
Werbung
Zunächst möchten wir einen Blick in die Vergangenheit werfen, der durchaus interessant ist und im Vergleich zur aktuellen Entwicklung die riesigen Schritte aufzeigt, die inzwischen gemacht wurden. So sprechen wir in den Jahren 2001 und 2002 noch von Strukturbreiten von 180 bzw. 150 nm. Allerdings sind die RV100 und R300 auch ein riesiger Schritt bei der Leistung der GPUs, denn nicht nur die Chipgröße hat sich trotz kleinerer Fertigung fast verdoppelt, auch die architektonischen Merkmale wie 30 zu 110 Millionen Transistoren oder 1 zu 8 Pixelshader sind ein Hinweis darauf, welches Leistungsplus damals erreicht wurde.
Mit der Polaris-Architektur möchte AMD ähnliche Ziele erreichen, will die Architektur als solches aber nicht als alleiniges Merkmal dieser Generation sehen, sondern fasst unter diesem Namen zahlreiche Neuentwicklungen in den verschiedenen Bereichen zusammen. Dazu gehören die Anbindung an Displays, Multimedia-Funktionen, Caches, Speichercontroller und das Powermanagement.

Mit der Veröffentlichung der ersten Generation der GCN-Architektur (Graphic Core Next) handelte sich AMD aber nicht nur einen Sprung bei der Leistung ein, vor allem kämpfte man zu Beginn mit der Leistungsaufnahme der Radeon R9 290X und Radeon R9 290 als schnellste Vertreter dieser ersten Iteration. Über die Jahre hat AMD aber an verschiedenen Stellschrauben gedreht und ist mit Tonga und Fiji inzwischen auf einem Stand angelangt, der zumindest erkennen lässt, was diese GPU-Architektur prinzipiell zu leisten im Stande ist.
Die Polaris-Architektur soll sich aber grundlegender unterscheiden als dies bei den vorherigen Entwicklungsschritten der Fall war. Hier kommen dann auch einige Schlagworte wie Primitive Discard Accelerator, Hardware Scheduler oder Instruction Pre-Fetch ins Spiel, deren grundsätzliche Funktionsweise sich zwar erläutern lassen – ohne den dazugehörigen Hintergrund der Integration in die neue Architektur macht dies jedoch noch keinen Sinn. Anders sieht es mit der verbesserten Shader-Effizienz aus, die als klares Ziel hinter der Entwicklung der Polaris-Architektur eine höhere Effizienz der gesamten GPU hat: Eine Speicherkomprimierung. NVIDIA verwendet diese Delta-Farbkompression bereits seit der ersten Maxwell-Generation und ist daher nicht zwingend auf besonders breite Speichercontroller angewiesen. AMD hat mit dem High Bandwidth Memory der aktuellen Fiji-GPUs das vermeintliche Limit der Speicherbandbreite weitestgehend auflösen können, profitiert aber von einer weiteren Komprimierung hinsichtlich der Effizienz aber sicherlich ebenso. Dies wird vor allem dann eine Rolle spielen, wenn noch nicht der HBM zum Einsatz kommt, denn dieser wird sicherlich auch 2016 den High-End-GPUs vorenthalten bleiben.

Mit den ersten Polaris-Grafikkarten stellt AMD zwei unterschiedliche Ausbaustufen vor: Polaris 10 und Polaris 11. Polaris 10 kommt auf der Radeon RX 480 und Radeon RX 470 zum Einsatz. Bei der Radeon RX 480 kommt der Vollausbau der GPU zum Einsatz. Dieser sieht einen Graphics Command Processor vor, der zusammen mit den zwei Hardware Schedulern (HWS) und den vier Asynchronous Compute Engines (ACE) die Aufteilung und Zuteilung der Rechenaufgaben übernimmt. In 36 Compute Units (CUs) sind die 2.304 Shadereinheiten organisiert und somit sind pro CU 64 Shadereinheiten vorhanden (36 x 64). Hinzu kommen 4 Geometry Prozessoren und ein Pixel Output von 32 Pixel pro Takt. Weiterhin vorhanden sind 114 Textunreinheiten, 2 MB an L2-Cache, 576 32 Bit Load/Store Units und ein 256 Bit breites Speicherinterface.
Auch die Radeon RX 470 verwendet die Polaris-10-GPU, allerdings in reduzierter Form. So sind hier nur 32 CUs vorhanden und somit kommt die Karte auf 2.048 Shadereinheiten. Das Speicherinterface ist zwar weiterhin 256 Bit breit, allerdings bietet AMD hier nur einen Speicherausbau von 4 GB. Der Speicher wird mit einem Speichertakt von 1.750 MHz betrieben. Die typische Leistungsaufnahme wird mit 110 W angegeben, wovon 85 W auf den Chip selbst rfallen.
