
Werbung
Das wohl wichtigste Merkmal der neuen GPU-Generationen von AMD und NVIDIA sind die Fertigung in 14 bzw. 16 nm FinFET. Nach langem Stillstand konnte sich AMD und NVIDIA mit den Auftragsfertigern im Zusammenspiel mit der eigenen Architektur auf einen neuen Fertigungsprozess einigen. Dies war in der Vergangenheit wohl nicht immer ganz einfach und so verblieben sowohl AMD als auch NVIDIA bei TSMC im 28-nm-Verfahren. Mit dem Sprung auf 14 nm und FinFET werden sich erhebliche Vorteile hinsichtlich der Leistungsaufnahme ergeben. Der Test der GeForce GTX 1080 Founders Edition hat bereits bewiesen, dass die neue Fertigung bei der Effizienz einen großen Unterschied machen kann. Das Potenzial konnte NVIDIA in jedem Fall sehr gut nutzen.

Selbst bei gleichbleibender Architektur ist ein Wechsel der Fertigung nicht immer ganz einfach. Nicht ohne Grund wendet Intel daher das Tick-Tock-Verfahren an, bei dem sich ein Wechsel der Fertigungsgröße und der Architektur abwechseln. Somit geht man dem Risiko einer Kollision zweier Problembereiche aus dem Weg. NVIDIA stolperte bei der Fermi-Architektur über den Wechsel der Fertigung und die gleichzeitige Einführung einer neuen Architektur. Das sogenannte Fabric, also ein Bereich der GPU, der aus vielen Verbindungen besteht, die sich teilweise auch kreuzen, wurde bei den hohen Frequenzen bei denen die GPUs betrieben werden, zu einem fast unlösbaren Problem. Für AMD dürfte sich der Wechsel auf die Polaris-Architektur und der gleichzeitige Shrink in der Fertigung ebenfalls nicht ganz unproblematisch erwiesen haben. Den Tape-Out sollen die beiden Chips Polaris 10 und Polaris 11 im November bzw. Dezember 2015 geschafft haben. Nun, etwa acht Monate später erscheinen die finalen Karten auf dem Markt. Erst kürzlich hat AMD durchblicken lassen, dass auch Vega 10, der High-End-Chip der neuen Generation, seinen Tape Out geschafft hat.
Während NVIDIA seine GPUs auch in 16 nm FinFET weiterhin bei TSMC fertigen lässt, scheint TSMC für die kommende GPU-Generation von AMD zunächst einmal keine Rolle mehr zu spielen. Stattdessen hat GlobalFoundries bereits durchblicken lassen, dass die neuen GPUs in einer Fabrik in den USA, genauer gesagt im Bundesstaat New York gefertigt werden sollen. Auf dem Polaris-Tech-Day zeigte sich GlobalFoundries dann auch auf der Bühne. Ob Vega auch bei GlobalFoundries gefertigt werden wird, bleibt abzuwarten.

Bereits mehrfach wurde nun angeführt, dass die Effizienz bzw. eine geringere Leistungsaufnahme ein Hauptfokus für die Polaris-Architektur war. AMD verweist dazu auf die Möglichkeit, durch die kleinere Fertigungsgröße mehr und mehr Transistoren auf gleicher bzw. kleinerer Fläche unterzubringen. Durch die kleinere Strukturen treten aber vermehrt Probleme innerhalb der GPU auf (zum Beispiel Leckströme), die der theoretischen Verdopplung der Effizienz entgegenwirken.
Bereits seit einigen Jahren werden daher neue Techniken entwickelt, diesen negativen Effekten entgegenzuwirken. So werden moderne GPUs längst nicht mehr mit einer einheitlichen Betriebsspannung innerhalb der einzelnen Komponenten betrieben. Sogenannte Multi Voltage Islands trennen die Bereiche unterschiedlicher Spannung ab. Diese benötigen dann natürlich wieder eigene Spannungscontroller, was einen zusätzlichen Aufwand bedeutet. Über diese Maßnahmen können bestimmte Bereiche der GPU auch mit unterschiedlichen Taktraten betrieben oder sogar komplett abgeschaltet werden. Über solche Maßnahmen lässt sich zwar die Gesamtleistungsaufnahme reduzieren und die Effizienz erhöhen, allerdings hilft dies nicht direkt eine Mehrleistung aus der Architektur zu entwickeln.
