@ Diablo. Ich wollte damit beweisen das der Bulldozer bei richtiger Software, besser sein kann, und dadurch auch die bessere CPU sein kann.
Sorry aber wenn du jetzt mit dem Teuren 1366 6 Kern Xeon E-5 Argumentierst, kann ich auch mit Server Sockel AMD CPU,s Argumentieren.
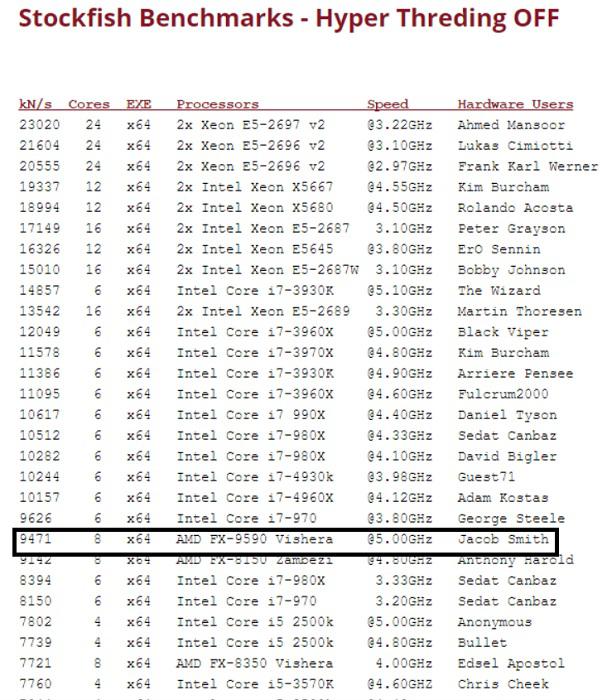
Ein Nehalem @ 4,1 ghz erreicht 9000 Punkte
Wenn ein 4 Kern i7 mit 4,1 ghz Stolze 9000 punkte schaft, dann würde dein E mit 2 kernen mehr also + 4500 machen. = 13500 Punkte. Abzügllich der Taktfrequenz dann etwas um die 11000-12000 Punkte.
Also so viel wie schon ein 4 Moduler von AMD schaft.
Und wenn wir mal in die Benchmarks gucken, schaft der 6 Kern Intel Core i7-980X @4.33GHz 10000 Punkte.
Zur errinerung. AMD liegt beim gleichen Takt mit dem Aller ersten Buggy FX8 schon bei deutlich mehr Punkten.
Ein AMD Server 8 Moduler würde dann Theoretisch 24000-26000 punkte schaffen.
Hast du das mitbedacht ?
Also für mich ist die aussage (Bulldozer war seiner Zeit vorraus) Definitiv Korrekt.
Ja die CPU war nicht wirklich brauchbar damals für den Desktop, weil die meiste software noch mit 1-2 Kernen gearbeitet hat.
Doch gerade in dem Kontext, seiner zeit vorraus, und unter betrachtung der Power bei vollbelastung, sieht man doch, das AMD mit weniger mitteln und Problemen doch eine CPU hatte, mit der sie Intel schlagen konnten.
------------------------------------
Bei der richtigen Software ist hier der entscheidende Punkt. Bei den FX konnte man schon eine kurze Zeit nach Release viele (integer) Kerne, oder sagen wir lieber Threads zu kleinem Geld kaufen. Wenn man nun also Software nutzt die gut mit jedem Kern bzw. Thread skaliert und mit der FX Architektur gut zurecht kommt ist sogar heute ein FX kein Fehlkauf und für das Geld ganz gut.
Mir gehts doch nicht um den 0815 User der damit Supreme Commander 1 Zockt welches auf einem Kern läuft und sogar einen 10 ghz Skylake zum einbrechen bewegen würde.
Mir geht es um einen Technologie vergleich unter der vorraussetzung der vollbelastung.
Natürlich kaufe ich mir keinen FX8 wenn ich keinen benötige. Daher hab ich mir 2011 auch keinen FX8 gekauft, sondern habe einen 4 Threader genommen.
Doch heute würde ich liebend gerne einen FX8 in 14nm mit 30% mehr IPC kaufen. Da meine Spiele 7 kerne auslasten (Armored Warfare und demnächst Star Citizen laut den entwicklern sogar alle 8).
Star Citizen kommt leider erst irgendwann final raus und bis dahin kann sich noch einiges ändern. In Sachen Optimierungen glaube ich daß ein i5 oder i7 mit 4 Kernen und HT die Basis sein wird auf was hin optimiert wird. Aus wirtschaftlichen Gründen will man kaum Kunden mit solchen Configs ausschließen. Größere CPUs mit mehr Kernen oder Threads werden in dem Spiel wohl trotzdem mehr Leistung bringen können, was auch gut ist.
Also, die entwickler entwickeln es nicht auf 4 Kerne + HT. Sie legen keinen wert auf i5 und i7 so wie ich das gelesen habe.
Ihnen ist wirtschaftlichkeit egal, denn sie wollen ein Spiel für die Hardware der Zukunft Programmieren.
Daher werden Zen 8 Kern käufer es quasi am besten haben, denn jeder Thread soll beansprucht werden laut den Plänen der entwickler.
Die Arbeiten an einer Extremen lastverteilung an vielen Threads auch schon ohne DX12/Vulcan. Und DX12/Vulcan kommt dann auch noch.
Letzte Optimierung ging schon in die Richtung.
We then looked at our JobManger, which is responsible to distribute all this work over the CPU cores. It turned out that we could massively improve our thread communication and improve our load-balancing. This means we utilize more CPU cores in parallel while reducing the latency of those operations.
") (da doch eher OT, mal im Spoiler verpackt)
(da doch eher OT, mal im Spoiler verpackt)