Install the app
How to install the app on iOS
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
-
Hardwareluxx führt derzeit die Hardware-Umfrage 2025 (mit Gewinnspiel) durch und bittet um eure Stimme.
Du verwendest einen veralteten Browser. Es ist möglich, dass diese oder andere Websites nicht korrekt angezeigt werden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Du solltest ein Upgrade durchführen oder einen alternativen Browser verwenden.
Plus 19 Prozent IPC-Leistung: Die Details der Zen-3-Architektur
- Ersteller HWL News Bot
- Erstellt am
Häh, np, achso ist ebenso ein Platzhalter verstehe.
Nun gut, man das dauert bis die benchmarks kommen die ich erwarte und bis es einer von euch diese testen kann ebenso. Aber so ist das halt. Bisher sind halt nur die benchmarks gekommen was mich überhaupt nicht interessiert. Ich verwende diese ganzen Software nicht, somit bringt es mir null und es sagt für mich ebenso nichts aus. Nur das halt der unwichtige sc bench im Vordergrund ist. Weil ja auch and selbst verlauten hat lassen das der Fokus auf SC ist. Also für ne kleine Minderheit sehr wichtig und das war es auch schon wieder.
Nun gut, man das dauert bis die benchmarks kommen die ich erwarte und bis es einer von euch diese testen kann ebenso. Aber so ist das halt. Bisher sind halt nur die benchmarks gekommen was mich überhaupt nicht interessiert. Ich verwende diese ganzen Software nicht, somit bringt es mir null und es sagt für mich ebenso nichts aus. Nur das halt der unwichtige sc bench im Vordergrund ist. Weil ja auch and selbst verlauten hat lassen das der Fokus auf SC ist. Also für ne kleine Minderheit sehr wichtig und das war es auch schon wieder.
Nö, nix Augenwischerei. Es besteht eben ein Unterschied zwischen Multithread Nutzung im Sinne der Verteilung von Aufgaben und im Sinne der Skalierung. Was ihr in den Foren immer wollt ist das Gleichsetzen von Multithreading mit 1a Leistungsskalierung. Aber das ist nicht ursprüngliche Ansatz der ganze Nummer. Es ging darum, mehr Aufgaben parallel durchführen zu können. Ein klassisches Beispiel dafür ist, du hast ne GUI willst ne Rechnung tätigen. Machst du das im GUI Thread, friert die GUI ein, während die Rechnung läuft, weil keine Leistung mehr über ist um sie zu refreshen. Eine Form davon ist, dass es in Summe damit schneller wird als wenn man diese Aufgaben in der gleichen Zeit eben hintereinander ausführt. Aber es ist und bleibt eben nicht die einzige Form. Wieder Beispiel GUI + Rechnung -> mach es parallel, das Rechenergebnis wird deswegen nicht zwingend eher kommen. Und die GUI wird trotzdem nur so oft gezeichnet, eben vorgesehen. Total gewinnst du also gar nix an Speed. Aber machen tun es trotzdem alleGenau das mache ich, auch direkt über RivaTuner.
Deine Definition ist ein wenig Augenwischerei in dem Fall. Ja, sie nutzen alle die Threads. Also Multithreading!
Nur sind die Threads dann zu 1-5% ausgelastet. Das mag stur per Definition Multithreading sein, wird dem Game aber nicht helfen spürbar besser zu laufen.
")
Warum das wichtig ist zu unterscheiden, ist auch einfach gesagt. Wenn du nämlich dem Prozessor pro Thread Bumms massiv zusammen kürzt, steigt in dem Fall die Auslastung. Weil das System gezwungen wird, mehr Aufgaben parallel laufen zu lassen und das auch kann, weil die Aufgaben untereinander entkoppelt sind. Das wäre aber nicht der Fall, wenn man es eben nicht multithreaded programmieren würde.
Problematisch an der Nummer ist, wenn du die Software jetzt zwingst, in ein API Limit zu laufen, weil du bspw. 720p Games testest und es auf maximale Wiederholungen ankommt, dann siehst du davon halt auch nix. Logisch, weil die Aufgaben, die parallel laufen eben schnell genug abgearbeitet werden, während andere Aufgaben in Summe eben nicht schnell genug abgearbeitet werden (und limitieren)
Der Übergang dabei ist fließend - das ist wichtig zu verstehen. Du kannst ohne dieses Limit recht viel einfach auch in Games MT Performance gegen pro Thread Performance tauschen. Aber die Messmethode, die sich dann an der pro Thread Performance richtet, kann dir das nicht aufzeigen. Unabhängig davon - zu sagen, es gäbe kein Multithreading (denn da kommen wir ja her) ist und bleibt Käse
Dann schalt halt ein paar Cores ab und du hast einen bei 100 und den Rest bei 80. Allein dass dem so ist, widerlegt doch schon deine Aussage, es würde kein MT geben?Immer mehr Games haben ausgeglichene Nutzung, klar. Aber mit dominanter Thread meine ich nicht "alle sind bei 80 und einer bei 100", sondern "einer ist bei 100, die anderen bei 0-10".
Mal davon ab, das Core bei xx% Last auch irgendwo total egal ist. Denn (vereinfacht gesagt) ein Kern ist immer bei Last oder keiner Last. Es gibt genau genommen keine Teillast. Es gibt verschiedene Einheiten in einem Kern. Und entweder die rechnen oder die rechnen gerade nicht. Etwas mehr im Detail - da drauf kommt Pipelining, die Aufgaben werden in Teilsteps gesplittet und der Prozessor sorgt intern dafür, das möglichst kein Leerlauf entsteht. So werden Aufgaben abseits eines Rechenschritts versetzt mit irgendwelchen Load, Store und sonstwedem anderen Kram verkettet um idealerweise eben keinen Leerlauf zu haben in möglichst vielen der Einheiten. Der Taskmanager und andere Software kann dir sowas aber nicht darstellen, dort wird nicht die reale Belastung der Einheiten, Pipeline oder sonstwas intern gemessen.
