
MLPerf
-
MLPerf Inference 5.0: Neue Daten zu B200, TPU v6e sowie Granite Rapids und GB200 & MI325X erstmals dabei
 Die MLCommons hat heute die nächste Runde für das Inferencing-Benchmarking und damit einige interessante Datenpunkt für die Leistung der aktuellen KI-Beschleuniger veröffentlicht. Als unabhängige Organisation kann die MLCommons in Zusammenarbeit mit den Herstellern belastbarere Daten liefern, als dies die Hersteller selbst meist tun. In der letzten Runde, MLPerf Inference 4.1, waren die ersten Preview-Ergebnisse zum B200-Beschleuniger von... [mehr]
Die MLCommons hat heute die nächste Runde für das Inferencing-Benchmarking und damit einige interessante Datenpunkt für die Leistung der aktuellen KI-Beschleuniger veröffentlicht. Als unabhängige Organisation kann die MLCommons in Zusammenarbeit mit den Herstellern belastbarere Daten liefern, als dies die Hersteller selbst meist tun. In der letzten Runde, MLPerf Inference 4.1, waren die ersten Preview-Ergebnisse zum B200-Beschleuniger von... [mehr] -
MLPerf Training 4.1: Erstauftritt von NVIDIAs B200 und Googles Trillium im KI-Training
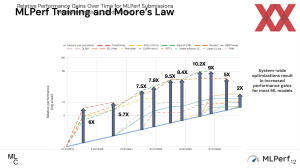 Die MLCommons hat heute die Trainings-Ergebnisse in der aktuellsten Version vorgestellt und diese beinhalten erstmals auch NVIDIAs B200-Beschleungier sowie den Google TPUv6p Trillium. Mit den Inference-4.1-Ergebnissen feierten sowohl der B200 wie auch der TPUv6e ihre Prämiere. An das Inferencing werden aber andere Herausforderungen gestellt, als dies beim Training der Fall ist. Die Blackwell-GPU wurde von NVIDIA zunächst auch primäre mit dem... [mehr]
Die MLCommons hat heute die Trainings-Ergebnisse in der aktuellsten Version vorgestellt und diese beinhalten erstmals auch NVIDIAs B200-Beschleungier sowie den Google TPUv6p Trillium. Mit den Inference-4.1-Ergebnissen feierten sowohl der B200 wie auch der TPUv6e ihre Prämiere. An das Inferencing werden aber andere Herausforderungen gestellt, als dies beim Training der Fall ist. Die Blackwell-GPU wurde von NVIDIA zunächst auch primäre mit dem... [mehr] -
MLPerf Inference 4.1: Erste Benchmarks zu Granite Rapids, B200, TPU v6e, Instinct MI300X und Turin
 Die MLCommons hat eine neue Runde an Benchmarks aus dem Inferencing-Bereich veröffentlicht. Die MLCommons sieht sich als unabhängige Organisation, die einen besseren Vergleich von Datacenter-Hardware ermöglichen will. Die Testbedingungen werden vorgegeben und mit den notwendigen Schranken versehen. Die Teilnehmer testen auf Basis dieser Vorgaben, allerdings können alle weiteren Teilnehmer diese Ergebnisse in einer Review-Phase verifizieren, so... [mehr]
Die MLCommons hat eine neue Runde an Benchmarks aus dem Inferencing-Bereich veröffentlicht. Die MLCommons sieht sich als unabhängige Organisation, die einen besseren Vergleich von Datacenter-Hardware ermöglichen will. Die Testbedingungen werden vorgegeben und mit den notwendigen Schranken versehen. Die Teilnehmer testen auf Basis dieser Vorgaben, allerdings können alle weiteren Teilnehmer diese Ergebnisse in einer Review-Phase verifizieren, so... [mehr] -
MLPerf Training v4.0: H200 und TPUv5p im Benchmark und Messung der Leistungsaufnahme
 Die aktuellste Runde der MLPerf-Ergebnisse gibt Einblicke in die Leistung moderner Datacenter-Hardware im Hinblick auf die Trainings-Leistung. Häufig sind wir hier von den Daten abhängig, die uns AMD, NVIDIA, Intel und andere präsentieren. Eine Verifikation dieser Leistungswerte durch Dritte ist aber nur schwer möglich. Bereits zum Start sei allerdings gesagt, dass AMD auch an dieser Runde nicht offiziell teilgenommen hat und somit die... [mehr]
