

Werbung
Erinnern wir uns kurz an "Ivy Bridge" zurück: Im Vergleich zu "Sandy Bridge" hatte "Ivy Bridge" keine großartigen Veränderungen an der CPU-Architektur, denn "Ivy Bridge" war hauptsächlich ein "Tick" - es wurde eine neue Fertigungstechnologie eingeführt. Trotzdem waren 400 Millionen mehr 22-nm-Tri-Gate-Transistoren auf der CPU vorhanden, weshalb Intel gerne von einem "Tick+" gesprochen hatte. Doch diese hinzugefügten Transistoren gehörten alle zur Grafikeinheit von "Ivy Bridge". An der Struktur der CPU, am Aufbau, dem Memory-Controller und anderen Bereichen hat Intel nur Detailverbesserungen durchgeführt.
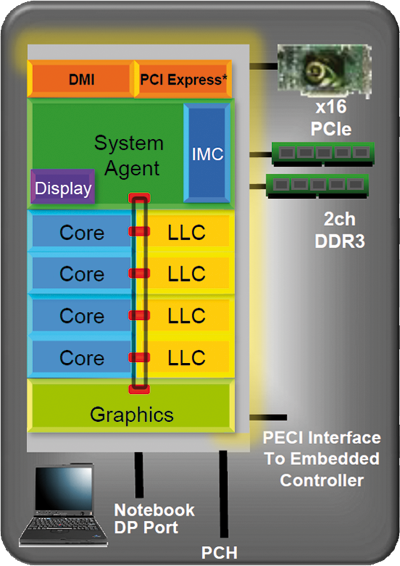
Wenn man die Architektur von "Haswell" bzw. "Haswell-E" nun betrachtet, kann man sich im Vergleich somit eigentlich auf "Sandy Bridge" beziehen. Erstmals gab Intel auf dem Intel Developer Forum (IDF) im September 2012 in San Francisco Einblicke in die "Haswell"-Architektur. Im Endeffekt hat Intel aber den groben Aufbau von "Sandy Bridge" beibehalten:
Leistung für die integrierte Grafik mitzubringen. Bei "Ivy Bridge" ist er in
unveränderter Art ebenso vorhanden, ähnlich sieht es bei "Haswell" und "Haswell-E" aus.
Veränderungen an den Kernen
Die neuen "Haswell-E"-Prozessoren bauen auf der altbekannten "Haswell"-Architektur auf und sind damit im Großen und Ganzen mit den kleineren Modellen zu vergleichen. Große Änderungen hat es mit Ausnahme des Speichercontrollers sowie des Cache- und Kernausbaus nicht gegeben.
Im September 2012 gab Intel erstmals einen Einblick in die "Haswell"-Architektur. Erstaunlicherweise berichtete man dort von einer Erhöhung der Single-Thread-Performance. Um dies zu erreichen, hat man einige Verbesserungen in die Kerne von "Haswell" integriert: Wie bei jedem Intel-Prozessor wurde wieder an der Branch-Prediction-Einheit gefeilt, das Front-End des Prozessors wurde massiv verbessert und die Puffer vergrößert, während gleichzeitig deren Latenz verbessert wurde. Hinzu kommt eine größere Bandbreite bei den Caches, deren Größe aber zumindest im L1- und L2-Bereich unverändert bleibt.
Intel erreicht durch eine Erhöhung der Buffer-Sizes eine bessere Parallelisierung von Workloads. "Haswell" und "Haswell-E" haben im Vergleich zu ihrer jeweiligen Vorgänger-Architektur in allen Bereichen (Out-of-Order Window, In-Flight Loads, In-Flight Stores, Scheduler Entries, Integer Register Files, FP Register Files und Allocation Queues) eine größere Buffer-Size. Dabei hat Intel aber aufgrund der Effizienz darauf geachtet, die Buffer auf einem aufeinander abgestimmten Niveau zu halten und nicht zu sehr aufzublasen - denn ungenutzte Buffer verbrauchen nur Strom, bringen aber keinen Geschwindigkeitsvorteil mehr.
Konkret hat Intel zwei Fused-Multiply-Add-Einheiten für AVX hinzugefügt, zwei zusätzliche Ports mit einer vierten Integer-ALU, eine zweite Sprungeinheit und eine Store-Adress-Einheit. Die Pipeline hat Intel beibehalten und sie nicht verlängert. Mit einigen Veränderungen entspricht sie also noch dem Vorgänger "Sandy Bridge" (und in der Basis sogar noch dem Pentium Pro). Die Größe des Out-of-Order-Window steigt auf 192 Einträge, "Sandy Bridge" besaß 168 Einträge. Gleichzeitig hat man die Reservation Station von 54 auf 60 Einträge aufgebohrt. Die Execution-Unit 7 entlastet die beiden Load/Store-Ports 2 und 3 durch eine dedizierte Store-Address-Einheit. Intel hat auch die physischen Register vergrößert, jetzt stehen 168 Einträge für das Floating-Point-Gleitkommaregister statt vorher 144 Einträge zur Verfügung, auch die Integer-Register wurden mit 168 Einträgen leicht erweitert (160). Als wichtige Veränderung hat Intel zudem die Größe des Unified-Translation-Lookaside-Buffers (L2 Unified TLB) auf eine Größe von 4K + 2M shared mit 1.024 Einträgen statt 512 Einträgen bei "Sandy Bridge" aufgebohrt. Wichtig war Intel die Beibehaltung der Länge der Pipeline und niedrige Latenzzeiten zu den Caches.