Du gehst hier gerade dem Taskmanager auf den Leim, der dir diesen Zustand über ein Zeitfenster sichtbar macht. Denn 50% oder 80% oder was auch immer heist einfach nur, in der Zeiteinheit x war zu 50 oder 80% der Zeit Arbeit da und im Rest war keine Arbeit da. Das heist nicht, das zu 80% die Einheiten belastet wurden.
Kannste auch wiederum selbst prüfen -> Code der voll auf die FP Units geht zeigt dir genau so eine 100% Last an, wenn er lange genug läuft wie Code der nur auf die INT Units geht. Man könnte auch zweit Threads parallel laufen lassen und FP und INT Units belasten. Es bleibt bei 100%.
Mit dem Genre hat das nichts zu tun. Woher hast du das?? Alle Games unterliegen der gleichen Limitierung. Es wird doch überall in FPS bzw. Frametimes gemessen. Es ist bumms egal ob das ein FP-Shooter ist oder ein Titel ala Anno. Die Anforderungen unterscheiden sich nur darin, dass ein Titel ala Anno viel Beikram mitbringt und gar nicht auf x-hunderte FPS hin laufen muss/soll, während das beim Shooter eher gewünscht ist. Willst du bei einem Anno aber genau so die FPS maximieren, deckelst du irgendwann oben an das API Limit. Nämlich genau dann, wenn dein Prozessor breit genug ist, dass er all die anderen Aufgaben parallel ausführen kann. Beim Shooter ist das nicht anders. Schau dir Benchmarks auf breiten TR CPUs an - da siehste genau den Umstand. Um so breiter der Prozessor, desto eher neigt der Spaß dazu, dass die Cores komplett schlafen. Die Spikes teils sind primär Windows geschuldet, was die Last von Kern zu Kern schubst. Deswegen wandert das teils über alle Kerne im Teillastbereich.Ist in dem Fall aber klar dem Genre geschuldet und FPS Spieler werden das nie bemerken. Stategie -und Simulations-Genres hingegen kämpfen da wohl bis ans Ende aller Tage, bzw. bis es zu Quanten geht.
Bis dahin ist es hart zu feiern, dass AMD hier endlich auftrumpfen kann.
Tech Enthusiast
Enthusiast
- Mitglied seit
- 01.01.2016
- Beiträge
- 3.609
- Desktop System
- PC
- Laptop
- Surface
- Details zu meinem Desktop
- Prozessor
- Ryzen 9 - 5950X
- Mainboard
- Asus Dark Hero x570
- Kühler
- Noctua NH D15
- Speicher
- 32gb - Vengeance 3200
- Grafikprozessor
- PNY RTX 4090
- Display
- 4-eckig
- SSD
- 2tb Samsung 970 Evo
- Gehäuse
- Define zu alt
- Netzteil
- Asus Thor 850W
- Betriebssystem
- Windows 10
- Webbrowser
- Chrome
- Internet
- ▼1150 MBit ▲54 MBit
Sorry @fdsonne, normal bist Du echt gut so Dinge klar und richtig zu erklären, aber das hier ist einfach Quatsch dieses Mal.
Du tust so, als würde jeder CPU Core = 1 Thread verarbeiten, wenn in Realität jeder Core hunderte und sogar tausende Threads verarbeiten kann.
Nur weil 10 Aufgaben auf 10 Kernen laufen, ist das nicht schneller, als wenn alle 10 auf einem Kern laufen, solange die 10 Aufgaben den Kern nicht überlasten.
Dem Entgegengesetzt kann aber auch eine Aufgabe schon einen kompletten Kern auslasten zu 100% und wenn die anderen Kerne auf den einen deswegen warten müssen, ist das ein Bottleneck und kann nicht durch mehr Kerne und noch so tolles MC gefixt werden, sondern nur durch mehr Leistung pro Kern.
Und genau das habe ich nicht "irgendwoher", sondern sehe es täglich im Einsatz. Nicht jede Aufgabe kann geteilt werden.
Natürlich unterscheiden sich da Genres, weil manche Genres halt keine Anforderungen haben, die einzelne Kerne überlasten können. Die laufen natürlich dann besser im Multicore, als Games die einzelne Anforderungen haben, die einen einzelnen Kern brennen lassen. Das hat nix mit API Limits und FPS zu tun, sondern mit Algorithmen, die nicht teilbar sind. Du kannst einfach nicht jede Aufgabe an x-beliebige Threads verteilen.
Ganz banales Beispiel: Addiere 1+1+1+1+1,.... und gib jedes Mal das Zwischenergebnis aus. Das kannst Du nicht an 100 Threads aufteilen, weil jeder Schritt auf dem Vorherigen aufbaut. Du kannst erst 2+1 rechnen, nachdem 1+1 durch ist und ausgegeben wurde. Und danach geht erst 3+1. Und genau solche Dinger existieren in einigen Genres nun mal häufiger als in anderen.
Du beißt Dich einfach nur an der Wörterbuchdefinition von MC fest und damit hast Du schon Recht. In der Realität hilft das aber niemandem weiter, wenn trotzdem alle drölftausend Kerne auf einen überlasteten Kern warten müssen. Beispiele dafür findest Du quasi in jedem Strategiespiel, dass ich kenne / spiele. Mir ist nicht eines bekannt, dass dieses Problem nicht hat, egal aus welchem Jahr es stammt.
Grund dafür ist auch klar: Es ist übertragen das 1+1+1+1,... Beispiel. Ein KI Spieler kann erst Aktion X berechnen, nachdem die vorherige Aktion durchgerechnet wurde, weil die vorherige Aktion die Grundlage für Aktion X ist. Analog kann man auch nicht 10 KIs simultan auf 10 Kernen Rechnen, weil sie auch untereinander abhängig sind und sonst z.B. simultan auf die selbe Aktion bestehen, die aber nur einmal möglich ist. Ergo muss das in Reihe laufen, auf einem Kern.
