozessor
- ASUS Tuf RTX 4070TI Super OC
- SSD
- Samsung 990Pro 1TB
- HDD
- --
- Opt. Laufwerk
- --
- Soundkarte
- Realtek ALC4080 + DAB
- Gehäuse
- Endorfy ARX 700 Air
- Netzteil
- BeQuiet Dark Power Pro 11 650W Platinum
- Betriebssystem
- Windows 11 Pro 24H2
- Webbrowser
- FireFox
- Internet
- ▼50MBit ▲10 MBit
Das ist mir bewußt. Die Aussage von mir bezog sich rein auf die Ramstabilitätsseite. Ich habe Außer Karhu auch TM5 Extreme1 @anta777 eine Stunde laufen lassen, den Aida stabilitätstest eine Stunde , Cinebench R23 Throttlingtest 30 minuten ,. Damit es mir nicht langweilig wird hab ich ein Paar mal den Corona Benchmark laufen lassen und UL CPU Benchmark. Dann als Abschluß Gaming im CPU Limit und im GPU Limit. Letzteres hab ich mir angewöhnt da ich mehrfach hatte das alle stabilitätstest gesagt haben "läuft" und einige Games haben sich dennoch mit freezer verabschiedet.Zum Memtimings test gehört ein CPU test~
Wenn nicht 60-90min, dann wenigstens 30min.
Zwischendrin habe ich geschaut ob Coldboot bugs auftreten , habe bei neustarts das warmboottraining aktiviert um zu sehen ob es hierbei Probleme gibt. Ich denke das langt für nicht ganz zwei Tage an tests. Und bisher hate ich ... toitoi ... keine Probleme. Scheint eine CPU zu sein deren Controller nicht so nervös ist. Ich konnte auch 7800 und 8000 Booten, aber leide nur benchstable, was mir nicht langt.