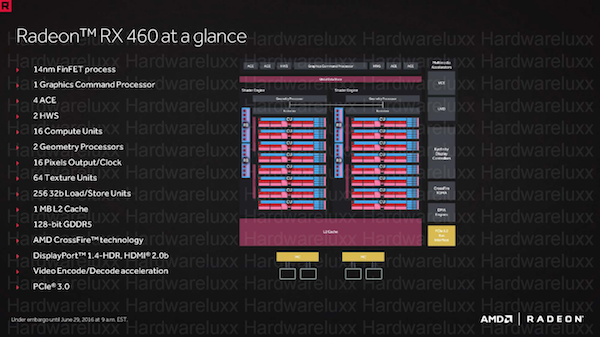
Für die Radeon RX 460 sieht AMD die Polaris-11-GPU vor. Hier sind 14 CUs vorgesehen, sodass die Karte auf 896 Shadereinheiten kommt. 64 Textureinheiten und ein 128 Bit breites Speicherinterface gehören ebenfalls zur Ausstattung. Der L2-Cache ist mit 1 MB im Vergleich zur Polaris-10-GPU auf die Hälfte reduziert. Ebenso verhält es sich auch mit 256 32 Bit Load/Store Units. Die 2 oder 4 GB großen GDDR5-Speicher arbeiten mit einem Takt von 1.750 MHz. Die Speicherbandbreite liegt demzufolge bei 112 GB/s. Die Leistungsaufnahme soll nur 75 W betragen und davon fallen 48 W auf den Chip.
Neben der reinen Architektur hat AMD aber auch noch einige Technologien entwickelt, auf die wir nun genauer eingehen werden.
[h3]Primitive Discard Accelerator[/h3]
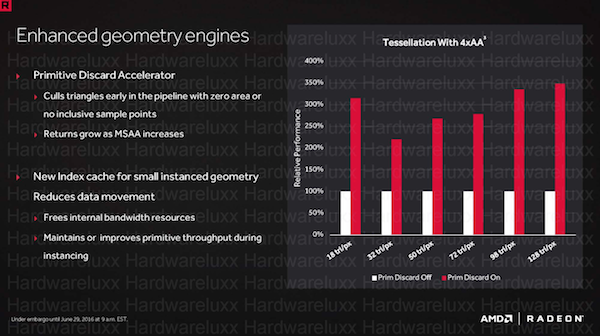
Der Primitive Discard Accelerator soll eine "Über-Tessellation" verhindern. Damit spielt AMD unter anderem auf einige GameWorks-Techniken an, die Tessellation nutzen, dabei aber die Vorteile der NVIDIA-GPU bzw. Architektur in dieser Hinsicht nutzen, AMD damit aber einige Schwierigkeiten hat. Oftmals sind die Effekte ab einem bestimmten Tessellation-Level nicht mehr sichtbar und kosten schlichtweg nur noch Leistung.
Beim Primitive Discard Accelerator handelt es sich um einen Filter in der Rendering-Pipeline, der diese überschüssigen Berechnungen erkennt und herausfiltert. Die freiwerdende Rechenleistung wird stattdessen auf ein MSAA geworfen. Für eine höhere Shader-Effizienz verwendet AMD auch einen neuen Index-Cache für Geometry-Instances, der die Daten länger vorhält. Damit müssen diese Daten nicht mehr so häufig zwischen den Caches und dem Grafikspeicher hin und her geschrieben werden und interne Bandbreite lässt sich reduzieren.
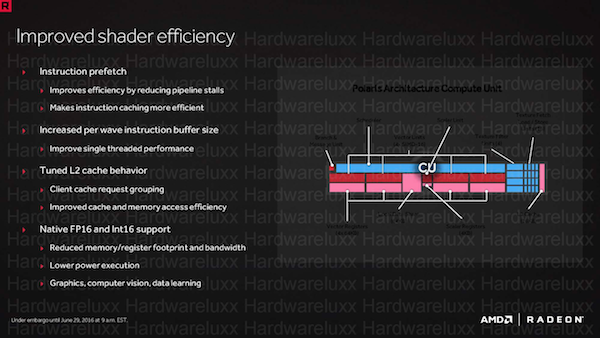
Ein weiterer Punkt um die Effizienz der Architektur zu erhöhen, ist ein verbesserter Instruction Prefetch. Dieser soll dazu führen, dass die Render Pipeline effektiver gefüllt ist und weniger Leerlauf zu verkraften hat. Dazu wurden Caches und Buffer vergrößert oder besser angesprochen. Dabei spielt der L2-Cache eine besonders wichtige Rolle, dessen Zugriffe beschleunigt werden konnten und der effektiver mit dem Grafikspeicher zusammenarbeiten soll.