Was die anderen Kerne dann mit noch so tollem MC hinbekommen ist das rendern, die Assets, die Animationen.... das ist MC, natürlich. Aber das könnte auch von einem zweiten CPU Kern gemacht werden in der Zeit, die der erste für die KI braucht. Ob es nun also 2 Kerne sind, oder 32, ist irrelevant in dem Fall.
Es ist immer das schwächste Glied das Problem und bei einigen Genres ist das ein einzelner Core und wird es auch bleiben für die absehbare Zukunft.
Und genau deswegen ist dieser Schritt von AMD auch so extrem wichtig und gut.
Du tust so, als würde jeder CPU Core = 1 Thread verarbeiten, wenn in Realität jeder Core hunderte und sogar tausende Threads verarbeiten kann.
Nur weil 10 Aufgaben auf 10 Kernen laufen, ist das nicht schneller, als wenn alle 10 auf einem Kern laufen, solange die 10 Aufgaben den Kern nicht überlasten.
Dem Entgegengesetzt kann aber auch eine Aufgabe schon einen kompletten Kern auslasten zu 100% und wenn die anderen Kerne auf den einen deswegen warten müssen, ist das ein Bottleneck und kann nicht durch mehr Kerne und noch so tolles MC gefixt werden, sondern nur durch mehr Leistung pro Kern.
Und genau das habe ich nicht "irgendwoher", sondern sehe es täglich im Einsatz. Nicht jede Aufgabe kann geteilt werden.
Natürlich unterscheiden sich da Genres, weil manche Genres halt keine Anforderungen haben, die einzelne Kerne überlasten können. Die laufen natürlich dann besser im Multicore, als Games die einzelne Anforderungen haben, die einen einzelnen Kern brennen lassen. Das hat nix mit API Limits und FPS zu tun, sondern mit Algorithmen, die nicht teilbar sind. Du kannst einfach nicht jede Aufgabe an x-beliebige Threads verteilen.
Ganz banales Beispiel: Addiere 1+1+1+1+1,.... und gib jedes Mal das Zwischenergebnis aus. Das kannst Du nicht an 100 Threads aufteilen, weil jeder Schritt auf dem Vorherigen aufbaut. Du kannst erst 2+1 rechnen, nachdem 1+1 durch ist und ausgegeben wurde. Und danach geht erst 3+1. Und genau solche Dinger existieren in einigen Genres nun mal häufiger als in anderen.
Du beißt Dich einfach nur an der Wörterbuchdefinition von MC fest und damit hast Du schon Recht. In der Realität hilft das aber niemandem weiter, wenn trotzdem alle drölftausend Kerne auf einen überlasteten Kern warten müssen. Beispiele dafür findest Du quasi in jedem Strategiespiel, dass ich kenne / spiele. Mir ist nicht eines bekannt, dass dieses Problem nicht hat, egal aus welchem Jahr es stammt.
Grund dafür ist auch klar: Es ist übertragen das 1+1+1+1,... Beispiel. Ein KI Spieler kann erst Aktion X berechnen, nachdem die vorherige Aktion durchgerechnet wurde, weil die vorherige Aktion die Grundlage für Aktion X ist. Analog kann man auch nicht 10 KIs simultan auf 10 Kernen Rechnen, weil sie auch untereinander abhängig sind und sonst z.B. simultan auf die selbe Aktion bestehen, die aber nur einmal möglich ist. Ergo muss das in Reihe laufen, auf einem Kern.
Was die anderen Kerne dann mit noch so tollem MC hinbekommen ist das rendern, die Assets, die Animationen.... das ist MC, natürlich. Aber das könnte auch von einem zweiten CPU Kern gemacht werden in der Zeit, die der erste für die KI braucht. Ob es nun also 2 Kerne sind, oder 32, ist irrelevant in dem Fall.
Es ist immer das schwächste Glied das Problem und bei einigen Genres ist das ein einzelner Core und wird es auch bleiben für die absehbare Zukunft.
Und genau deswegen ist dieser Schritt von AMD auch so extrem wichtig und gut.
@fdsonne :
Wenn die Auslastugszahl egal ist,wofür gibt es denn dann im Taskmanager denn dann die Auslastungsangaben dann.Dann könnte man die ja auch gleich weglassen wenn das so egal ist.Es ist allerdings für mich ein guter indiz,wie gut die Software damit skaliert.Denn wenn ne CPU nur bei z.b 80 oder 85 % ausgelastet ist,dann zeigt es das es ein gewisses Limit die Software hat.Es bringt einem also doch was.Klar spielt es keine Rolle wie viele Einheiten angesprochen werden.Aber ich weis sehr gut,das ich z.b AVX garkeine Einheiten verwendet bzw belaste.Somit bleibt ein Teil bei meiner CPU immer brach.Das sind halt Spezial EInheiten.Die werden also bei mir niemals belastet.Durch sowas braucht dann auch die CPU nicht mehr so viel Strom.Dennoch ist durch den höheren Takt die CPU der Stromverrbauch höher.Einer hat sich also bei mir sogar gewundert,das der Ryzen 9 3950x mit 4,3 ghz stolze 218 Watt verbrät.Dann auch noch das wissen ohne AVX.Klar ist wohl,das er aufgrund des hohen Taktes so viel strom verbrät.Bei 3,5 ghz würde diese CPU wohl nur 140 Watt verbrauchen.
Achja es kommt nicht nur auf die Kerne und so an,sondern wieviele Transistoren ein Kern mit dem zweiten Thread so hat.
Also wenn z.b ein Kern 388 Millionen hat und die andere CPU dann 750 Millionen,dann ist ganz klar dieser Automatisch besser weil viel mehr Transistoren bei den einem Kern die Aufgabe berechnen.Somit kann auch einer mit zwar weniger Kernen aber dafür mit mehr Transistoren hier klar Punkten.Darum ist ja auch ein AMD 16 Kerner besser als ein 18 Kerner Intel.DIe Intels haben weniger Transistoren.Klar könnte man nun argumentieren da muss man ja auch noch den Interposer deren Transitoren und die Caches abziehen.Aber selbst dann hat AMD noch immer mehr Transitoren als Intel.