{jphoto image=28486}
Neue Befehlssätze: Advanced Vector Extensions 2
Ein weiteres neues Kernfeature für "Haswell" und "Haswell-E" sind Advanced Vector Extensions 2 (kurz Intel AVX2). Diese Befehlssatzerweiterung besitzt unter anderem jetzt 256-bit Integer Vectors, zudem wird Fused Multiply-Add (zwei Einheiten für AVX) unterstützt. Intel schafft es damit die Flops pro Taktzyklus zu verdoppeln. Als Resultat erhält man bei Anwendungen, die AVX2 nutzen, eine deutlich höhere Performance. Die Integer Instructions behandeln hauptsächlich den Bereich Indexing und Hashing, Kryptografie und Endian Conversion (MOVBE). Durch Fused Multiply-Add wird zudem das Rechenergebnis genauer, da bei einer getrennten Operation zwei Rundungsvorgänge vorhanden sind, bei der Abwicklung mit FMA jedoch nur einer enthalten ist.
Cache-Bandbreite und sonstige Verbesserungen
Spannend sind die Verbesserungen bei der Cache-Bandbreite. Während die Größe für den L1-Instruction- und Data-Cache weiterhin bei 32K und einer 8-fach assoziativen Anbindung geblieben sind, hat Intel die Load- und Store-Bandbreite im Vergleich zu Sandy Bridge von 32 Bytes pro Cycle auf 64 Bytes pro Cycle für Load und von 16 Bytes/Cycle auf 32 Bytes/Cycle für Store aufgebohrt. Der L2-Cache bleibt ebenso bei 256K und 8-Fach assoziativer Anbindung, auch hier bohrt man die Bandbreite zum L1-Cache auf 64 Bytes/Cycle auf.
Auch den System-Agent und den Last-Level-Cache hat Intel überarbeitet. Man bietet unter anderem mehr Bandbreite für den Shared-Last-Level-Cache durch neue, dedizierte Pipelines, die Data und Non-Data-Zugriffe parallel behandeln können. Für den System-Agent gibt es einen neuen Load-Balancer, der die Ressourcen effektiver verteilen kann. Zudem wird auch der DRAM Write Throughput durch bessere Queues und einen besseren Scheduler beschleunigt. Letztendlich hat Intel die Geschwindigkeit für Roundtrips bei Virtualisierung in VT-x noch einmal deutlich beschleunigt, hier liegt man jetzt unter 500 Zyklen pro Roundtrip.
Intel Transactional Synchronization Extension (TSX) mit Lock Elision
Damit Multi-Core-Prozessoren immer mit validen Daten arbeiten, gibt es sogenannte Locks. Greifen mehrere Threads auf den Speicher zu, wird der entsprechende Bereich zunächst gesperrt (Lock), um eine Veränderung während der Verarbeitung zu verhindern. Mit diesem Prinzip rechnet jeder Kern für sich ein valides Ergebnis aus, da die Daten immer aktuell sind. Im Normalfall sind diese zeitaufwändigen Locks allerdings überflüssig, da nur sehr selten mehrere Threads bei Speicherzugriffen auf denselben Bereich konkurrieren. Hierfür gibt es mit Haswell nun TSX und Transactional Memory: Ein Speicherzugriff kann auch ohne Lock geschehen, somit können schneller Daten zur Bearbeitung in den L1-Cache geladen werden. Allerdings muss es hardwareseitig einen Mechanismus geben, der konkurrierende Zugriffe erkennt und dann die Berechnung abbricht.
"Haswell" und "Haswell-E" haben zwei derartige Mechanismen. Hardware Locked Elision arbeitet nach dem obigen Prinzip und berechnet bei einem Konflikt denselben Code noch einmal unter Berücksichtigung der Locks. Restricted Transactional Memory hingegen meldet einen Abbruch erst einmal an die Software, die dann durch einen vorgesehenen Codepfad selber entscheiden kann, ob er mit Locks arbeiten möchte oder die Transaktion später wiederholen möchte. Beide Mechanismen arbeiten im L1-Daten-Cache der CPUs, "Haswell" kann aber auch Teilbereiche in die L2-Caches swappen.