Die GCN-Architektur der 4. Generation bekommt auch eine native FP16- und Int16-Unterstützung spendiert. Dabei handelt es sich um ein natives 16 Bit Register und 16 Bit Mapping. Mit dieser Maßnahme will AMD den Verbrauch im Grafikspeicher und den Registern reduzieren, da die FP16-Berechnungen nicht mehr FP32-Datensätze belegen. FP16-Berechnungen sind bei Grafik-, Foto- und Videoanwendungen und vor allem beim Deep Learning wichtig.
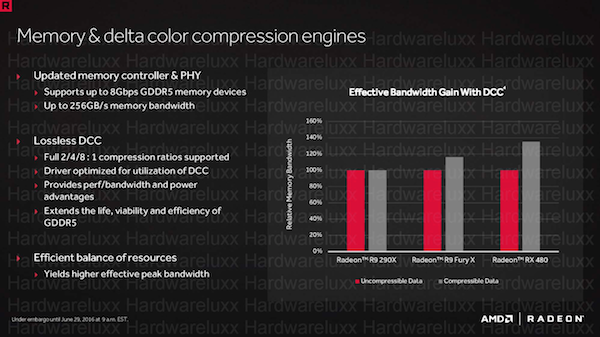
Der neue Speichercontroller der Polaris-GPUs unterstützt GDDR5-Speicher mit einer Taktrate von bis zu 2.000 MHz. Damit wird eine Speicherbandbreite von 256 GB/s erreicht. Im Vergleich zur Radeon R9 380, wenn man diese denn als Vorgänger sehen will, konnte AMD die Speicherbandbreite als um etwa 50 Prozent erhöhen.
Weitaus wichtiger ist aber das Thema Komprimierung der Daten im Speicher. Wie NVIDIA auch, bietet AMD nun neue Verhältnisse bei der Komprimierung der im Speicher befindlichen Daten. Dies ist besonders dann wichtig, wenn nur ein relativ schmales Speicherinterface zum Einsatz kommt. Das nur 256 Bit breite Speicherinterface wirkt im Vergleich zu den 512 Bit der Hawaii-GPUs oder 4.096 Bit der ersten Karten mit HBM bzw. HBM2 von AMD und NVIDIA recht schmal. AMD will das recht schmale Speicherinterface mit der Delta Color Compression (DCC) zumindest zu einem gewissen Grad kompensieren. Eine Delta-Farbkompression hat sich inzwischen bei GPUs von AMD und NVIDIA seit einigen Generationen durchgesetzt. Bei NVIDIA handelt es sich um die 4. Generation eines solchen Kompressionsverfahrens. AMD verwendet diese bereits mit der Tonga-GPU der Radeon R9 285. Erst kürzlich sprach AMD noch einmal über die Delta-Farbkompression, wie sie in der GCN-Architektur implementiert ist. Wichtig dabei ist, dass es sich um ein verlustloses Kompressionsverfahren handelt. Es gehen also keine Daten verloren und Entwickler können sich auf das Verfahren verlassen, ohne speziell darauf angepasst zu entwickeln.
Bei der DCC wird nur der Basispixelwert gespeichert und für die umliegenden Pixel in einer 8x8-Matrix nur noch der Unterschied (das Delta) gespeichert. Da das Delta ein deutlich kleinerer Wert ist, kann dieser schneller gespeichert werden und benötigt auch weniger Platz im Speicher. Es müssen also weniger Daten in den VRAM geschrieben und daraus gelesen werden. Komprimiert werden kann aber auch der einzelne Farbwert, sodass auch hier Speicherplatz oder besser Speicherbandbreite eingespart werden kann. Ein Beispiel für die Kompression ist ein vollständiges Schwarz und Weiß, deren Wert üblicherweise als {1.0, 0.0, 0.0, 0.0} oder {0.0, 1.0, 1.0, 1.0} im Speicher abgelegt wird. In einem einfachen Verfahren reichen aber auch die Werte 0.0 oder 1.0 aus, um dies eindeutig zu beschreiben.