Ich dachte allerdings das je mehr Transitoren es sind,desto heißer wird die CPU werden.Dem ist allerdings nicht so,weil der Takt eine Rolle Spielt. Und ja nicht immer spielen Transistoren ne Rolle.Wenn ich die AVX Einheiten mit ner vermuteten Prozentmenge einfach gedanklich abziehen und dann durch die Kernzahl teile,dann bliebe dem Threadripper 3970x z.b 4,375 Milliarden Transstoren Pro Kern übrig,
Das heißt das erklärt auch warum dieser nicht mehr so stark im Multicore bei einigen Aufgaben skaliert.Es sind einfach zu wenig Transistoren übrig.Das kann man somit nur noch mit einem höheren Takt ausgleichen.Die Software bleibt jedoch bei der skalierung so schlecht.Es wurde halt nicht immer so Optimal Otimiert.Darum schaffen es einige CPUS auch nicht ihre Wahre Power auszufahren.Da können somit die Spiele noch so gut sein.Wenn der Untersatz nicht gut genug ist,hilft das halt eben nix mehr.
Wenn die Auslastugszahl egal ist,wofür gibt es denn dann im Taskmanager denn dann die Auslastungsangaben dann.Dann könnte man die ja auch gleich weglassen wenn das so egal ist.Es ist allerdings für mich ein guter indiz,wie gut die Software damit skaliert.Denn wenn ne CPU nur bei z.b 80 oder 85 % ausgelastet ist,dann zeigt es das es ein gewisses Limit die Software hat.Es bringt einem also doch was.Klar spielt es keine Rolle wie viele Einheiten angesprochen werden.Aber ich weis sehr gut,das ich z.b AVX garkeine Einheiten verwendet bzw belaste.Somit bleibt ein Teil bei meiner CPU immer brach.Das sind halt Spezial EInheiten.Die werden also bei mir niemals belastet.Durch sowas braucht dann auch die CPU nicht mehr so viel Strom.Dennoch ist durch den höheren Takt die CPU der Stromverrbauch höher.Einer hat sich also bei mir sogar gewundert,das der Ryzen 9 3950x mit 4,3 ghz stolze 218 Watt verbrät.Dann auch noch das wissen ohne AVX.Klar ist wohl,das er aufgrund des hohen Taktes so viel strom verbrät.Bei 3,5 ghz würde diese CPU wohl nur 140 Watt verbrauchen.
Achja es kommt nicht nur auf die Kerne und so an,sondern wieviele Transistoren ein Kern mit dem zweiten Thread so hat.
Also wenn z.b ein Kern 388 Millionen hat und die andere CPU dann 750 Millionen,dann ist ganz klar dieser Automatisch besser weil viel mehr Transistoren bei den einem Kern die Aufgabe berechnen.Somit kann auch einer mit zwar weniger Kernen aber dafür mit mehr Transistoren hier klar Punkten.Darum ist ja auch ein AMD 16 Kerner besser als ein 18 Kerner Intel.DIe Intels haben weniger Transistoren.Klar könnte man nun argumentieren da muss man ja auch noch den Interposer deren Transitoren und die Caches abziehen.Aber selbst dann hat AMD noch immer mehr Transitoren als Intel.
Ich dachte allerdings das je mehr Transitoren es sind,desto heißer wird die CPU werden.Dem ist allerdings nicht so,weil der Takt eine Rolle Spielt. Und ja nicht immer spielen Transistoren ne Rolle.Wenn ich die AVX Einheiten mit ner vermuteten Prozentmenge einfach gedanklich abziehen und dann durch die Kernzahl teile,dann bliebe dem Threadripper 3970x z.b 4,375 Milliarden Transstoren Pro Kern übrig,
Das heißt das erklärt auch warum dieser nicht mehr so stark im Multicore bei einigen Aufgaben skaliert.Es sind einfach zu wenig Transistoren übrig.Das kann man somit nur noch mit einem höheren Takt ausgleichen.Die Software bleibt jedoch bei der skalierung so schlecht.Es wurde halt nicht immer so Optimal Otimiert.Darum schaffen es einige CPUS auch nicht ihre Wahre Power auszufahren.Da können somit die Spiele noch so gut sein.Wenn der Untersatz nicht gut genug ist,hilft das halt eben nix mehr.
mr.dude
Urgestein
- Mitglied seit
- 12.04.2006
- Beiträge
- 6.420
Naja, Geekbench ist mMn seit Version 4 nicht mehr wirklich brauchbar was MT betrifft. Konnte dort immer wieder beobachten, dass meine CPU nicht wirklich voll ausgelastet wurde. Wenn ich mich richtig erinnere war das mit Version 3 noch der Fall. Vielleicht hat sich das mit Version 5 wieder gebessert, keine Ahnung. Dass man keine lineare Skalierung der Kerne erwarten kann, sollte aber klar sein. Die TDP für 5800X, 5900X und 5950X ist ja die gleiche, 105W. Das heisst die Modelle mit mehr Kernen takten dann entsprechend herunter, damit das Power Target eingehalten wird. Letztendlich heisst das ja, dass der 5950X in solchen Szenarien mindestens 50% effizienter zu Werke geht als der 5800X. Das ist schon beachtlich. Sicherlich hätte AMD die TDP den Kernen anpassen können, z.B. 8 Kerne 105W, 12 Kerne 125W, 16 Kerne 140W. Dann wäre auch die Skalierung der Performance besser. Aber das hätte eventuell Probleme mit manchen Boards verursacht. Bezüglich MT Performance hat man eh nichts von der Konkurrenz zu befürchten. Auch von Intels nächster Generation Rocket Late nicht, der mit maximal 8 Kernen sogar 2 Kerne weniger bieten wird als Comet Lake.Aber Multicore sieht die Skalierung bei Geekbench ungefähr so aus 8 Kerne ca. 10K Punkte, 12 Kerne (also 50% Kerne) machen aber nur 12,5K (also ein viertel mehr Leistung), 16 Kerne (also 100% mehr) machen 15-16k nur 50%-60%) mehr.
