
Werbung
Das Vorhandensein von mehreren tausend Shaderprozessoren bietet ein enormes Leistungspotenzial, macht es den Hard- und Softwareentwicklern aber auch schwierig diese tausenden von Recheneinheiten möglichst effizient mit Rechenaufgaben zu versorgen. Weitere Komplexität bekommt das Thema, wenn neben den für eine Grafikkarte klassischen Graphics-Berechnungen auch noch solche im Bereich das Computings hinzukommen. Diese Berechnungen lassen sich nicht so ohne weiteres mischen und gemeinsam ausführen.
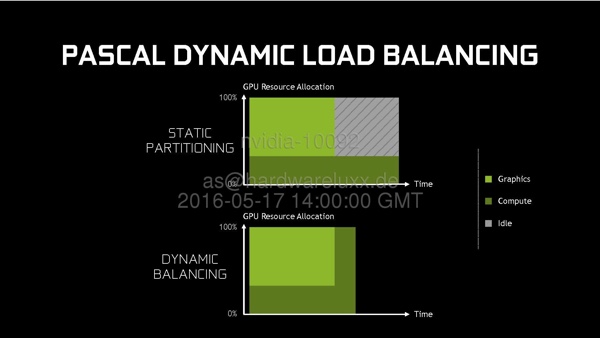
Das asynchrone Computing wird in Zukunft eine immer wichtigere Rolle spielen. AMD hat mit den Asynchronous Shaders eine dedizierte Hardware entwickelt, die Bestandteil der Graphics-Core-Next-Architektur ist. Der Vorsprung, den AMD in einigen DirectX-12-Spielen hat, lässt sich zumindest teilweise auf das Vorhandensein der Asyncronous Shaders zurückführen. Ashes of the Singularity ist ein gutes Beispiel dafür. NVIDIA führt mit der Pascal-Architektur ein neues dynamisches Load Balancing ein. Von Vorteil ist das dynamische Load Balancing vor allem bei Prozessen und Berechnungen, die zwar zur gleichen Zeit starten, deren Rechenaufwand aber unterschiedlich hoch ist. Die statische Partitionierung ist im Vergleich zum dynamischen Load Balacing deutlich weniger effektiv und hat eine geringere Auslastung der Recheneinheiten zur Folge.
Preemption
Nicht immer ist es sinnvoll einen Prozess oder eine Berechnung vollständig auszuführen. Preemption heißt hier das Stichwort und beschreibt übersetzt ein präemptives Multitasking. Dabei wird jeder Prozess nach einer bestimmten Abarbeitungszeit unterbrochen, egal ob er vollständig beendet wurde oder nicht. Sogenannte Time Slices sind dabei global festgeschriebene Zeitspannen, in die eine Berechnung unterteilt werden kann. Ist der Prozess unterbrochen, also inaktiv, können die Daten aus den Registern und den Caches der GPU in den Grafikspeicher verschoben werden. Erhält der entsprechende Prozess wieder eine Prozesszuteilung, so setzt er seine Arbeit an der Stelle fort, an der er zuvor abgebrochen wurde.
Nun ist es besonders wichtig eine Unterbrechung zu einem beliebigen Zeitpunkt durchzuführen, um möglichst flexibel zu sein. Je beliebiger bzw. feinkörniger dieser Zeitraum gewählt werden kann, desto besser. Bei der Graphics Preemption werden die Berechnungen aus dem Command Pushbuffer entnommen. Dabei handelt es sich üblicherweise um Milliarden von Dreiecken, die wiederum aus unterschiedlich vielen Pixeln bestehen. Die in der Pascal-Architektur implementierte Graphics Preemption kann nun pixelgenau ausgeführt werden, bei der Maxwell-Architektur ist dies nur bis auf Triangle-Ebene möglich. Aus der Graphics Pipeline kann ein Prozess auf den Pixel genau (X- und Y-Koordinate) gestoppt und wieder gestartet werden. Feinkörniger war dies bisher nicht möglich.


Preemption in der Pascal-Architektur
Für Compute-Prozesse liegen die Rechenaufgaben ebenfalls in einem Command Pushbuffer vor und werden dort durch Grids in unterschiedliche Workloads bzw. Threads unterteilt. Ein Abbrechen und Fortsetzen ist bei Compute Preemption auf Threadlevel möglich. Die Kombination aus beiden Methoden sorgt für ein gesamten Preemption im Bereich von 100 µs in Spielen.
Besonders wichtig ist das Preemption bei VR-Anwendungen, denn hier ist die Hardware darauf ausgelegt auf die ms genau die entsprechenden Frames auszugeben. Einen Frame alle 11 ms (90 Frames pro Sekunde) auszugeben ist für High-End-Hardware bei der Auflösung von VR-Brillen eigentlich kein Problem mehr, allerdings steigen die Anforderungen der VR-Hardware in Zukunft immer weiter.