Intel ist Vorreiter bei der Entwicklung der ersten Architekturen mit FinFETs. Dabei handelt es sich um eine 3D-Struktur eines ansonsten planaren Transistors. Source, Drain und Gate heben sich vom flachen Substrat ab und erlauben eine bessere Kontrolle des Stromflusses im Transistor.
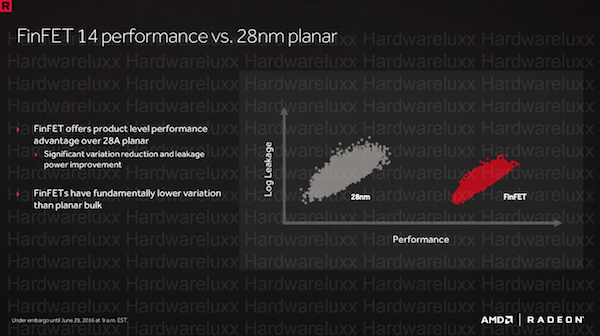
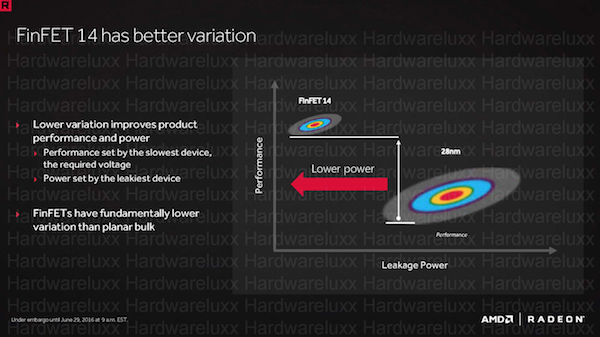
Was anfänglich nicht logisch erscheint, macht den Vorteil der FinFETs gegenüber den planaren Transistoren deutlich. In der Fertigung streuen diese weitaus weniger. Diese geringere Variation macht es letztendlich erst möglich, dass die Ansteuerung der einzelnen Bereiche oder gar Transistoren selbst deutlich effizienter erfolgen kann.
Fertigung in 14 nm FinFET
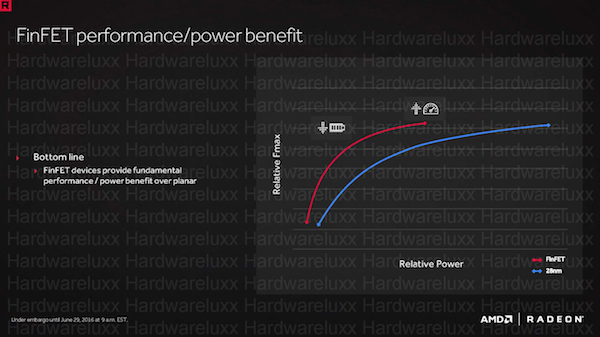
Somit will AMD durch die FinFET-Fertigung in zwei Bereichen profitieren: Durch die geringere Leistungsaufnahme und die potenziell höhere Leistung, was letztendlich zur Steigerung der Effizienz um den Faktor 2,5 führen soll.

Neben den reinen Verbesserungen bei der Effizienz kann die kleinere Fertigung aber auch zu Vorteilen führen, die nicht direkt auf den ersten Blick bewusst sind. Dazu gehört unter anderem die Möglichkeit für kleinere PCBs, mit weniger aufwendiger Strom- und Spannungsversorgung. Hinzu kommt ein kleineres GPU-Package, was auch wiederum Platz auf dem PCB einspart.
Auf einen weiteren Effekt sind wir dabei noch gar nicht eingegangen, denn zumindest die kleinere Polaris-11-GPU kann deutlich flacher gefertigt werden. So misst das GPU-Package bei Bonaire 0,29 x 0,29 Zoll (7,37 mm), während es bei Polaris 11 nur noch 0,245 x 0,245 Zoll (6,22 mm) sein sollen. Viel wichtiger aber ist offenbar die Dicke des Chips und diese soll von 1,9 mm (Bonaire) auf 1,5 mm (Polaris 11) reduziert worden sein. Möglich wird dies durch weniger Layer im Package und außerdem wird der eigentliche Chip angeschliffen, in dem Schichten auf dem Wafer nach der Belichtung abgetragen werden.