Zeigt mir wieder diese Sache vom CCD zu CCD - connect wie z.B R3 3300x vs R5 3600.
G
Gelöschtes Mitglied 285234
Guest
Es ist wirklich interessant zu sehen wie ein Intel Fanboy (Paddy) mit einem AMD Fanboy (mr.dude) diskutiert.Mag ja sein, dass Paddy92 den Intel Fanboy raushängen lässt, aber ihr seid auch nicht besser.
Dabei sind sie sich doch so ähnlich, nutzen die selben Argumente und biegen sich die Preise zugunsten des eigenen Weltbildes zurecht. Anschauungsunterricht für Psychologen.
Da muß schon noch was anderes klemmen. Ansonsten wäre die MC Leistung vom 5900X nicht so...äh mies. Oder sagen wir mal unerwartet niedrig.Naja, Geekbench ist mMn seit Version 4 nicht mehr wirklich brauchbar was MT betrifft. Konnte dort immer wieder beobachten, dass meine CPU nicht wirklich voll ausgelastet wurde. Wenn ich mich richtig erinnere war das mit Version 3 noch der Fall. Vielleicht hat sich das mit Version 5 wieder gebessert, keine Ahnung. Dass man keine lineare Skalierung der Kerne erwarten kann, sollte aber klar sein. Die TDP für 5800X, 5900X und 5950X ist ja die gleiche, 105W. Das heisst die Modelle mit mehr Kernen takten dann entsprechend herunter, damit das Power Target eingehalten wird. Letztendlich heisst das ja, dass der 5950X in solchen Szenarien mindestens 50% effizienter zu Werke geht als der 5800X. Das ist schon beachtlich. Sicherlich hätte AMD die TDP den Kernen anpassen können, z.B. 8 Kerne 105W, 12 Kerne 125W, 16 Kerne 140W. Dann wäre auch die Skalierung der Performance besser. Aber das hätte eventuell Probleme mit manchen Boards verursacht.
Zuletzt bearbeitet:
D
DTX xxx
Guest
Der 8700K ist seit 3 Jahren eine klasse CPU und wird es noch einige Zeit sein. Allerdings kommt ein würdiger Nachfolger. Zen 3 Ryzen 5 6C/12T. Der wird selbst in Multi Anwendungen die 8 Kerner schlecht aussehen lassen. Insbesondere die teuren 9900K/S Modelle. Da macht der Stillstand 10700K/F für 350€ keine große Hoffnung.
Nach den Benches werden viele 280€ für den 5600X als fair ansehen. Ich gehe klar davon aus, dass der R5 überzeugen wird.
Nach den Benches werden viele 280€ für den 5600X als fair ansehen. Ich gehe klar davon aus, dass der R5 überzeugen wird.
evtl. das Powerlimit des Sockels?Da muß schon noch was anderes klemmen. Ansonsten wäre die MC Leistung vom 5900X nicht so...äh mies. Oder sagen wir mal unerwartet niedrig.
Tonmann
Enthusiast
Also die Werte die ich von anderen Benches und auch realen Anwendungen in MC gesehen habe sehen sehr, sehr gut aus!Da muß schon noch was anderes klemmen. Ansonsten wäre die MC Leistung vom 5900X nicht so...äh mies. Oder sagen wir mal unerwartet niedrig.
Könnte es evtl. doch an Geekbench liegen?
Oldironsides220
Experte
- Mitglied seit
- 28.02.2018
- Beiträge
- 246
- Details zu meinem Desktop
- Prozessor
- Ryzen 7 5800X3D
- Mainboard
- MSI X570 Unify
- Kühler
- EKWB Supremacy EVO | NexXxos XT 360 | Eisstation DDC310
- Speicher
- G.Skill Trident Z (F4-4000C19D-32GTZ)
- Grafikprozessor
- Palit GTX 1080 GameRock
- Display
- Acer Predator Z301C - Modell UM.CZ1EE.001 & Iiyama 27" 2K
- SSD
- WD Black SN850 1TB; 2x Samsung 860 PRO 512 GB
- Soundkarte
- Creativ Soundblaster Omni Surround | Beyerdynamic DT 880 PRO
- Gehäuse
- LianLi O11 Dynamic (weiß)
- Netzteil
- Corsair HX850 Titanium
- Mouse
- Madcatz RAT 8+ ADV
- Betriebssystem
- Win 10 64Bit
Das denke ich...
mr.dude
Urgestein
- Mitglied seit
- 12.04.2006
- Beiträge
- 6.420
Wie gesagt, Geekbench ist als Vergleich, gerade was MT betrifft, kein gutes Tool. Da haben zu viele Faktoren Einfluss, wie RAM-Kapazität, RAM-Taktrate, Betriebssystem, Mainboard, usw. Selbst die 3900X MT Ergebnisse variieren dort extrem für Windows, von 10xxx bis 14xxx. Auf die Schnelle hab ich mal zwei einigermassen vergleichbare Setups gefunden:Da muß schon noch was anderes klemmen. Ansonsten wäre die MC Leistung vom 5900X nicht so...äh mies. Oder sagen wir mal unerwartet niedrig.
3900X: 11000 https://browser.geekbench.com/v5/cpu/4334161
5900X: 12869 https://browser.geekbench.com/v5/cpu/4247508
Das wären etwa 17% mehr für den 5900X. Dabei nutzt der auch noch etwas niedriger getakteten RAM.
Bisher sind einfach zu wenige Ergebnisse vom 5900X vorhanden. Alles auch nur mit 16 GB RAM und teils niedrigen RAM-Taktraten. Man müsste im Grunde 3900X und 5900X auf derselben Plattform testen, mit mehreren Durchläufen, und daraus dann einen Mittelwert bilden. Das wäre einigermassen aussagekräftig.
Irgendeinen ZEN2 mit nicht so guten Punkten zeigt aber nicht die Leistungsfähigkeit.
Einmal ein R9 3900X stock und oc.
Auch ein R9 3950X ist nicht so schlecht und braucht sich im MC nicht zu verstecken.