Optimierungen am Stromverbrauch
Beim Stromverbrauch geht Intel den Weg weiter, möglichst alles abzuschalten, was nicht gerade benötigt wird. Interessant ist, dass Intel die Kerne vom LLC+Ring nun trennt und jeweils eine separate Frequency Domain anbietet. Dadurch soll eine genauere Steuerung der Taktraten möglich sein. Die Power Control Unit steuert dabei dynamisch das vorhandene TDP- oder Strom-Budget, wenn man ein Limit angibt.
Neuer Stromsparmodus "S0ix Active Idle"
Intel hat "Haswell" und "Haswell-E" neue Power- und Idle-States verpasst. Zum einen hat man neue Funktionen im Power-State im C7-Modus untergebracht. Hier werden alle Takte gestoppt, die Spannung wird vom Hauptteil der CPU genommen - selbst, wenn das Display noch aktiv ist. Die aktuellen Ultrabooks bieten sogar Self-Panel-Refresh (SPR), also kann kein Display-Bild bestehen bleiben, während das Ultrabook sich in C7 befindet. Die Zeitspanne zum Aufwecken aus dem C7-Modus und zum Schalten in andere C-Modi hat Intel dabei um 25 Prozent beschleunigt.
Durch neue Idle-States - S0ix Active Idle - und eine neue C-State-Intelligenz möchte man den Stromverbrauch weiter senken - und schafft dies gegenüber "Ivy Bridge" auch massiv im Idle-Power-Bereich. Bei S0ix Active Idle wird der Energieverbrauch des Rechners auf S3/S4-Niveau abgesenkt, aber es gibt keine lange Aufwachzeit. Intel realisiert dies vollautomatisch in der Hardware in feinen Abstufungen. Durch die generelle Beschleunigung zwischen den C-States um 25 Prozent und neue Power-Management-Funktionen für die Peripherie sind deutlich schnellere Wechsel innerhalb der C-States möglich.

System Agent (ehem. Uncore-Bereich)
Der System-Agent-Bereich der CPU hat zwar einige Optimierungen bezüglich der Stromspartechniken erhalten, ansonsten bleibt er aber größtenteils unverändert, mit Ausnahme des Memory-Controllers:
Memory-Controller
Eine der größten Änderungen von "Haswell-E" ist im Speichercontroller zu finden. Kam die ältere "Ivy Bridge-E"-Generation noch mit 1.866 MHz schnellen DDR3-Speichermodulen zurecht, arbeiten die neuen Modelle nun mit DDR4-Speicher zusammen. Ab Werk werden Module mit einer Geschwindigkeit von 2.133 MHz unterstützt. Mithilfe weiterer Teiler können aber auch noch schnellere Module verwendet werden. Derzeit gibt es Kits mit einer Geschwindigkeit von bis zu 3.200 MHz.
Keine Änderungen gibt es bei den Kanälen. Auch die neuen Modelle arbeiten im Quad-Channel-Betrieb und ermöglichen damit im Gegensatz zu "Haswell" oder "Haswell Refresh" deutlich höhere Speicherbandbreiten und RAM-Bestückungen. Bis zu 64 GB Arbeitsspeicher werden in den acht Speicherbänken zahlreichen X99-Mainboards unterstützt. Damit gibt es zumindest bei der maximalen Speicherkapazität keine weitere Aufstockung im Vergleich zu "Ivy Bridge-E". Zahlreiche Mainboard-Hersteller wie ASRock oder EVGA geben aber auch an, dass ihre Boards mit bis zu 128 GB Arbeitsspeicher bestückt werden können. Neu ist auch die Unterstützung des XMP-Profils in Version 2.0. Die beiden Vorgänger-Generationen unterstützen hier lediglich Version 1.3.
PCI-Express-Interface
Im Vergleich zum direkten Vorgänger hat sich nichts getan. "Haswell-E" und "Ivy Bridge" unterstützen schon beide PCI Express 3.0 - und da dieser Standard momentan immer noch State-of-the-Art ist, bleibt es bei 8 GT/s pro PCIe-Lane, also 984 MB/s. Mit einer theoretischen Bandbreite von 16 GB/s bei PCIe-3.0-x16 pro Richtung kommt man somit auf 32 GB/s Bandbreite insgesamt.
Direct Media Interface
An der Anbindung zwischen CPU und dem (X99-)Chipsatz hat Intel keine Veränderungen durchgeführt. Hier kommt die bekannte DMI 2.0 x4-Verbindung zum Einsatz. Der Platform-Controller-Hub wird also mit 5 GT/s angebunden, wobei diese Technik insgesamt auf 4 GB/s Übertragungsrate kommt. Dass Intel hier keine schnellere Anbindung gewählt hat, ist etwas verwirrend, denn in den letzten Jahren war ein Argument gegen eine größere Anzahl USB-3.0- und SATA-6G-Ports die Anbindung zum Prozessor: Man wolle den DMI-Bus nicht zum Flaschenhals werden lassen. Mit den neuen Chipsätzen hat Intel nun reichlich USB-3.0- und SATA-6G-Ports, trotzdem geht man wohl davon aus, dass die 4 GB/s Übertragungsrate zum Prozessor kein Problem darstellen.