[h3]Adaptive Clocking[/h3]
Genau wie NVIDIA wird AMD im Zusammenhang mit der kleineren Fertigung nicht müde zu betonen, dass dies eine besondere Herausforderung an die Spannungsversorgung des Chips stellt.
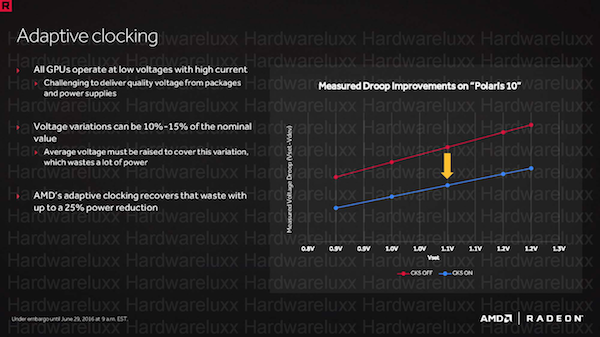
Wenn die Spannungen durch die kleinere Fertigungsgröße reduziert werden können, müssen gleichzeitig dennoch recht starke Ströme durch die Strom- und Spannungsversorgung verarbeitet werden. Im Normalfall reichen die Schwankungen in der Spannungsversorgung bis in einen Bereich von 10 bis 15 % hinein. Bei 1 V Betriebsspannung müssen also bereits bis zu 1,15 V geliefert werden, damit die Mindestspannung in jedem Fall gehalten werden kann. Diese Überversorgung stellt aber zugleich auch einen erheblichen Mehrverbrauch dar, der theoretisch nicht notwendig ist. Das Adaptive Clocking soll diese Überversorgung zumindest teilweise überflüssig machen und 25 % des Mehrverbrauchs einsparen.
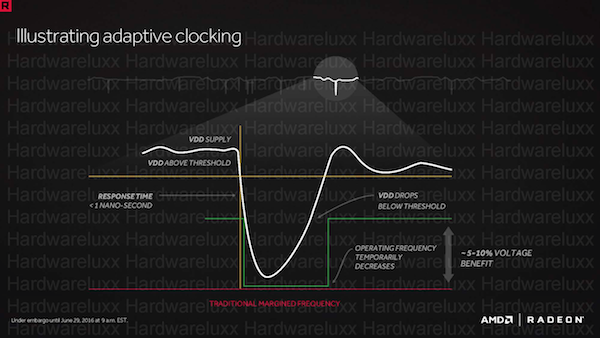
Was bei Schwankungen in der Spannungsversorgung passiert ist folgendes: Während der Takt ohne das Adaptive Clocking nur auf einem Mindestniveau verbleiben kann, wird er mit Adaptive Clocking im Nanosekundenbereich angepasst und entsprechend erhöht, wenn die Spannung höher liegt, als dies eigentlich notwendig wäre. Die Betriebsspannung (VDD) fällt alle paar tausend Taktungen in dieser Form an und in eben diesem Bereich muss auch der GPU-Takt dann reduziert werden. Letztendlich aber wird die zur Verfügung stehende Spannung besser genutzt bzw. in einen höheren Takt umgesetzt.
[h3]Adaptive Voltage & Frequency Scaling (AVFS)[/h3]
Neben der Spannungsversorgung bzw. der dynamischen Anpassung des GPU-Taktes an diese hat AMD aber auch noch einige weitere Funktionen mit der Polaris-Architektur eingeführt. Dazu gehört unter anderem das Adaptive Voltage & Frequency Scaling oder kurz AVFS.

AVFS beschreibt eine Methodik, bei der nicht mehr nur Spannung und Temperatur über Messschaltungen und Sensoren in der GPU selbst ermittelt werden, sondern auch der anliegende Takt. Üblicherweise werden GPUs mit einer 2-3 prozentigen Sicherheit hinsichtlich des Taktes betrieben, um die Alterungsprozesse in den GPUs selbst mit abzudecken. Diese Sicherheitsreserve wird mit dem AVFS nicht mehr benötigt, da sich die GPU über feiner einzustellende P-States und eine verbesserte Überwachung in gewisser Weise selbst überwacht und die Betriebsparameter eigenständig anpasst.