Für den 5900X und den 5950X reichts in beiden Fällen. Da muß noch mehr kommen.
Einmal ein R9 3900X stock und oc.
Auch ein R9 3950X ist nicht so schlecht und braucht sich im MC nicht zu verstecken.
Für den 5900X und den 5950X reichts in beiden Fällen. Da muß noch mehr kommen.
Anhänge
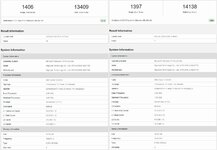
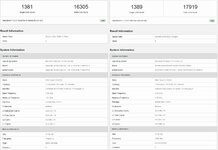
Zuletzt bearbeitet:
mr.dude
Urgestein
- Mitglied seit
- 12.04.2006
- Beiträge
- 6.420
Äpfel und Birnen. Wie ich schon schrieb, die bisherigen 5900X Setups besitzen lediglich 16 GB RAM. Du vergleichst hier aber mit Setups die 32 GB RAM besitzen. Schau dir die ersten GB5 Ergebnisse des 3900X an. Die lagen fast alle im niedrigen 11000er Bereich. Da wurde es auch erst mit der Zeit mehr. Da liegt der 5900X mit jetzt schon bis zu knapp 13000 einiges drüber. Der wird in den kommenden Wochen und Monaten sicherlich auch noch zulegen können.
Zuletzt bearbeitet:
Durch was wird denn das Ergebnis denn besser. Also automatisch wird da nix besser. Wenn also an der Software sich nichts mehr ändert dann wird es automatisch nichts an dem Ergebnis besser. Es sei denn das BIOS des mainbaords macht da soviel aus das es da noch 5-10 % durch das noch oben drauf geht. Das ist doch Wunsch denken. Zu damals war das BIOS und so noch nicht so gut ausgereift gewesen oder kam das durch die verwendete Software zustande des jeweiligen herstellers.
Also eines weiß ich sicher genau, bei meiner software wird sich genau nix mehr tuen. Es kommt also voll drauf an wie gut z. B das beta Bios des Msi x470 so sein wird. Wunder erwarte ich allerdings keine davon mehr, es sei denn Msi kann auf einmal zaubern. Mal sehen wieviel wohl das BIOS aus der CPU an leistung noch herausquetschen kann. Erwarte jedoch durch das BIOS auch nicht 10-20 % an zusätzliche leistung zu der Grund leistung der CPU oder ist sowas dann doch möglich?
Also eines weiß ich sicher genau, bei meiner software wird sich genau nix mehr tuen. Es kommt also voll drauf an wie gut z. B das beta Bios des Msi x470 so sein wird. Wunder erwarte ich allerdings keine davon mehr, es sei denn Msi kann auf einmal zaubern. Mal sehen wieviel wohl das BIOS aus der CPU an leistung noch herausquetschen kann. Erwarte jedoch durch das BIOS auch nicht 10-20 % an zusätzliche leistung zu der Grund leistung der CPU oder ist sowas dann doch möglich?
Nozomu
Legende
- Mitglied seit
- 11.03.2011
- Beiträge
- 16.062
- Desktop System
- Raptorlake
- Details zu meinem Desktop
- Prozessor
- Core i9 14900K @ 24 x 5700 MHz
- Mainboard
- ASUS PRIME Z690-P D4
- Kühler
- Noctua NH-D15 (3x NH-A15 Lüfter)
- Speicher
- 4x8GB 3200C14 MHz G.Skill Trident Z RGB (f4-3866c18d-16gtzr) (Samsung B-Die)
- Grafikprozessor
- ZOTAC GAMING GeForce RTX 4070 Twin Edge OC White Edition
- Display
- ASUS XG27UCS 27'' 3840 x 2160 160 Hz / Samsung 28" U28E850 3840 x 2160 60 Hz
- SSD
- System und mehr: Samsung 990 PRO NVMe M.2 SSD, 4 TB
- HDD
- Spiele SSD: Samsung 990 PRO NVMe M.2 SSD, 4 TB
- Soundkarte
- Extern: Asus Xonar U7 MKII Soundkarte 7.1 Surround
- Gehäuse
- EVGA DG-87 (Lüfter= Front: 3x 140+2x 200 / TOP: 1x 200 / Heck: 4x 140 GPU 1x 140 )
- Netzteil
- EVGA SuperNOVA 850 T2 TITANIUM
- Betriebssystem
- Windows 11 Pro
Chipsatz Treiber haben ebenfalls einen Einfluss auf die Leistung.
Meine Skylake-X war am Anfang auch langsamer als nach nen halben bis Jahr später.
Meine Skylake-X war am Anfang auch langsamer als nach nen halben bis Jahr später.
Das Ergebnis vom R9 3900X ist von mir und ich habe sicher noch nie 11000Punkte gehabt. Ich hab jetzt eh schon mein Ergebnis genommen, weil mein Ram nicht optimiert ist.Äpfel und Birnen. Wie ich schon schrieb, die bisherigen 5900X Setups besitzen lediglich 16 GB RAM. Du vergleichst hier aber mit Setups die 32 GB RAM besitzen. Schau dir die ersten GB5 Ergebnisse des 3900X an. Die lagen fast alle im niedrigen 11000er Bereich. Da wurde es auch erst mit der Zeit mehr. Da liegt der 5900X mit jetzt schon bis zu knapp 13000 einiges drüber. Der wird in den kommenden Wochen und Monaten sicherlich auch noch zulegen können.
Denn dann macht ein R9 3900X schon stock über 14000 Punkte.
AMD Ryzen 9 3950X zeigt sich im Geekbench 5
Es gibt ein weiteres Lebenszeichen zum Ryzen 9 3950X, der mit 16 Kernen auf dem Sockel AM4 vor allem im Umfeld der Multi-Core-Anwendungen auftrumpfen soll. Zwei Ergebnisse im Geekbench 5 lassen nun aufhorchen, denn sie ermöglichen eine weitere Einschätzung der Leistung des Prozessors. Einmal...