Zu den bereits bekannten Kompressionsverhältnissen 2:1 und 1:4 kommt nun noch ein weiteres hinzu, welches mit 8:1 arbeitet und die Einsparung im Speicher noch einmal deutlich verbessert. AMD spricht von einer Leistungssteigerung um 38 % bei der Verwendung der neuen Verfahren. Natürlich sind das rein theoretische Werte, die sich aufgrund der Komprimierung ergeben. Es ist auch schwierig den Einfluss der Delta-Farbkompression zu testen, da das Verfahren in der Hardware selbst durchgeführt wird und nur durch AMD im Treiber ausgeschaltet werden kann. Wir müssen uns also auf die von AMD gemachten Benchmarks verlassen.

Auch wenn die Speicherbandbreite von 384 oder 320 GB/s auf 256 GB/s zusammengeschmolzen ist, will AMD neben der verbesserten Delta Color Compression auch noch über den doppelt so großen Cache eine erhebliche Leistungssteigerung um Bereich des Speichers und dessen Effizienz erreicht haben. Die Größe des Caches ist aber nur ein Punkt, denn auch das Schreiben und Lesen von Daten aus diesem Cache sowie die Zuteilung der verschiedenen Speicher mit den dazugehörigen Daten wurde verbessert. Diese Maßnahmen haben auch die Energieeffizienz des kompletten Speichersystems erhöht und wirken sich zudem positiv auf die DCC aus.
[h3]Asynchronous Compute[/h3]
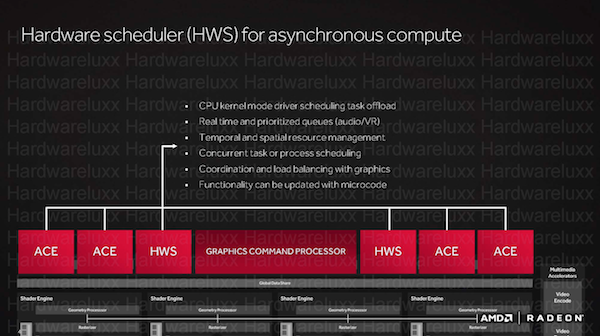
Das Vorhandensein von mehreren tausend Shaderprozessoren bietet ein enormes Leistungspotenzial, macht es den Hard- und Softwareentwicklern aber auch schwierig diese tausenden von Recheneinheiten möglichst effizient mit Rechenaufgaben zu versorgen. Weitere Komplexität bekommt das Thema, wenn neben den für eine Grafikkarte klassischen Graphics-Berechnungen auch noch solche im Bereich das Computings hinzukommen. Diese Berechnungen lassen sich nicht so ohne weiteres mischen und gemeinsam ausführen.
Die sogenannten Asynchronous Shader sollen die Art und Weise wie Engine, Treiber und Hardware miteinander sprechen und die Aufgaben verteilen, verbessern. Mit dem Launch der ersten Grafikkarten auf Basis der "Hawaii"-GPU sprach AMD aber noch von Verbesserungen beim GPU-Computing für die asynchrone Compute Engines. Jede GPU mit GCN-Architektur verfügt aber diese speziellen Hardware-Einheiten. Was damals noch als ein reines Compute-Feature angesehen wurde, soll nun DirectX 12 bei Spielen auf die Sprünge helfen.
Bei den Betrachtungen einer GPU-Architektur erwähnen wir auch immer die einzelnen Funktionsblöcke, deren Funktionsweise und Verwendungszweck. Dabei zeigt sich, dass viele dieser Funktionseinheiten unabhängig voneinander arbeiten können, aufgrund des Rendering-Prozesses aber nicht dazu in der Lage sind, sondern meist linear nur eine sogenannte Queue abgearbeiten. Dieses schrittweise Abarbeiten versuchen die in allen Architekturen vorhandenen Scheduler zu optimieren, in dem sie die Aufgaben möglichst gleichmäßig verteilen, dies gelingt allerdings nur bis zu einem gewissen Grad.

Mit DirectX 12 bekommen die Entwickler deutlich mehr Kontrolle über die Recheneinheiten und können anfallende Aufgaben besser verteilen. Allerdings gibt es dennoch einige Vorgaben durch die APIs. Moderne Spiele-Engines erlauben dazu eine Aufteilung in vordefinierte Queues, die unabhängig voneinander abgearbeitet werden können. In diesem Beispiel werden die Aufgaben in eine Grafik-, Compute- und Copy-Queu verteilt. Die API, hier DirectX 12, verteilt die Queues auf die zur Verfügung stehenden Ressourcen der GPU.