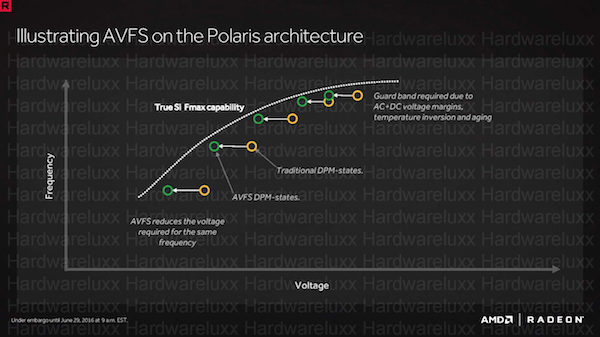
Dabei ist der Takt noch immer die Vorgabe, die Spannung wird aber dementsprechend angepasst und muss nicht mehr höher liegen, als dies eigentlich notwendig ist. Das Adaptive Clocking versucht also ständig den höchstmöglichen Takt zu erreichen (wobei es hier natürlich Vorgaben für den maximalen Takt des Adaptive Clocking gibt), während das AVFS die Betriebsspannung bei erreichen dieses Taktes in gewissem Rahmen wieder anpassen kann. Damit möchte AMD eine möglichst hohe Leistung und eine gleichzeitige Langlebigkeit der Hardware unter einen Hut bringen.
[h3]Boot Time Calibration (BTC) und Multi-Bit-Flip-Flops (MBFF)[/h3]
Eine dritte wichtige Komponente in diesem Bereich ist die Boot Time Calibration (BTC). Diese Technik wird von AMD auch schon bei den APUs der 7. Generation namens Bristol Ridge eingesetzt und zeigt sehr schön auf, wie die Entwicklung von APUs und GPUs bei AMD zusammen vorangetrieben werden kann.

Auch bei der Boot Time Calibration wird Versorgung der GPU verbessert, in dem zu bestimmten Zuständen höhere Spannungen erlaubt werden. Eine Rolle spielt dabei auch der Reliability Tracker, aber auch die Toleranzen der VRMs wird mit einbezogen. Ziel von BTC ist eine Reduzierung der Leistungsaufnahme dort wo es möglich ist, aber ebenso eine aggressivere Ansteuerung in den unterschiedlichen P-States.

Noch einmal geht AMD auf das Altern von Chips im Allgemeinen ein. Insgesamt sollen die eben vorgestellten Technologien aber dazu führen, dass die Chips nicht nur sparsamer, sondern dort, wo die Leistung benötigt wird, auch schneller werden.

Chipfläche und Leistungsaufnahme lässt sich aber nicht nur durch die eben genannten Techniken einsparen, sondern auch durch Änderungen im Design bestimmter Strukturen. AMD verwendet nun sogenannten Multi-Bit-Flip-Flops (MBFF), in denen kleinere solcher Strukturen zu größeren zusammengefasst werden, was aber wiederum Chipfläche und damit Leistung einspart. In der Polaris-10-GPU spricht AMD von 21 Millionen solcher Flip-Flops, die in etwa 15 % der gesamten Leistungsaufnahme des Chips (11,1 W bei 85 W Gesamtleistungsaufnahme des Chips) verbrauchen. Durch diese Maßnahme will AMD aber 4-5 % der Gesamtleistungsaufnahme des Chips eingespart haben.