Die Ergebnisse von @TUM_APISAK, der ja Profi ist, sollte man nicht mit Ergebnissen von Leuten vergleichen die ihre CPU im 4. Gang fahren, weil sie nicht wissen wie man den 5. und 6. einlegt.
Hier noch ein Leak von Ihm, kurz vor Veröffentlichung des R9 3950X.
System manufacturer System Product Name - Geekbench
Benchmark results for a System manufacturer System Product Name with an AMD Ryzen 9 3950X processor.
browser.geekbench.com
Ich habe ja nicht gesagt - der 5900X ist schlecht -, sondern das ist momentan zu wenig und es muß noch was kommen.
Ist doch gut, wenn man damit rechnen kann, daß da noch was kommt.
Zuletzt bearbeitet:
D
DTX xxx
Guest
Für welche Anwendungen ist ein Geekbench wichtig?Ich habe ja nicht gesagt - der 5900X ist schlecht..
Ich gebe ehrlich gesagt auf Geekbench genauso viel wie auf Passmark und Userbenchmark. Aber hier gehts um die Vergleichbarkeit.Für welche Anwendungen ist ein Geekbench wichtig?
Besonders wenn, wie gesagt der Durchschnitt von Usern genommen und mit Ergebnissen von Profis verglichen wird.
Beim Passmark hat der R9 3900X abgeblich im SC 2731 Punkte. Das sind ~@4.3GHz für den SC, der ja beim 3900X angeblich @4.6GHz entspricht. Stock habe ich aber knapp über 2900 Punkte.
Genauso die MC Ergebnisse. Da habe ich stock mit 34602 mehr Punkte als ein R9 3900X/XT...nach deren oc Liste.
Und genau deswegen habe ich was gegen Vergleiche wo ein Leak gegen solche Durchschnittsergebnisse gestellt wird. Da ist zuviel Müll von Usern dabei, die entweder mal was getestet haben, oder einfach ihr
Sys mies eingestellt haben. Das zieht den Durchschnitt nach unten und zeigt nicht wieviel Leistung eine CPU wirklich hat.
Anhänge
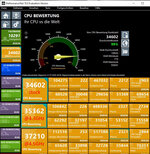
Zuletzt bearbeitet:
D
DTX xxx
Guest
Das bedeutet doch, die Ergebnisse sind nicht vergleichbar. Warum vergleichst du dann die Ergebnisse und beurteilst diese?Beim Passmark hat der R9 3900X abgeblich im SC 2731 Punkte. Das entspricht ~@4.3GHz. Stock habe ich aber knapp über 2900 Punkte
Wenn man sich diese Masse an Benches anschaut sehe ich nur eines. Seit dem 8700K (Okt 2017) bis zum heutigen (Okt. 2020) 10900K, also 3 Jahre, hat sich im Single bei Intel nichts getan. Nur das etwas mehr Takt, kann einen 10900K 5,3 GHz vor einen 8700K 4,7GHz sehen. Im Multi wurde die Punktzahl um 1000 Punkte pro mehr an Kern erhöht.
Bei AMD. Innerhalb der Zen 2 CPUs entscheidet der Takt im Single und Pro Kern mehr bekommt man 1000 Punkte mehr im Multi.
Ich denke nicht, dass es entscheidend mehr Punkte im Multi zwischen einem 3600X und einem 5600X geben wird und den entsprechenden Gegenstücke mit mehr Kerne.
Allerdings wird im Gegensatz zu Intel die Single Leistung steigen und bei der Multi Leistung Intel noch weiter zurück fallen.
Doch die Idee hinter deinen Vergleich habe ich noch nicht verstanden. Auf was soll sich dein, da muss mehr kommen beziehen?
Hab ich was anderes gesagt? Die Durchschnittswerte aus solchen Listen sind fürn Popo, wie Du an meinen Ergebnissen siehst. Zuviel Müll dabei der die eigentliche Leistung der CPUDas bedeutet doch, die Ergebnisse sind nicht vergleichbar. Warum vergleichst du dann die Ergebnisse und beurteilst diese?
nicht wiederspiegelt. Deswegen kann man das nicht so stehen lassen.
-Schau dir die ersten GB5 Ergebnisse des 3900X an. Die lagen fast alle im niedrigen 11000er Bereich.-
Da die Leistung eines R9 3900X höher ist.
Na, wenn alle bisher geleakten MC Ergebnisse, die ja nicht von Hinz und Kunz kommen, eines 5900X niedriger sind als meines, oder auch von anderen Usern hier im Forum ist, dann kann das nicht das EndeDoch die Idee hinter deinen Vergleich habe ich noch nicht verstanden. Auf was soll sich dein, da muss mehr kommen beziehen?
sein...und darum muß und wird da noch mehr kommen.
Was hat jetzt Intel genau damit zu tun?
Anhänge

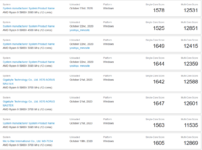
Felix the Cat
Der mit SeLecT tanzt
- Mitglied seit
- 09.06.2004
- Beiträge
- 24.936
- Details zu meinem Desktop
- Prozessor
- AMD Ryzen 7 9800X3D | watercooled by cuplex kryos NEXT RGBpx
- Mainboard
- ASUS ROG CROSSHAIR X870E HERO
- Kühler
- Custom Wakü | MO-RA3 420 + MO-RA3 360
- Speicher
- 48GB TeamGroup T-Force Xtreem ARGB DDR5-8000 CL 38
- Grafikprozessor
- MSI RTX 4090 SUPRIM X 24G | watercooled by Corsair XG7
- Display
- Dell AW3225QF (4K OLED)
- SSD
- Samsung 990 Pro 2TB | Corsair MP600 2TB | Mushkin Vortex 2TB
- Gehäuse
- Phanteks NV9
- Netzteil
- ASUS ROG Thor Platinum II 1000W
- Keyboard
- RAZER BlackWidow V3
- Mouse
- RAZER Basilisk V3
- Betriebssystem
- Windows 11
Der einzig wahre Benchmark ist SuperPi 1M. 