Die aktuellste Runde der MLPerf-Ergebnisse gibt Einblicke in die Leistung moderner Datacenter-Hardware im Hinblick auf die Trainings-Leistung. Häufig sind wir hier von den Daten abhängig, die uns AMD, NVIDIA, Intel und andere präsentieren. Eine Verifikation dieser Leistungswerte durch Dritte ist aber nur schwer möglich. Bereits zum Start sei allerdings gesagt, dass AMD auch an dieser Runde nicht offiziell teilgenommen hat und somit die... [mehr] -
MLPerf Inference 4.0: Das Debüt der H200 von NVIDIA gelingt
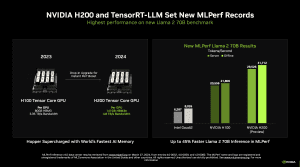 Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr]
Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr] -
MLPerf-Benchmarks: NVIDIA mit über 10.000 GPUs, Google TPU-v5e und Gaudi2 mit guten Ergebnissen
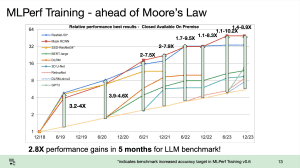 Die MLCommons hat eine weitere Runde Ergebnisse im Bereich Datacenter-Training und HPC vorgestellt. Interessant sind dabei die Trainings-Ergebnisse, denn hier taucht einiges an Hardware erstmals auf bzw. skaliert mit deutlich mehr Beschleunigern, als dies bei den bisherigen Ergebnissen der Fall war. NVIDIA und Azure präsentieren Ergebnisse mit 1.344 Knoten. In seiner Cloud-Instanz setzt Azure dazu pro Knoten auf jeweils zwei Intel Xeon... [mehr]
Die MLCommons hat eine weitere Runde Ergebnisse im Bereich Datacenter-Training und HPC vorgestellt. Interessant sind dabei die Trainings-Ergebnisse, denn hier taucht einiges an Hardware erstmals auf bzw. skaliert mit deutlich mehr Beschleunigern, als dies bei den bisherigen Ergebnissen der Fall war. NVIDIA und Azure präsentieren Ergebnisse mit 1.344 Knoten. In seiner Cloud-Instanz setzt Azure dazu pro Knoten auf jeweils zwei Intel Xeon... [mehr] -
MLPerf Training 3.0: Mehr Gaudi und vor allem mehr H100
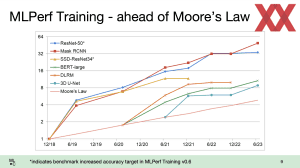 Die ML Commons haben neue Ergebnisse der MLPerf-Training-Benchmarks veröffentlicht. Im Trainingsbereich gibt es einen Versionssprung auf die Version 3.0 inklusive neuer LLM-Benchmarks. Auch die im Edge-Segment wichtigen Tiny-Benchmarks, die auf ein besonders energieeffizientes Inferencing ausgelegt sind, wurden aktualisiert. Die Benchmarksergebnisse sind für eine eventuelle Auswertung direkt bei der ML Commons verfügbar (MLPerf Training... [mehr]
Die ML Commons haben neue Ergebnisse der MLPerf-Training-Benchmarks veröffentlicht. Im Trainingsbereich gibt es einen Versionssprung auf die Version 3.0 inklusive neuer LLM-Benchmarks. Auch die im Edge-Segment wichtigen Tiny-Benchmarks, die auf ein besonders energieeffizientes Inferencing ausgelegt sind, wurden aktualisiert. Die Benchmarksergebnisse sind für eine eventuelle Auswertung direkt bei der ML Commons verfügbar (MLPerf Training... [mehr] -
MLPerf Inference 2.1: H100 mit erstem Auftritt und mehr Diversität
 Es gibt eine neue Runde unabhängiger, bzw. gegenseitig geprüfter Benchmark-Ergebnisse aus dem Server-Bereich. Genauer gesagt geht es um die Inferencing-Ergebnisse in der Version 2.1. Diese sollen eine unabhängige Beurteilung der Server-Systeme in den verschiedenen Anwendungsbereichen ermöglichen. Große Unternehmen werden natürlich weiterhin eine eigene Evaluierung vornehmen, aber in der Außendarstellung konnten die Hersteller meist nur mit... [mehr]
Es gibt eine neue Runde unabhängiger, bzw. gegenseitig geprüfter Benchmark-Ergebnisse aus dem Server-Bereich. Genauer gesagt geht es um die Inferencing-Ergebnisse in der Version 2.1. Diese sollen eine unabhängige Beurteilung der Server-Systeme in den verschiedenen Anwendungsbereichen ermöglichen. Große Unternehmen werden natürlich weiterhin eine eigene Evaluierung vornehmen, aber in der Außendarstellung konnten die Hersteller meist nur mit... [mehr] -