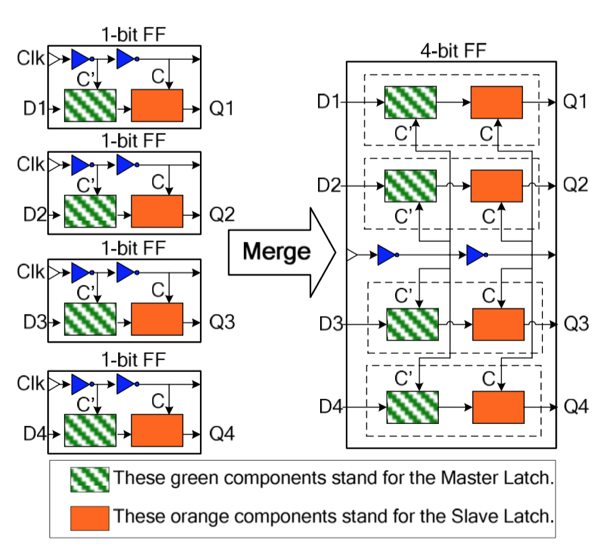
Fertigung in 14 nm FinFET
In einem Papier (PDF) haben sich chinesische Forscher mit dem Einsparungen von MBFF-Schaltungen befasst. Darin wird vor allem auf die Einsparungen in der Chipfläche eingegangen, die durch das Zusammenlegen erreicht wird.
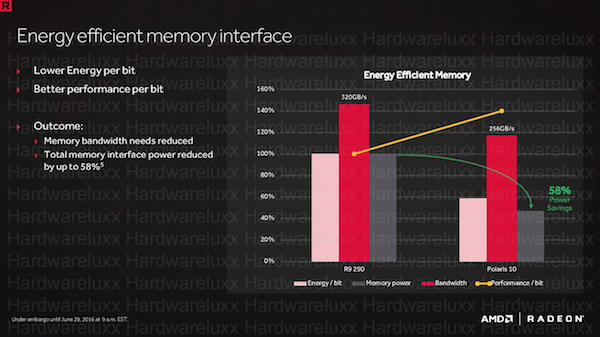
Beim Verbrauch bzw. der Effizienz hatte AMD auch das Speicherinterface im Blick. Durch die Delta Color Compression und die bessere Zusammenarbeit mit dem L2-Cache und den Registern kann AMD die Leistung des Speicherinterfaces trotz reduzierter Speicherbandbreite erhöhen. Zusammen mit den Speicherchips aber kann AMD auch die Leistungsaufnahme dieser Komponenten um bis zu 58 % reduzieren, was sich natürlich auf die Effizienz der gesamten Grafikkarte positiv auswirkt.

Für die Polaris-Architektur spricht AMD von einem um den Faktor 1,7 verbesserten Performance/Watt-Verhältnis durch die Fertigung in 14 nm. Hinzu kommen die Optimierungen in der Architektur selbst, die einen Faktor von zu 2,8 beitragen sollen. So kommt AMD auf gigantische Verbesserungen in den theoretischen Zahlen, die sich in dieser Form in der Praxis aber kaum zeigen werden.
[h3]GlobalFoundries[/h3]
Im Rahmen des Polaris-Tech-Day sprach auch GlobalFoundries über die Herausforderungen bei der Fertigung der Polaris-GPUs. Dabei verfolgten AMD und GlobalFoundries einen ähnlichen Ansatz wie NVIDIA und TSMC in ihrer Zusammenarbeit. Fertigung und Architektur müssen mit den immer kleineren Fertigungen auch immer besser aufeinander angepasst werden.
Die hier verwendete Methodik wird von GlobalFoundries als Design Technology Co-Optimization (DTCO) genannt. Dabei handelt es sich um ein Verfahren, bei dem in mehreren Schritten in der Fertigung zwischen der Optimierung der Fertigung und der GPU-Architektur hin und her gewechselt wird. Dabei werden die Anforderungen immer wieder mit den Ergebnissen der Fertigung verglichen und entsprechend Veränderungen vorgenommen. Dabei muss auch immer wieder in Betracht gezogen werden, an welchem Ende nun Veränderungen notwendig sind – an der Fertigungstechnologie selbst oder aber der Architektur.
Über Monate hinweg wurde dazu immer wieder eine Verkleinerung der Fläche in diesen Schritten vorgenommen. Die Fertigung in 14 nm FinFET hat dabei zur Folge, dass immer größere Steuerströme fließen, die Schaltvorgänge schneller werden, geringere Spannungen notwendig sind und die Leckströme reduziert werden. All dies sind natürlich Effekte, die durchaus gewollt sind.
Laut GlobalFoundries konnte die Leistung bei gleichem Takt um 55 % verbessert werden, während die Leistungsaufnahme bei gleichem Takt um 65 % reduziert werden konnte.