Eigentlich brauche ich keine neue CPU, aber denke der 5900X wird dennoch bestellt.")
Eigentlich brauche ich keine neue CPU, aber denke der 5900X wird dennoch bestellt.
Ok verstehe, wie sieht es denn aus wenn der Chipsatz Treiber auch so bleiben würde weil ja z. B Windows 7 keinen neueres annehmen kann weil es auf dem Stand von 2019 geblieben ist. Die Leistung dennoch mit Windows 10 etwas besser. In dem Fall wird da garnix mehr besser werden. Wie sieht es denn mit bios update alleine aus. Hat das denn aus Wirkung bei der CPU Leistung oder spielt da nur die Stabilität ne Rolle dann?Chipsatz Treiber haben ebenfalls einen Einfluss auf die Leistung.
Meine Skylake-X war am Anfang auch langsamer als nach nen halben bis Jahr später.
Nozomu
Legende
- Mitglied seit
- 11.03.2011
- Beiträge
- 16.062
- Desktop System
- Raptorlake
- Details zu meinem Desktop
- Prozessor
- Core i9 14900K @ 24 x 5700 MHz
- Mainboard
- ASUS PRIME Z690-P D4
- Kühler
- Noctua NH-D15 (3x NH-A15 Lüfter)
- Speicher
- 4x8GB 3200C14 MHz G.Skill Trident Z RGB (f4-3866c18d-16gtzr) (Samsung B-Die)
- Grafikprozessor
- ZOTAC GAMING GeForce RTX 4070 Twin Edge OC White Edition
- Display
- ASUS XG27UCS 27'' 3840 x 2160 160 Hz / Samsung 28" U28E850 3840 x 2160 60 Hz
- SSD
- System und mehr: Samsung 990 PRO NVMe M.2 SSD, 4 TB
- HDD
- Spiele SSD: Samsung 990 PRO NVMe M.2 SSD, 4 TB
- Soundkarte
- Extern: Asus Xonar U7 MKII Soundkarte 7.1 Surround
- Gehäuse
- EVGA DG-87 (Lüfter= Front: 3x 140+2x 200 / TOP: 1x 200 / Heck: 4x 140 GPU 1x 140 )
- Netzteil
- EVGA SuperNOVA 850 T2 TITANIUM
- Betriebssystem
- Windows 11 Pro
Wenn das Windows keine Updates mehr erhält dann kann sich auch nichts bessern. Logisch oder?
Das MB BIOS kann durch bessere Stabilität natürlich die Leistung besser ausfahren aber glaube, das meiste kommt eher von Windows+Chipsatz Treiber. Aber wenn keine unterstützt werden, sieht es schlecht aus dass sich da was tut.
Das MB BIOS kann durch bessere Stabilität natürlich die Leistung besser ausfahren aber glaube, das meiste kommt eher von Windows+Chipsatz Treiber. Aber wenn keine unterstützt werden, sieht es schlecht aus dass sich da was tut.
Nun dann wird sich wohl am Ende ein Gleichstand herausstellen. Denn bei Windows 7 ist dieses Tool etwas besser. Wenn nun dann ein neuer Chipsatz für Windows 10 kommen wird,dann steigt da etwa die Leistung. Dann heißt es gleich gut. Denn wenn ich da dann z. B einen ryzen 9 5950x anstatt 3950x nehme, dann steigt da ja auch dank der Hardware Seite etwa die Leistung an. Aber halt nix von der Software. Da hier ja windows 7 etwas vorne ist, würde es am Ende auf ein unentschieden herauslaufen. Das darum weil es an der Software liegt die sehr eigen ist. Zudem muss erst mal bewiesen werden wieviel mehr Leistung am Ende auch wirklich ankommt. Denn durch das nicht verwenden von avx und so , sinkt halt auch die Leistungssteigerung etwas. Da hilft auch keine ipc Steigerung wenn die meisten Einheiten nicht belastet werden.
mr.dude
Urgestein
- Mitglied seit
- 12.04.2006
- Beiträge
- 6.420
@DaHell63
Ich glaube wir reden aneinander vorbei. Du sagst die GB5 Scores für den 5900X müssten besser sein. Es sagt doch niemand was gegenteiliges. Nur bringt es nichts unterschiedliche Setups miteinander zu vergleichen. Die ersten GB5 Scores des 3900X waren auch noch vergleichsweise niedrig. Warum sollte das beim 5900X anders sein? Die Zeit wird zeigen, was möglich ist. Lass die Prozessoren doch erstmal verfügbar sein. Dauert ja nicht mehr lange.
Ich glaube wir reden aneinander vorbei. Du sagst die GB5 Scores für den 5900X müssten besser sein. Es sagt doch niemand was gegenteiliges. Nur bringt es nichts unterschiedliche Setups miteinander zu vergleichen. Die ersten GB5 Scores des 3900X waren auch noch vergleichsweise niedrig. Warum sollte das beim 5900X anders sein? Die Zeit wird zeigen, was möglich ist. Lass die Prozessoren doch erstmal verfügbar sein. Dauert ja nicht mehr lange.
Beitrag automatisch zusammengeführt:
Würde mich sogar mal interessieren. Was schafft denn ein 10900K @ stock? Bei NBC steht was von 7,2 Sekunden. Ich schaffe mit meinem 3600 @ stock (~4,15-4,2 GHz Turbo) und DDR4-3200 knapp 10 Sekunden. Wenn ich das mal auf die 4,8 GHz und +19% IPC des 5900X hochrechne, dürfte es da ganz schön eng für den 10900K werden.Der einzig wahre Benchmark ist SuperPi 1M.
Zuletzt bearbeitet:
Ähnliche Themen
- Antworten
- 3
- Aufrufe
- 1K
- Antworten
- 12
- Aufrufe
- 1K
- Antworten
- 36
- Aufrufe
- 7K
- Antworten
- 269
- Aufrufe
- 15K
- Antworten
- 88
- Aufrufe
- 6K