Was im Ansatz einfach klingt, ist in der Praxis aber weitaus komplizierter, denn auch diese verteilten Queues müssen den freien Ressourcen der GPU zugeteilt werden. AMD erklärt einen Rendering-Prozess anhand eines Beispiels aus dem Autoverkehr. Die Kreuzung und Zusammenführung zweier Fahrspuren auf eine mithilfe einer Ampel entspricht dabei der zu bewältigenden Aufgabe. Die Ampel ist dabei der Scheduler, der entscheiden muss, wann welcher Prozess in die Rendering-Pipeline eingeführt wird. Alle Schritte besitzen dabei die gleiche Priorität. Das Warten auf freie Ressourcen sowie das Umschalten benötigen so Zeit, die nicht sinnvoll genutzt wird.
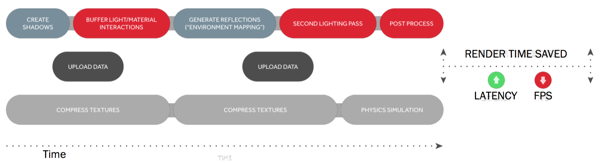
Eine Möglichkeit diesen Prozess zu verbessern, sind die Pre-Emptions. Dabei werden einige Aufgaben priorisiert. Wieder am Beispiel des Autoverkehrs wird die blaue Queue angehalten, der höher priorisierte Prozess kann dann in den Rendering Prozess eingefügt werden. Allerdings findet auch hier ein Umschalten zwischen den verschiedenen Queues statt und auch die Effizienz wird nicht wesentlich erhöht.
Bei AMD kommen nun die asynchronen Compute Engines (ACE) ins Spiel. Diese mehrfachen Command Queues können gleichzeitig abgearbeitet und daher effizienter in die Rendering-Pipelines zusammengeführt werden. Damit das Beispiel des Autoverkehrs funktioniert, muss man vielleicht noch einfügen, dass es sich um einen getakteten Autoverkehr handelt, bei dem die Fahrzeuge einer bestimmten Reihenfolge und bestimmten Abständen folgen. Arbeiten die Command Queues alle mit dem gleichen Takt, kommt es eventuell zu Kollisionen. Die ACEs sollen dies verhindern, in dem sie die Commands unabhängig von einem Takt in die Queue einfügen. So lassen sich freie Lücken und damit brachliegendes Leistungspotenzial besser nutzen. Weiterhin möglich ist aber auch die Priorisierung bestimmter Prozesse.
[h3]Quick Response Queue[/h3]
Die Quick Response Queue (QRQ) ist ein Bestandteil der Asynchronous Shaders bzw. kann darauf zugreifen. QRQ wurde von AMD erstmals vor etwa einem Jahr erwähnt – auch damals schon im Zusammenhang mit den Asynchronous Shaders. Die Quick Response Queue arbeitet Hand in Hand mit Asynchronous Timewarp, dazu werden wir später noch eine Meldung veröffentlichen. Bestimmte Rechenaufgaben sollten gerade im Zusammenspiel mit VR-Headsets priorisiert behandelt werden. Eben diese werden in die Quick Response Queue eingebracht.
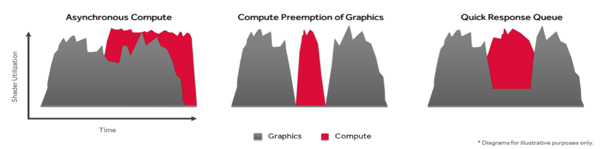
In einem Beispiel zeigt AMD die Nutzung der Shader bei einfacher Pre-Emption. Hier werden im Wechsel Graphics- und Compute-Prozesse durchgeführt, je nachdem in welcher Reihenfolge sie in die Warteschlange gebracht wurden. Die Gesamtdauer der Rechenprozesse ist durch eine ineffektive Nutzung aber höher. Schon etwas anders sieht dies bei Verwendung der Asynchronous Shaders aus. Dabei können asynchron zueinander verschiedene Rechenprozesse ausgeführt werden. Dies verkürzt die Gesamtzeit für beide Berechnungen zwar deutlich, doch können bestimmte und eventuell wichtige Rechenaufgaben nicht schneller ausgeführt werden, sondern benötigen wegen der gleichzeitigen Nutzung der Shader deutlich länger.
Asynchronous Shaders im Zusammenspiel mit Quick Response Queue sorgt dann dafür, dass wichtige Prozesse priorisiert behandelt werden. Dazu werden die Rechenaufgaben hin zum wichtigen Prozess verlagert. Die Gesamtdauer für beide Rechenaufgaben steigt damit zwar wieder leicht, allerdings werden die wichtigen Prozesse extrem schnell ausgeführt und können als Ausgabe bereits ausgeliefert werden.