MLPerf Training v1.1: Unabhängiger Benchmark wird zur NVIDIA-One-Man-Show
 Bereits häufiger haben wir über die Benchmarks und Ranglisten der MLCommons berichtet, da man hier einen unabhängigen Benchmark in unterschiedlichen Kategorien aufbauen wollte, der praxisrelevante Daten zu den AI/ML-Beschleunigern der verschiedenen Hersteller liefert. Heute nun wurden die Daten zum Training in der Version 1.1 veröffentlicht. Daneben gibt es noch die Kategorien HPC, wo erst vor wenigen Wochen aktualisierte Daten... [mehr]
Bereits häufiger haben wir über die Benchmarks und Ranglisten der MLCommons berichtet, da man hier einen unabhängigen Benchmark in unterschiedlichen Kategorien aufbauen wollte, der praxisrelevante Daten zu den AI/ML-Beschleunigern der verschiedenen Hersteller liefert. Heute nun wurden die Daten zum Training in der Version 1.1 veröffentlicht. Daneben gibt es noch die Kategorien HPC, wo erst vor wenigen Wochen aktualisierte Daten... [mehr] -
MLPerf HPC: HPC-Benchmarks abseits der Top500-Liste
In dieser Woche findet die Supercomputing 2021 statt und in dessen Rahmen wurde unter anderem die aktualisierte Liste der Top500-Supercomputer vorgestellt. Für diese wurde der Linpack-Benchmark verwendet, der einzig die FP64-Rechenleistung der Systeme einzuordnen vermag. Zugegebenermaßen ist dies für viele Anwendungen noch immer die wichtigste Kennzahl für die Rechenleistung eines Supercomputers. In einem sechsmonatigen Rhythmus hat MLCommons... [mehr] -
MLPerf Training 1.0: Graphcore und Google greifen NVIDIAs Vormachtstellung an
Die MLCommons haben pünktlich zur ISC 21 die Ergebnisse des MLPerf Training in der Version 1.0 veröffentlicht. Für diese neueste Version der Benchmark-Ergebnisse wurden einige Prozesse in der Teilnahme geändert, sodass es für Unternehmen einfacher werden soll, daran teilzunehmen. So wurden die bisher verwendeten Übersetzungs-Benchmarks GNMT und Transformer aus der Wertung genommen. Auf der anderen Seite wurde mit RNNT eine... [mehr] -
MLPerf Inference 1.0 Power legt den Fokus auf die Effizienz
In all unseren Tests versuchen wir über Benchmarks und Messungen unter gleichen Bedingungen des korrekte Leistungsbild der Hardware darzustellen. Für Prozessoren, Grafikkarten, Speicher, aber auch für Lüfter und Kühler stellt sich dies noch recht einfach und nachvollziehbar dar. Schon anders sieht dies für Serveranwendungen, die weitaus komplexer und weniger einfach nachvollziehbar sein können. Auf die Spitze getrieben wird dies mit AI-, bzw... [mehr]. -
MLPerf 0.7 Inferencing zeigt NVIDIAs aktuellen Vorsprung auf
MLPerf hat sich zum Ziel gesetzt, eine bessere Vergleichbarkeit für die Bestimmung und den Vergleich von Rechenleistung im AI-, bzw. ML-Bereich herzustellen. Neben den großen Chip-Herstellern Intel und NVIDIA sind auch ARM, Google, Intel, MediaTek, Microsoft und viele anderen Unternehmen daran beteiligt und ermöglichen somit eine bessere Vergleichbarkeit der Leistung in diesem Bereich. Nachdem bereits vor einiger Zeit die Resultate... [mehr] -
NVIDIA nennt MLPerf-Leistungsdaten für den A100-Beschleuniger
In Zusammenarbeit mit MLPerf hat NVIDIA nun erste Leistungsdaten des A100-Beschleunigers auf Basis der Ampere-Architektur bzw. der GA100-GPU veröffentlicht. Vorgestellt hatte man diesen auf der GPU Technology Conference Mitte Mai. Neben der Datacenter- gibt es inzwischen auch eine PCI-Express-Variante. MLPerf soll eine Vergleichbarkeit zwischen den verschiedenen Machine-Learning-Systemen ermöglichen, denn echte Benchmarks wie wir sie von... [mehr]
